DMRl-Former用于工业过程预测建模和关键样本分析的数据模式相关可解释Transformer网络
DMRl-Former用于工业过程预测建模和关键样本分析的数据模式相关可解释Transformer网络
Liu, Diju, et al. “Data mode related interpretable transformer network for predictive modeling and key sample analysis in industrial processes.” IEEE Transactions on Industrial Informatics 19.9 (2022): 9325-9336.
文章目录
- DMRl-Former用于工业过程预测建模和关键样本分析的数据模式相关可解释Transformer网络
- 摘要
- 绪论
- 创新点
- 方法
- 工业应用
摘要
准确预测难以测量的质量变量对于工业过程控制和优化至关重要。然而,原材料质量和生产条件的波动可能会导致工业过程数据在多种工作条件下分布。
在相同工作条件下的数据显示出相似的特征,这些特征通常被定义为一种数据模式。因此,整个过程数据表现出多模式特性,这给开发统一的预测模型带来了巨大的挑战。
此外,现有数据驱动预测模型的不可解释性给其实际应用带来了很大的阻力。
为了解决这些问题,本文提出了一种新的与模式相关的可解释Transformer网络(DMRl-Former),用于工业过程中的预测建模和关键样本分析。
在DMRl-Former中,设计了一种新的数据模式相关的可解释自注意机制,以提高每个个体对同模的感知能力,同时捕捉不同模式的跨模特征。
绪论
在碳达峰和碳中和的背景下,工业过程迫切寻求智能化转型升级,过程的实时监控、控制和优化是最重要的任务之一
关键质量变量的实时测量是工业制造状态的最有效反映,不幸的是,由于测量技术和工业环境的限制,大多数质量变量无法及时测量
随着时间的推移,使用易于测量的过程变量预测难以测量的质量变量的软测量技术应运而生
- 就是用工业生产中容易采集的数据去预测难以采集的数据
在实际工业过程中应用数据驱动方法仍有三个关键问题需要解决。
首先,现有的数据驱动模型大多假设数据是单模分布的。在构建实际工业过程的预测模型时,有必要考虑数据的多模特性。
其次,大多数现有的数据驱动模型都是不可解释的,即大多数数据驱动模型都难以实现最基本的可解释性。
第三个问题是,大多数模型基于输入数据进行单步预测。然而,在实际工业过程中,对时间序列数据进行多步预测的需求同样迫切
创新点
本文的主要贡献如下。
1) 提出了一种基于Transformer的新型网络DMRFormer,用于精确预测关键质量变量和对模型过程进行可解释分析。
2) 传统的自我注意机制被增强为数据模式相关的可解释自我注意机制(DMRI-SA),以充分提取数据模式信息。
