【植物识别】Python+深度学习+人工智能+CNN卷积神经网络+算法模型训练+TensorFlow
一、介绍
植物识别系统,使用Python作为主要编程语言开发,通过收集常见的6中植物树叶(‘广玉兰’, ‘杜鹃’, ‘梧桐’, ‘樟叶’, ‘芭蕉’, ‘银杏’)图片作为数据集,然后使用TensorFlow搭建ResNet50算法网络模型,通过对数据集进行处理后进行模型迭代训练,得到一个识别精度较高的H5模型文件。并基于Django框架开发网页端平台,实现用户在网页上上传一张植物树叶图片识别其名称。
二、系统效果图片展示
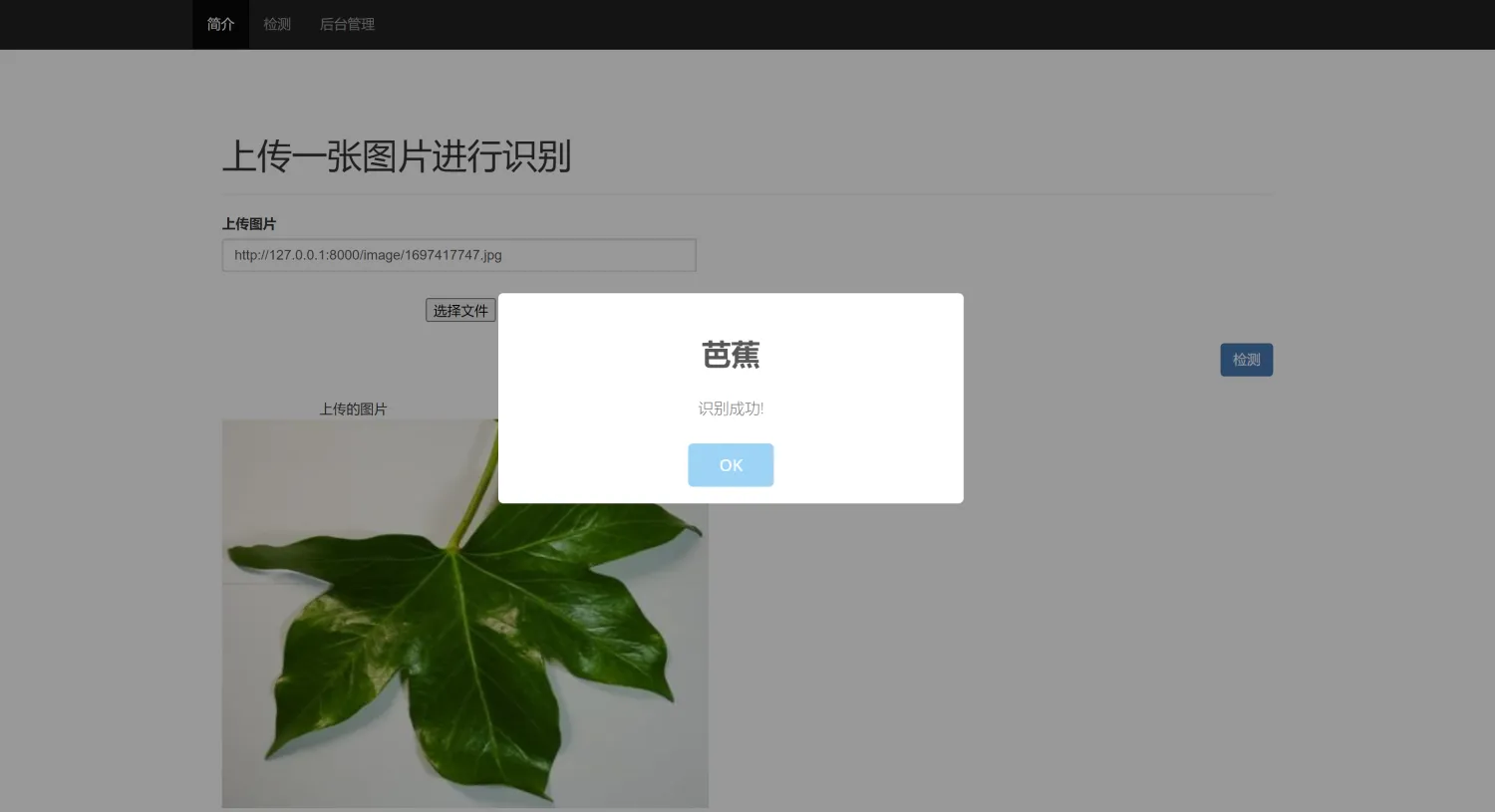
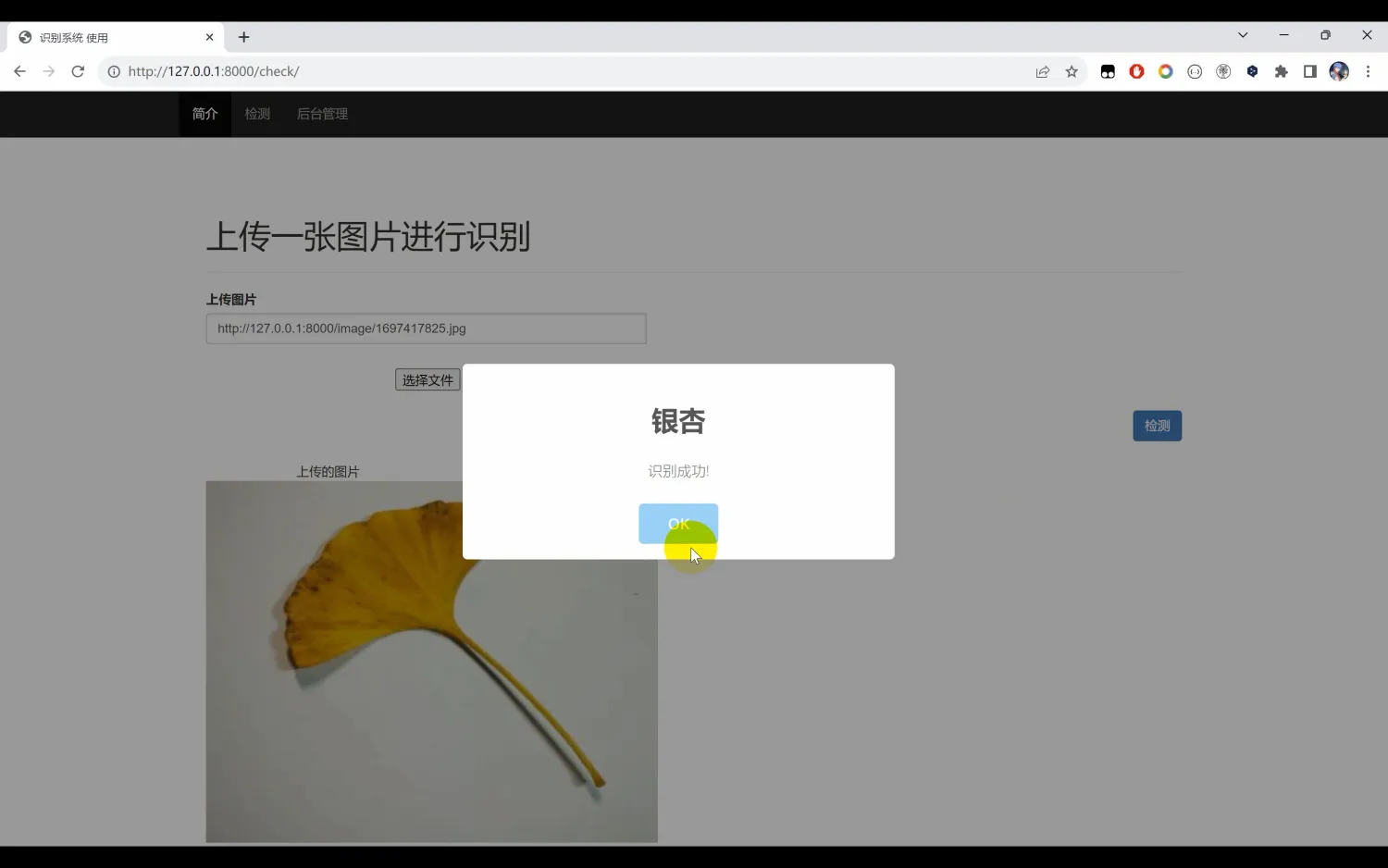
