Vivo开奖了,劝退价。。
vivo 也开奖了,不过有小伙伴反馈是个劝退价,甚至不如隔壁的 oppo,要说这两家也是渊源颇深,一家是绿厂,一家是蓝厂,高管也都是早期步步高出来的。
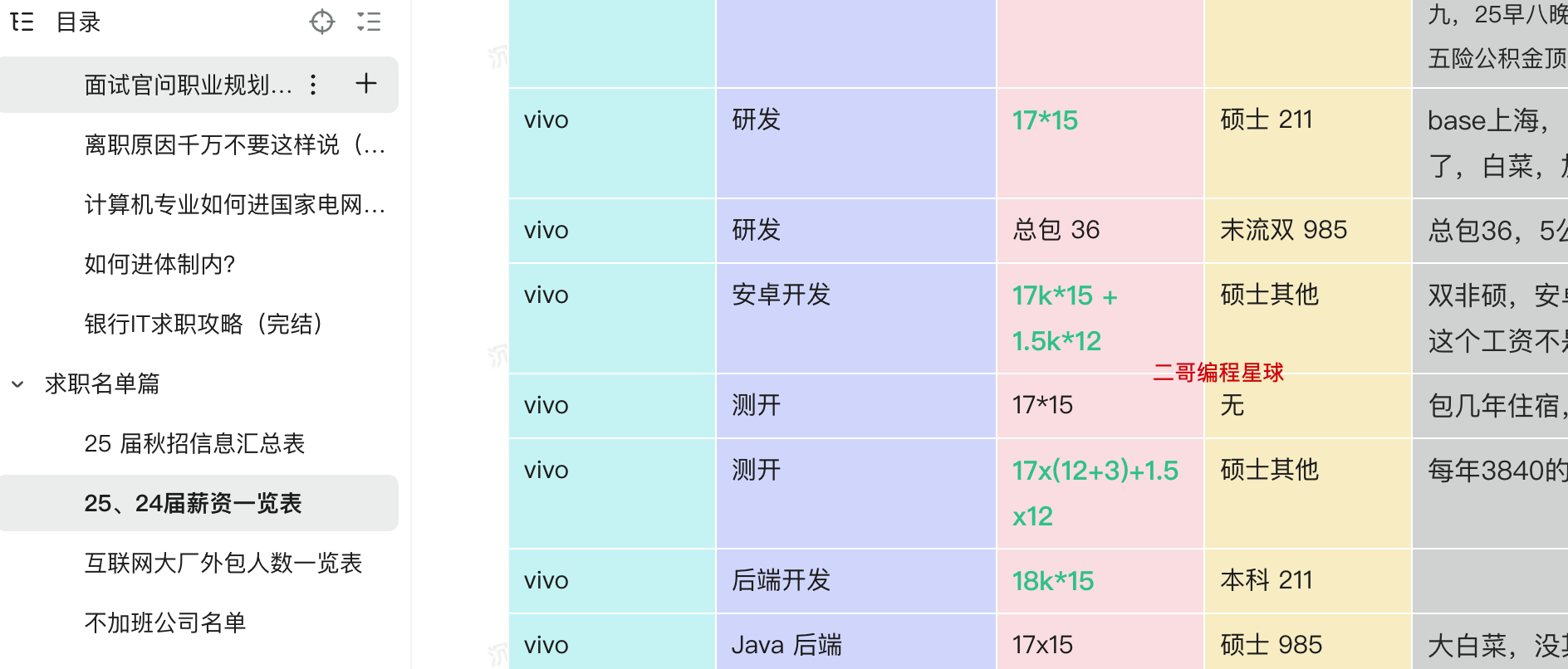
给大家盘一下开奖的信息,方便大家横向做个对比,毕竟第一份工作真的很重要,不要让自己:
- 硕士 211 研发岗 17k*15,base 上海,白菜,加上补贴 27万的年包
- 末流双 985 研发岗总包 36 5% 的公积金
- 硕士其他,也是 17k 的 base,安卓开发,还有 12 月的补贴(房补之类)
- 硕士其他测试岗仍然是 17k 的 base,几乎和前面的安卓开发一模一样,说明 vivo 的内部定价系统是比较死板的
- 本科 211 后端开发倒是开到了 18k,说明面评比较好。
- 硕士 985 Java 后端 17k,纯粹的大白菜
接下来就给大家分享一个《Java 面试指南》中收录的同学 10 的 vivo 一面面经,来看看 vivo 的面试官都喜欢问哪些问题,好做到知彼知己,被面试官吊打,哦不,吊打面试官(dog)。

vivo 同学 10 一面面经
实习具体开发的功能是哪些
润了一下技术派作为实习项目。

1、整体前后端分离骨架的搭建,后端用的 Spring Boot+MyBatis-Plus+Redis+RabbitMQ,Admin 管理端用的 React,用户端用的 Thymeleaf。
2、使用 JWT + Session + Filter + AOP 完成用户登录和权限校验,支持微信扫码登录
3、作者使用 Markdown 发布教程、文章,图片会自动上传至 OSS 并使用 CDN 分发,用户可以点赞、收藏、评论,并且使用 RabbitMQ 进行异步消息处理
