FRAMES数据集:由谷歌和哈佛大学 联合创建一个综合评估数据集,目的测试检索增强生成系统在事实性、检索准确性和推理方面的能力
2024-09-19, 由Google 和 Harvard University 联合发布的FRAMES,一个综合评估数据集,目的评估 LLMs 在统一框架中跨多个文档检索和推理的能力。
数据集地址:frames-benchmark|RAG系统数据集|多跳推理数据集
一、背景:
大型语言模型 (LLMs) 在各种认知任务中表现出显著的性能改进。一个新兴的应用程序正在使用 LLMs 来增强检索增强生成 功能。这些系统需要 LLMs 来理解用户查询、检索相关信息并合成连贯且准确的响应。鉴于此类系统在现实世界中的部署越来越多,综合评估变得至关重要。
目前遇到的困难和挑战:
1. 评估分散:现有的评估通常孤立地评估RAG系统的各个组成部分,缺乏一个统一的框架来测试这些系统的整体性能。
2. 缺乏综合性:缺少一个能够同时挑战模型在事实检索、跨多个约束的推理和准确综合信息等能力上的评估方法。
数据集地址:frames-benchmark|RAG系统数据集|多跳推理数据集
二、让我们一起看一下FRAMES
数据集:
FRAMES(Factuality, Retrieval, And reasoning MEasurement Set),一个高质量的评估数据集,旨在测试大型语言模型(LLMs)在提供事实性回答、评估检索能力以及评估生成最终答案所需的推理能力方面的性能。
FRAMES包含824个测试样本,通过人工标注生成,要求问题需要从多个维基百科文章中整合信息。
数据集特点:
数据集覆盖了多种主题和推理类型,每个问题需要2-15篇维基百科文章来回答,问题涵盖不同的主题,包括历史、体育、科学、动物、健康等。并且包含了多种推理类型,如数值推理、表格推理、多重约束、时间推理和后处理。
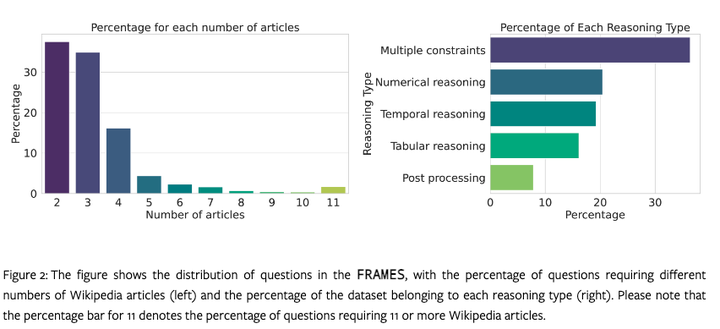
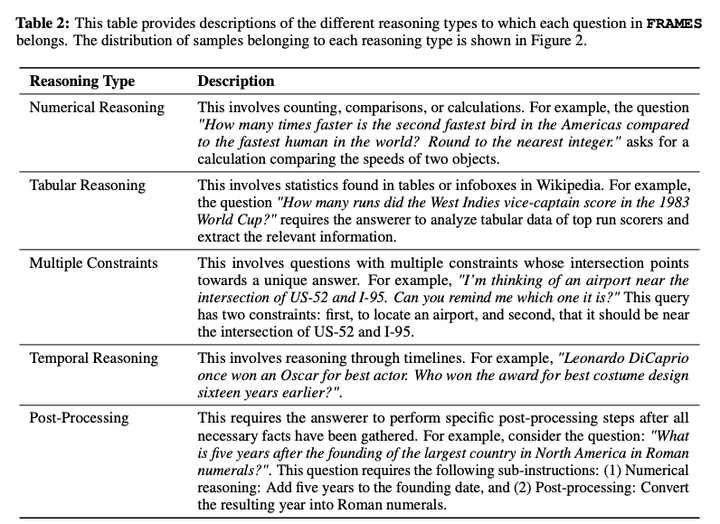
新框架:FRAMES
一个多步骤检索和推理框架,迫使模型迭代检索和推理,从而显著提高它们在复杂查询上的性能。
FRAMES 是一组包含 824 个问题的评估,目的提供对检索增强生成 (RAG) 系统的端到端评估。它评估了 RAG 系统的三个关键组成部分:事实性、检索和推理。与大多数孤立评估这些 RAG 组件的现有数据集和基准不同,FRAMES提供了一个全面的测试平台,以清楚地了解 RAG 系统的整体质量性能。
三、让我们一起展望FRAMES数据集应用
比如,我是一个人工智能研发团队的成员。
我的工作中需要开发和评估新的RAG系统。但这个任务非常复杂,需要一个全面和统一的评估框架。
当我使用了 FRAMES , 它可真是帮了我的大忙!
我给它一个复杂的查询问题,它快速地评估了LLMs在事实检索、推理和信息综合方面的能力。
我指着结果说:“你看,这个模型在多跳问题上的表现多好,它能够准确整合多个来源的信息。”
然后,我又指向另一个问题:“这里呢,是一个需要复杂推理的问题,FRAMES能够清晰地评估出模型的推理能力。”
最后,我给它一个需要多步检索的问题:“给我处理一下这个复杂的查询。” 它依然能够稳定地输出准确的评估结果。
它让RAG系统的性能评估变得简单明了,让我的工作轻松多了。生活如此美妙。