AutoBench-V:一个专为 大型视觉语言模型基准测试而设计的全自动框架
2024-10-29,由美国圣母大学、MBZUAI和KAUST联合创建了AutoBench-V,意义在于提供了一个自动化的框架,能够根据模型能力的特定方面对大型视觉语言模型(LVLMs)进行基准测试,从而减少人为成本,提高评估的灵活性和效率。
数据集地址:AUTOBENCH-V|视觉语言模型数据集|模型评估数据集
一、研究背景:
随着大型视觉语言模型(LVLMs)的发展,它们在整合视觉和语言信息方面的能力越来越强,使得多种复杂的应用和任务得以实现。然而,评估这些模型的性能面临着重大挑战,因为传统的评估基准需要大量的人力成本来构建,并且一旦建成就缺乏灵活性。
目前遇到困难和挑战
1、评估基准的构建需要大量的人力成本,且一旦建成难以更新和调整。
2、LVLMs的评估缺乏灵活性,无法支持按需评估不同能力方面。
3、自动评估的研究在文本模态上有所探索,但在视觉模态上的研究还远远不够。
数据集地址:AUTOBENCH-V|视觉语言模型数据集|模型评估数据集
二、让我们一起来看一下AutoBench-V
AutoBench-V是一个自动化框架,能够根据用户需求对大型视觉语言模型进行定制化的基准测试。
通过接收评估能力的需求,利用文本到图像模型生成相关的图像样本,并使用LVLMs来协调视觉问答(VQA)任务,从而高效、灵活地完成评估过程。
AutoBench-V构建 :
包含四个模块:用户导向的方面生成、指导性描述生成、自我验证的图像生成和测试用例生成与评估。
它通过层次化方面生成来确保评估方面的多样性和可靠性,并使用自我验证机制来确保生成的图像与描述一致。
AutoBench-V特点:
能够自动化地生成图像和问题,减少人为参与,提高评估的效率和客观性。它还能够根据不同的评估需求生成不同难度级别的问题,从而全面评估LVLMs的能力。
用户可以通过指定评估目标,AutoBench-V将自动生成相关的图像描述和问题,然后利用LVLMs生成回答并评估其性能。
基准测试 :
通过AutoBench-V对七个流行的LVLMs进行了广泛的评估,结果表明,随着任务难度的增加,模型的性能下降,且不同模型之间的性能差异扩大。这些结果揭示了LVLMs在抽象概念理解上的强项和在具体视觉推理任务上的不足。
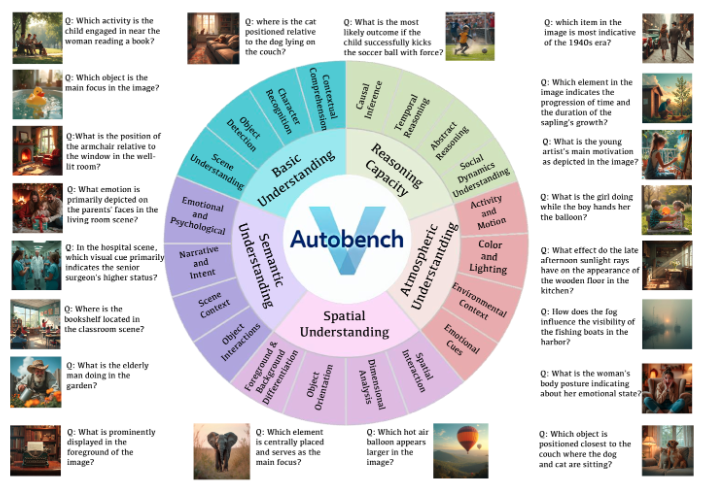
AutoBench-V 支持的五个关键评估维度, 以及它们细粒度的子方面,并附有问题和图像以帮助理解。

AutoBench-V 流程概述,说明自动评估过程。它从用户 input intake 开始,然后是 aspect 生成,然后是生成相应的图像和问题,最后输出 LVLMs 的评估分数。