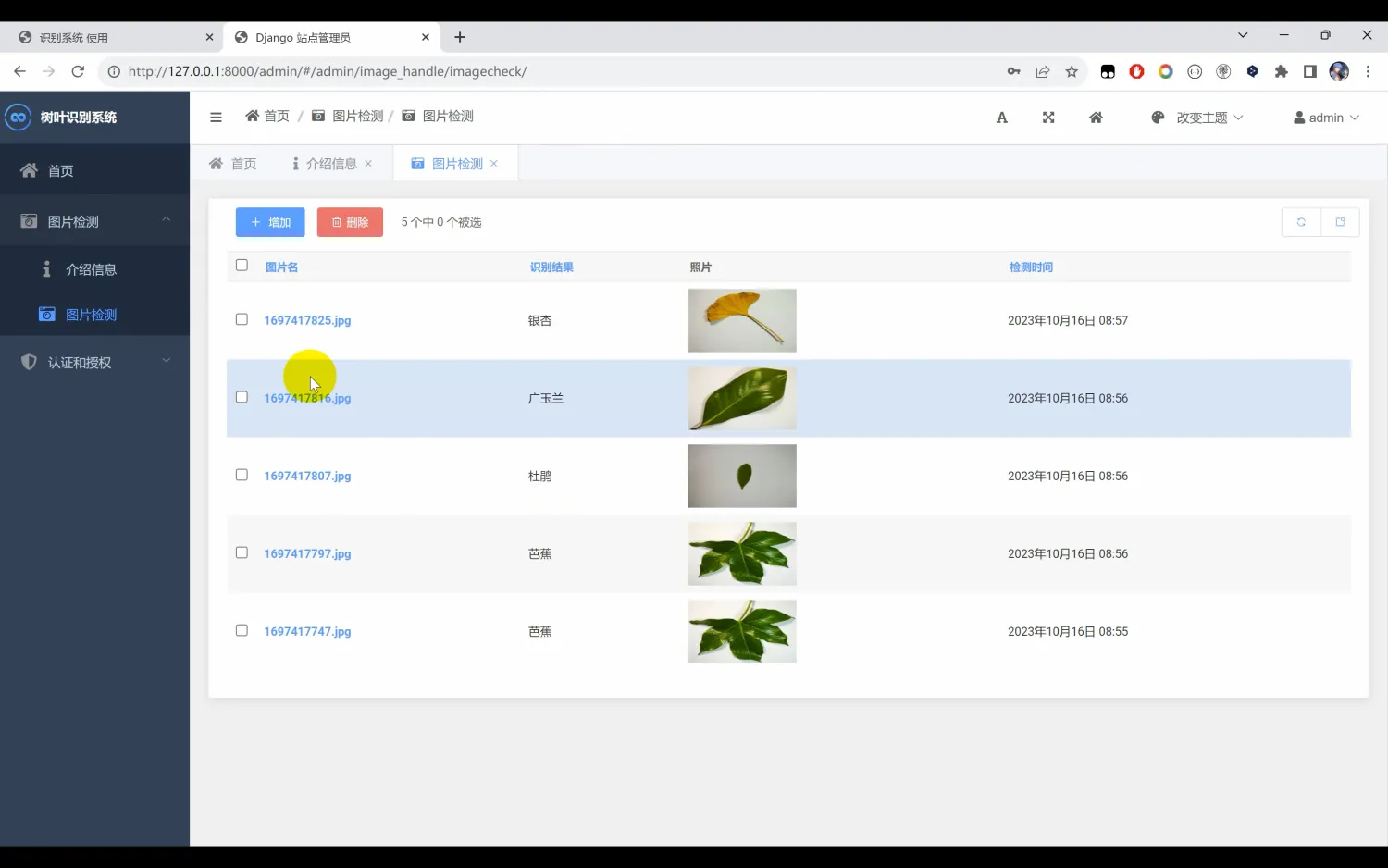
三、演示视频 and 完整代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/yt0dsez3zk2dxs66
四、TensorFlow介绍
TensorFlow是一个开源的机器学习框架,由Google Brain Team开发,广泛用于计算机视觉、自然语言处理等领域。在图像识别方面,TensorFlow提供了强大的工具和API,使得构建和训练深度学习模型变得简单高效。
TensorFlow在图像识别的应用主要体现在能够通过训练深度神经网络模型来识别和分类图像中的对象。例如,使用MNIST数据集识别手写数字,或者使用CIFAR-10数据集识别多种物体类别。
以下是一段使用TensorFlow进行图像识别的简单示例代码:
import tensorflow as tf
# 加载数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 标准化数据
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 评估模型
model.evaluate(x_test, y_test, verbose=2)
这段代码首先加载了MNIST手写数字数据集,然后构建了一个简单的神经网络模型,包括一个Flatten层、一个Dense层和一个Dropout层,最后是输出层。模型编译后,使用Adam优化器和稀疏分类交叉熵损失函数进行训练,并在测试集上进行评估。