4、对接讯飞星火、智谱 AI、字节豆包、阿里通义、OpenAI 等多家大模型,完成派聪明 AI 助手功能的开发,使用了策略模式和工厂模式,新增模型时非常简单,并通过 WebSocket 和 Stream 流实现及时通信和消息一点一点输出的效果
5、使用 Redis 实现作者白名单和用户活跃榜单,并且对热点数据进行缓存,为了提高缓存效率减轻 Redis 压力,还增加了本地缓存 Caffeine 作为二级缓存
6、借助 xxl-job 实现文章定时发布,ES 实现快速高效的文章查询等等。
遇到的最深刻的问题,怎么解决的
遇到最深刻的一个问题是,如何解决高并发情况下,大量用户同时访问同一篇热点文章,在缓存未命中的情况下,大量请求会同时访问数据库,对 DB 造成极大的请求压力,很容易将我们的 MySQL 打宕机,进而影响整个服务,这个时候该怎么办?
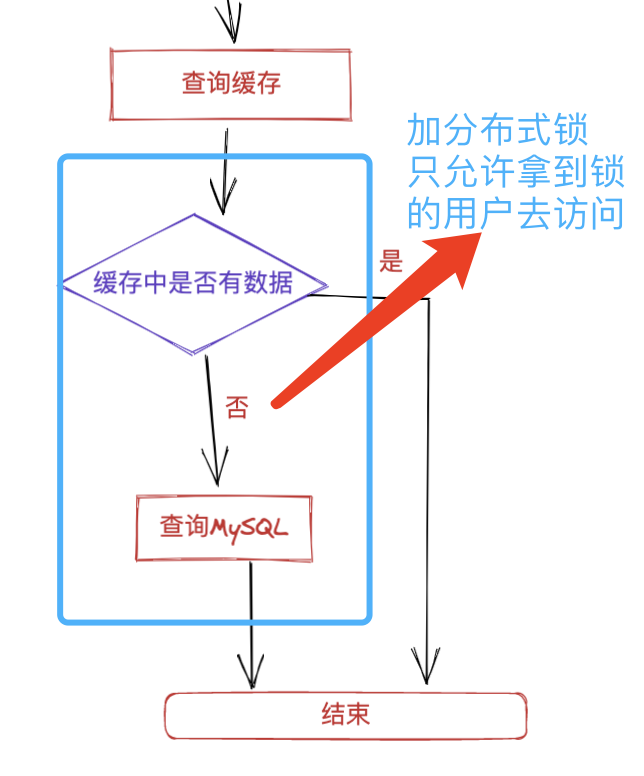
一开始尝试通过 Redis 的 setIfAbsent(key,value,time)手动释放锁,但遇到了锁不能及时释放的问题、误释放别人的锁,以及过期时间的设置是否合理等问题。
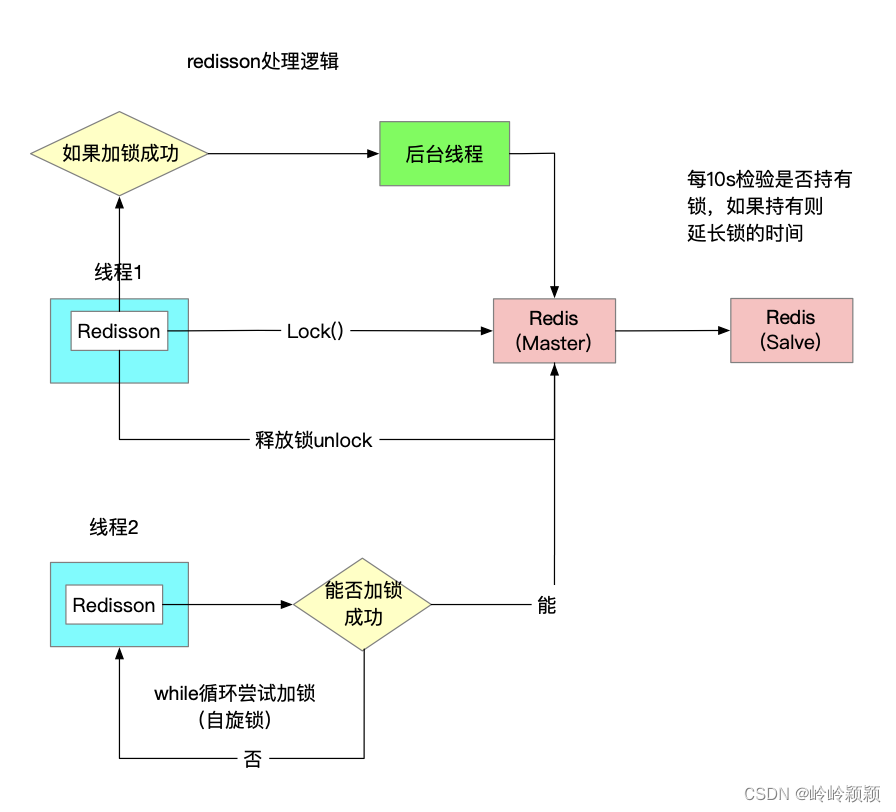
最后还是通过引入 Redission 的看门狗算法进行解决,这样就可以一劳永逸了,不过手动尝试的方式的确也让我对看门狗算法有了一个更深入更直接的了解,它的内部实现也是按照我之前手动的逻辑实现的,起一个定时任务,每 10 秒检查一下锁是否释放,如果没有释放就延长至 30 秒。
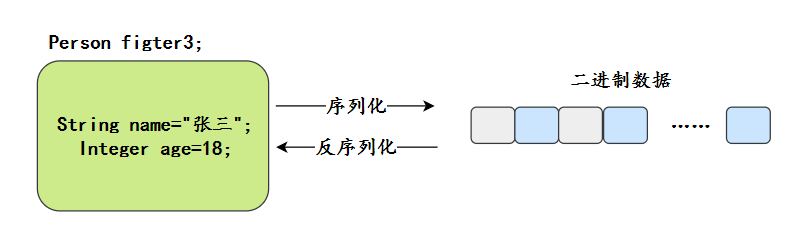
什么是序列化,什么是反序列化