AutoBench-V 框架的全面概述

图像示例对应于不同难度级别的不同用户输入。
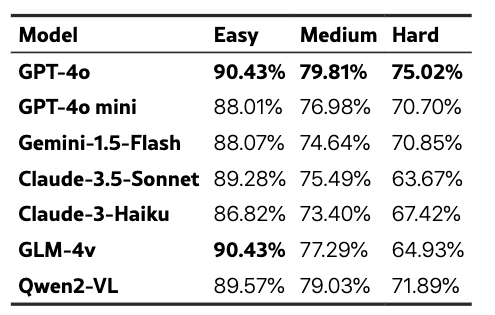
所有模型在不同难度级别的平均性能(准确性)
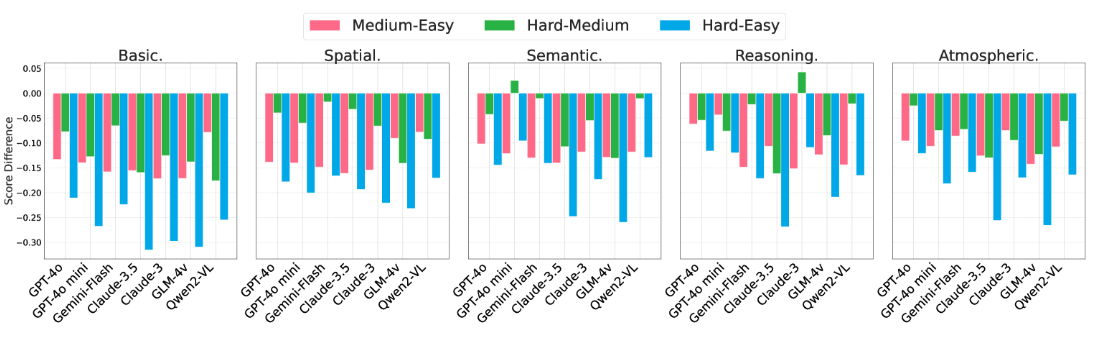
在不同的用户输入中对模型从易到难的变体进行评分。随着任务难度的增加,模型之间的性能差异变得更加明显。
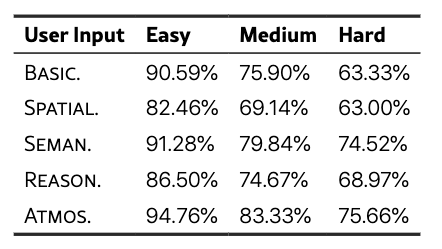
不同难度级别下各种用户输入的平均准确率。
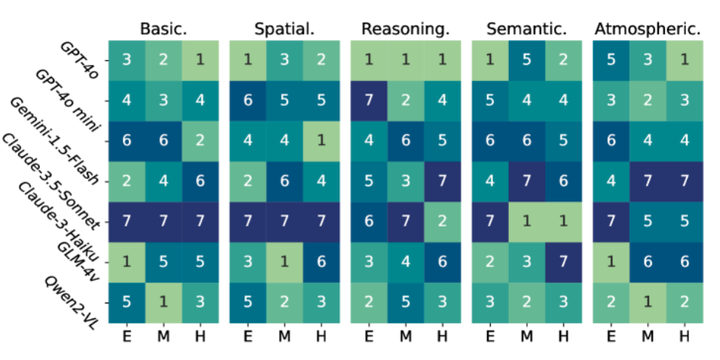
模型性能排名给出了不同难度级别的 5 个用户输入。
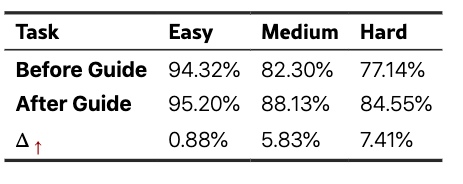
引导式描述生成的对齐率。
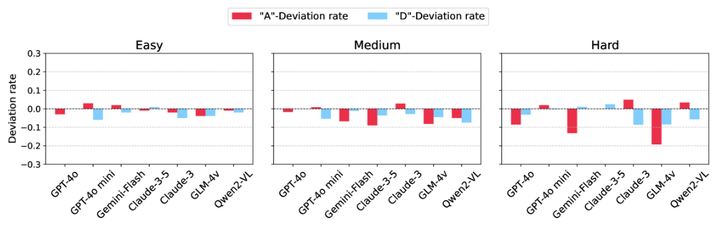
位置偏差条件下答案分布的比较。A 或 D 的正确答案与 A、B、C、D 的正确答案均匀分布。
三、展望AutoBench-V的应用场景:
比如,你是大学里的一个研究团队负责人,你们正在研究一个大型视觉语言模型,这个模型需要能够理解复杂的科学图表和相关的技术描述。这个任务不仅要求模型识别图表中的数据和图形,还要理解这些视觉信息如何与技术文本相互关联。
一般情况下你得自己找到或制作一系列基因表达的热图,然后编写问题,比如“哪个基因在实验中表达量最高?”并提供参考答案。测试模型后,你得手动检查模型的回答是否正确,并统计准确率。
有了AutoBench-V,那可就不一样了
你只需告诉AutoBench-V:“嘿,我想测试一下模型对‘基因表达数据’的理解。”然后AutoBench-V就会自动生成一系列基因表达的热图和问题,比如:“这个热图中,哪些基因在不同条件下表达量有显著差异?”
模型看了热图,回答说:“基因X在条件A下的表达量是最高的。”AutoBench-V就能自动检查答案对不对,然后告诉你模型做得怎么样。
这样不仅省时省力,还提高了评估的客观性和准确性。这样你的研究团队就可以更专注于模型的优化和研究的深入,而不是被繁琐的测试工作所拖累了。