3) 同模注意旨在描述每个单独模式中样本的相似性,交叉模式注意旨在捕捉不同模式样本之间的相互作用。
4) 可视化技术通过发现不同模式层的作用机制并将密钥样本定位在不同模式集中来提高模型的可解释性。
5) 与其他最先进的方法相比,两个工业过程的实验结果验证了所提出方法的有效性。
方法
- 自注意力不再赘述,一点改进都没有
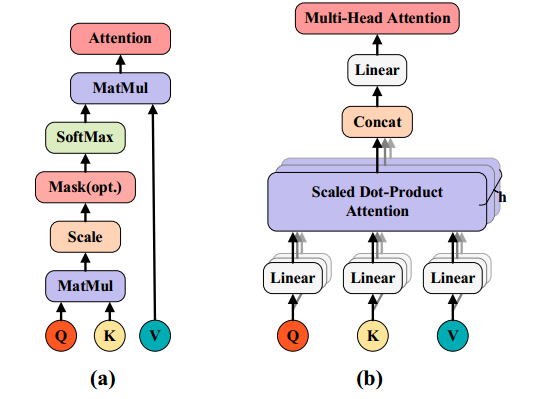
与数据模式相关的可解释自我注意机制
在工业过程中,属于同一模式的数据具有很高的相关性。此外,相邻模式之间也存在一定的相互作用。
为了充分提取同一模式内的相关性,并考虑过程数据不同模式之间的相互作用,本文提出了一种与数据模式相关的可解释自我注意(DMRI-SA)策略。
DMRI-SA的概念图如图3所示,由模式聚类、同模式注意和跨模式注意组成。
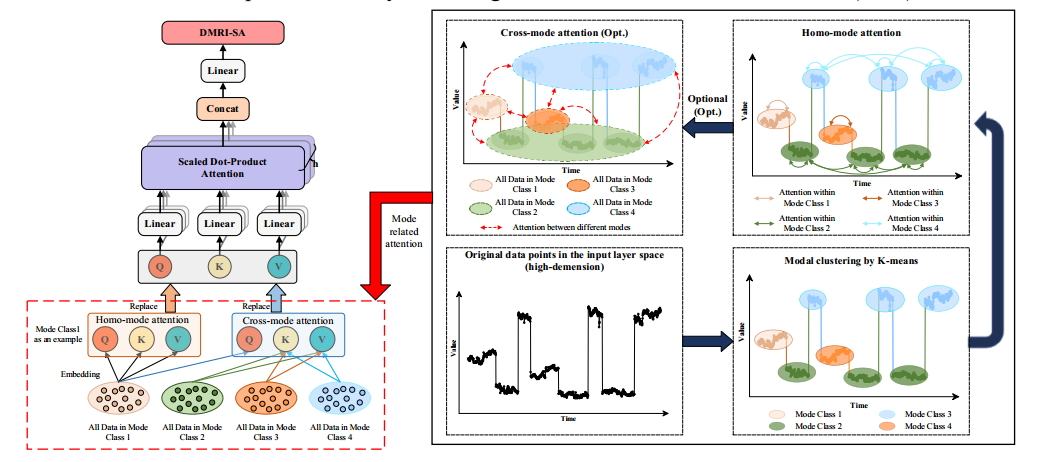
首先,对数据进行聚类以获得数据模式标签。由于收集到的工业过程数据没有数据模式标签,因此使用无监督聚类方法根据数据特征为样本分配数据模式标签。
在这项研究中,K-means方法被用来对过程数据进行聚类,以获得其数据模式标签。
其次,利用获取的数据模式标签进行同模注意。
第三,在跨模式注意力中,考虑了不同数据模式之间的相互作用,以避免仅通过测量同一注意力而造成的信息损失。
在DMRI-SA中,交叉模式注意力被设计为一个可选步骤,由每个模式的大小决定。这主要是因为当一个模式中的数据量足够时,跨模式注意力可能会增加计算复杂性,而同模式注意力可以充分表征每个模式。
值得注意的是,DMRI-SA为关键模式样本的定位提供了一种具有良好可视化和解释意义的新方法。根据上述描述,在DMRI-SA中提取样本模式信息的方法是通过使用查询样本和所有样本键之间的点积相似度作为权重来聚合所有样本信息。
数据模式相关的可解释Transformer
为了充分探索数据模式内部和之间的特征,将提出的DMRI-SA引入传统的转换器中,以取代自注意力,构建一个新的DMRIFormer网络。
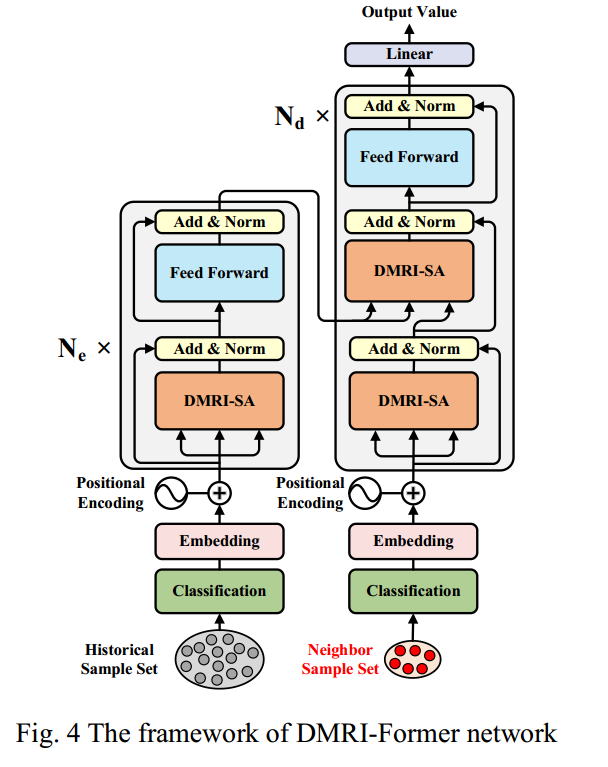
DMRl-基于前体的软测量建模
所提出的DMRI-Former网络可以分层提取每种模式的相关性,并充分考虑不同模式之间的相互作用。
同时,可量化的注意力得分提高了建模过程的可解释性,为确定关键模式样本提供了新的思路。
因此,它非常适合工业过程的软测量建模,特别是由于操作条件变化而具有多模特性的过程数据。
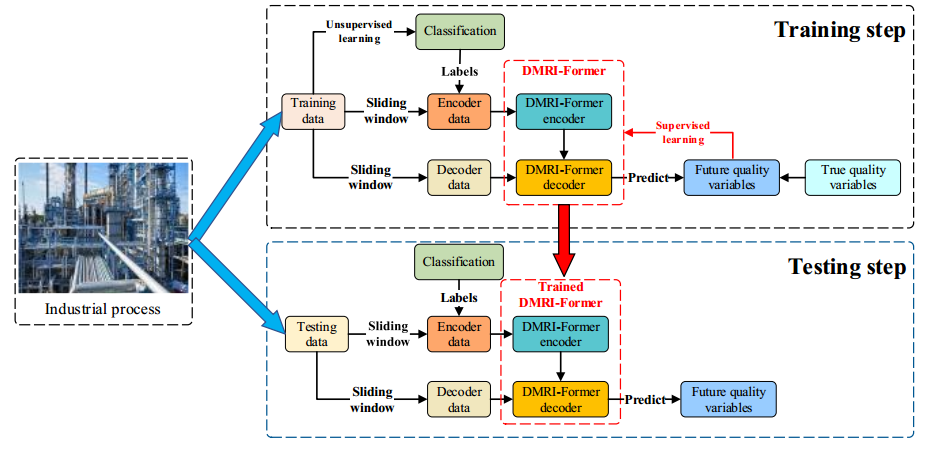
它主要通过以下步骤。首先,从工业过程中收集的数据分为训练数据和测试数据。
分类模型用于通过属于无监督学习的无监督聚类算法标记所有未标记训练数据的模式类。