序列化(Serialization)是指将对象转换为字节流的过程,以便能够将该对象保存到文件、数据库,或者进行网络传输。
反序列化(Deserialization)就是将字节流转换回对象的过程,以便构建原始对象。
怎么删除/创建一张表和设定主键
在 MySQL 中,我们可以使用 DROP TABLE 来删除表,使用 CREATE TABLE 来创建表并设定主键。创建表时,可以在定义列的同时设置某一列为主键,如将 id 列设为主键:PRIMARY KEY (id)。
CREATE TABLE users (
id INT AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
email VARCHAR(100),
PRIMARY KEY (id)
);
索引,索引优化举例,为什么使用索引更快
数据库文件是存储在磁盘上的,磁盘 I/O 是数据库操作中最耗时的部分之一。没有索引时,数据库会进行全表扫描(Sequential Scan),这意味着它必须读取表中的每一行数据来查找匹配的行(时间效率为 O(n))。当表的数据量非常大时,就会导致大量的磁盘 I/O 操作。
有了索引,就可以直接跳到索引指示的数据位置,而不必扫描整张表,从而大大减少了磁盘 I/O 操作的次数。
MySQL 的 InnoDB 存储引擎默认使用 B+ 树来作为索引的数据结构,而 B+ 树的查询效率非常高,时间复杂度为 O(logN)。
索引文件相较于数据库文件,体积小得多,查到索引之后再映射到数据库记录,查询效率就会高很多。
索引就好像书的目录,通过目录去查找对应的章节内容会比一页一页的翻书快很多。
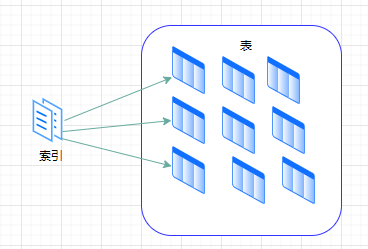
索引优化举例?
在实际开发中,我们可以通过合理使用单字段索引、复合索引和覆盖索引来优化查询。例如,如果要加速查询 age 字段的条件,我们可以在 age 字段上创建索引。
CREATE INDEX idx_age ON users(age);
如果查询涉及多个字段 age 和 name,可以使用复合索引来提高查询效率。
CREATE INDEX idx_age_name ON users(age, name);
当我们只需要查询部分字段时 SELECT name FROM users WHERE age = 30;,覆盖索引可以提升查询效率。
CREATE INDEX idx_age_name ON users(age, name);
由于 age 和 name 字段都在索引中,MySQL 直接从索引中获取结果,无需回表查找。
事务的概念
事务是一个或多个 SQL 语句组成的一个执行单元,这些 SQL 语句要么全部执行成功,要么全部不执行,不会出现部分执行的情况。主要作用是保证数据库操作的一致性。
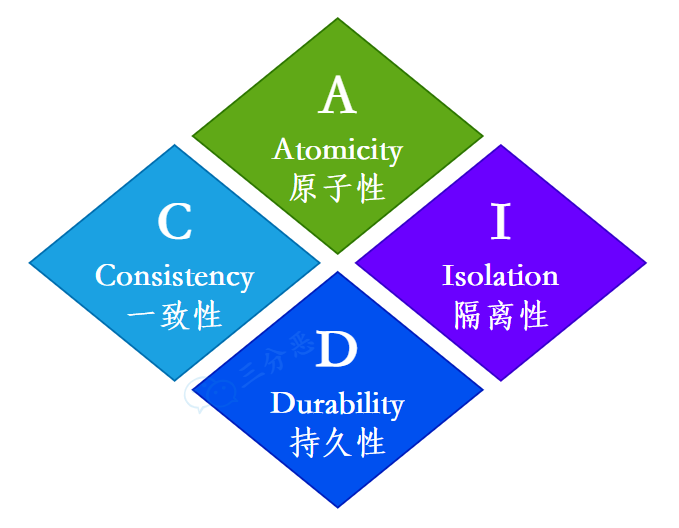
事务具有四个基本特性,也就是通常所说的 ACID 特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
举例用sql实现升序降序
在 SQL 中,可以使用 ORDER BY 子句来对查询结果进行升序或降序排序。默认情况下,查询结果是升序排序,也可以通过 DESC 关键字进行降序排序。
例如,如果我想对 employees 表中的数据按工资升序排序,我会使用:
SELECT id, name, salary
FROM employees
ORDER BY salary ASC;