接下来,利用滑动窗口技术,使用相应的标记模式选择编码器和解码器的输入数据。之后,将样本输入DMRI Former模型以预测关键质量变量。随后,通过属于监督学习的反向传播算法,利用标记数据值和预测数据值之间的误差来构建损失函数,以更新模型参数。最后,将测试数据发送到训练好的DMRI Former模型,以获得关键质量变量的预测结果。
工业应用
本节对所提出的DMRI Former网络在工业脱丁烷塔工艺和加氢裂化工艺中进行了实验模拟。
A.脱丁烷塔
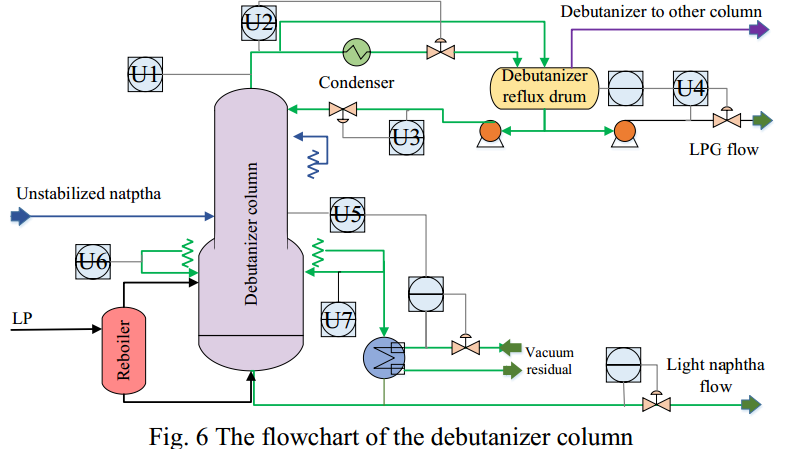
脱丁烷塔是一种用于分离C3、C4和其他馏分的精炼工艺,其中C4从塔底抽出。其流程图如图6所示。脱丁烷塔的整个系统由六个主要部分组成,包括换热器、塔顶冷凝器、塔上再沸器、扬程回流泵、液化石油气分离器的进料泵和回流储罐。整个系统的高效运行在很大程度上取决于C4成分的实时测量。然而,由于测量环境的限制,C4的测量目前依赖于塔顶的单个气体探测器。这样,不仅检测精度非常有限,而且检测延迟也很大。因此,构建一个软测量模型来预测脱丁烷塔过程中的C4是必要和紧迫的。如图6中的灰色圆圈所示,选择了七个用于全过程分析的常用辅助变量来构建软传感器模型。
值得注意的是,选择较大的滑动窗口长度编码器和较小的滑动窗口长解码器可以同时保持最佳性能和最小的计算工作量。表III显示了具有最佳超参数组合的八种方法的实验结果。从表III的实验结果可以看出,PCR的预测结果较差。这主要是因为PCR是一种静态方法,无法捕捉序列的动态转换模式。虽然LSTNet和SLSTM可以利用LSTM的递归结构来提取时间序列的变化模式,但当数据模式不同时,它们无法感知不同的进化模式。因此,他们的预测结果仍然表现不佳。STALSTM结合时空注意力在一定程度上解决了这个问题,但由于其捕获远程特征的能力有限,其预测性能仍然不是最优的。此外,随着预测长度的增加,Informer的性能急剧下降。这主要是因为Informer的ProbSparse自关注机制只考虑了少量的历史样本,导致多模式数据集中的信息大量丢失。mvts变换器利用随机掩码预训练使模型能够感知序列的整体特征。但它仍然缺乏感知动态模式的能力,导致其性能欠佳。相比之下,LogTrans的预测性能优于其他方法,但仍不如DMRI Former。这主要是因为LogTrans在计算注意力时考虑了多个最近邻样本,这在一定程度上增加了同一模式样本之间的相似性,削弱了不同模式之间的相似度。从所有实验结果和分析来看,所提出的DMRI形式在所有方法中具有最佳的预测性能。这主要是因为DMRI Former考虑了相同模式之间的相似性和不同模式之间的相互作用。通过这种方式,它提高了从数据中提取更有价值信息的能力,同时避免了信息丢失。
果和分析来看,所提出的DMRI形式在所有方法中具有最佳的预测性能。这主要是因为DMRI Former考虑了相同模式之间的相似性和不同模式之间的相互作用。通过这种方式,它提高了从数据中提取更有价值信息的能力,同时避免了信息丢失。