此外,如果我需要根据多个字段进行排序,例如先按工资降序排列,再按名字升序排列,我可以使用:
SELECT id, name, salary
FROM employees
ORDER BY salary DESC, name ASC;
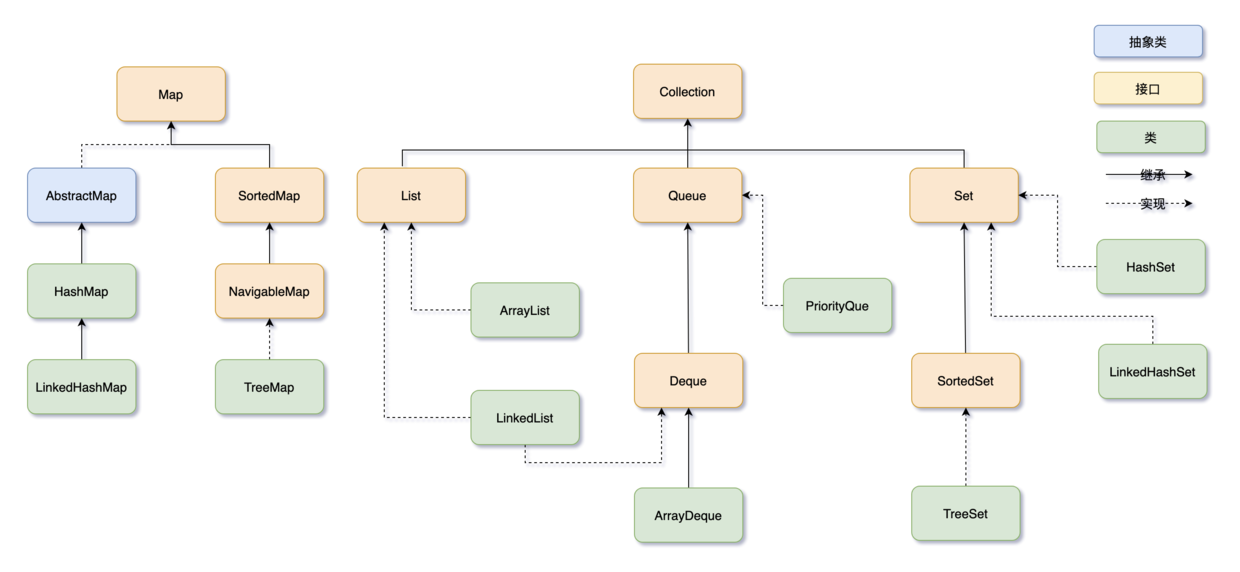
Java中的集合有哪些
Java 集合框架可以分为两条大的支线:
①、Collection,主要由 List、Set、Queue 组成:
- List 代表有序、可重复的集合,典型代表就是封装了动态数组的 ArrayList 和封装了链表的 LinkedList;
- Set 代表无序、不可重复的集合,典型代表就是 HashSet 和 TreeSet;
- Queue 代表队列,典型代表就是双端队列 ArrayDeque,以及优先级队列 PriorityQueue。
②、Map,代表键值对的集合,典型代表就是 HashMap。
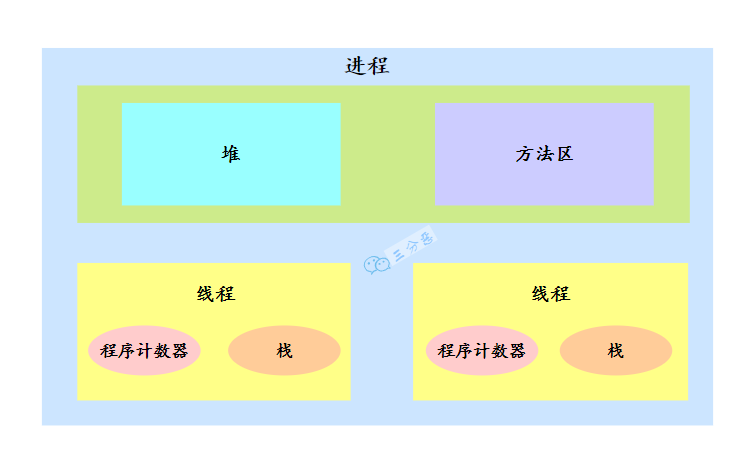
线程的概念,线程有哪些状态
线程是操作系统中调度的最小单位,它是进程中的独立执行单元。多个线程可以共享同一个进程的资源,如内存和文件句柄,但每个线程都有自己独立的栈和寄存器。与进程相比,线程的创建和上下文切换开销更小,因此在需要并发执行任务时,多线程是一种常用的解决方案。
在编程中,多线程的典型应用包括并行处理、I/O 操作、并发服务器等场景。每个线程都有自己的生命周期,包括新建、就绪、运行、阻塞和终止。
说一下GC,有哪些方法
垃圾回收(Garbage Collection,GC)就是对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收。
JVM 在做 GC 之前,会先搞清楚什么是垃圾,什么不是垃圾,通常会通过可达性分析算法来判断对象是否存活。
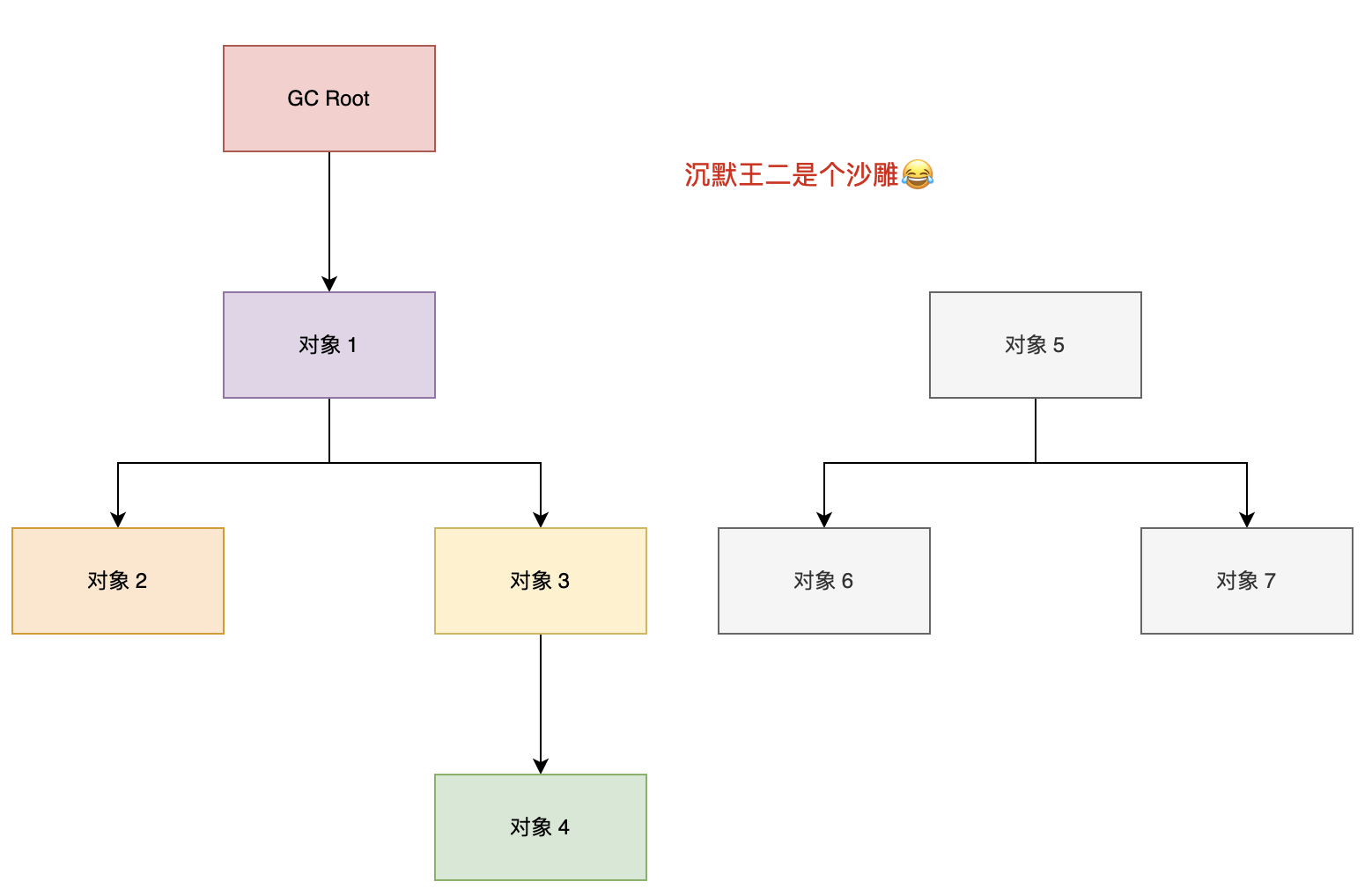
在确定了哪些垃圾可以被回收后,垃圾收集器(如 CMS、G1、ZGC)要做的事情就是进行垃圾回收,可以采用标记清除算法、复制算法、标记整理算法、分代收集算法等。
了解哪些设计模式,开闭原则
单例模式、策略模式和工厂模式。
在需要控制资源访问,如配置管理、连接池管理时经常使用单例模式。它确保了全局只有一个实例,并提供了一个全局访问点。
在有多种算法或策略可以切换使用的情况下,我会使用策略模式。像技术派实战项目中,我就使用策略模式对接了讯飞星火、OpenAI、智谱 AI 等多家大模型,实现了一个可以自由切换大模型基座的智能助手服务。
策略模式的好处是,不用在代码中写 if/else 判断,而是将不同的 AI 服务封装成不同的策略类,通过工厂模式创建不同的 AI 服务实例,从而实现 AI 服务的动态切换。
后面想添加新的 AI 服务,只需要增加一个新的策略类,不需要修改原有代码,这样就提高了代码的可扩展性。
什么是开闭原则?
开闭原则(Open-Closed Principle, OCP),指软件实体应该对扩展开放,对修改关闭。这意味着一个类应该通过扩展来实现新的功能,而不是通过修改已有的代码来实现。
举个例子,在不遵守开闭原则的情况下,有一个需要处理不同形状的绘图功能类。
class ShapeDrawer {
public void draw(Shape shape) {
if (shape instanceof Circle) {
drawCircle((Circle) shape);
} else if (shape instanceof Rectangle) {
drawRectangle((Rectangle) shape);
}
}
private void drawCircle(Circle circle) {
// 画圆形
}
private void drawRectangle(Rectangle rectangle) {
// 画矩形
}
}
每增加一种形状,就需要修改一次 draw 方法,这违反了开闭原则。正确的做法是通过继承和多态来实现新的形状类,然后在 ShapeDrawer 中添加新的 draw 方法。
// 抽象的 Shape 类
abstract class Shape {
public abstract void draw();
}
// 具体的 Circle 类
class Circle extends Shape {
@Override
public void draw() {
// 画圆形
}
}
// 具体的 Rectangle 类
class Rectangle extends Shape {
@Override
public void draw() {
// 画矩形
}
}
// 使用开闭原则的 ShapeDrawer 类
class ShapeDrawer {
public void draw(Shape shape) {
shape.draw(); // 调用多态的 draw 方法
}
}
内容来源
- 星球嘉宾三分恶的面渣逆袭:https://javabetter.cn/sidebar/sanfene/nixi.html
- 二哥的 Java 进阶之路(GitHub 已有 12000+star):https://javabetter.cn