数据结构和算法入门
复杂度
大O记法
计算机怎么判断程序性能?
我们都知道编程基本上是在和数据打交道,大多数程序基本都在处理获取数据、查询数据、操作数据、返回数据相关的逻辑。
因此出现了数据结构和算法,这两者出现本质为了解决如何能够更快、更省进行数据处理。
这里的更快,也就是程序运行时间更短,对应的指标我们称之为时间复杂度。
这里的更省,也就是程序运行所消耗的内存更少,对应的指标我们称之为空间复杂度。
为什么需要复杂度?
通过开始运行和结束运行这两个时间点差额和内存使用情况的计算方法可以判断性能,进行复杂度分析主要以下有三个原因:
1.测试结果大大依赖硬件条件
以时间举例,不可能绝对的说某个代码需要跑 10s,在某台机器上就能够跑 10s。因为程序的执行和机器的性能正向相关,如果放在一台老的机器上会大大多于 10s,而放在一款未来高性能机器上可能只需要 5s。 因此受硬件环境的影响,并不能简单的用时间去统计。
2.测试结果需要事后才能计算
上面所有的操作,往往都是在程序运行之后才能形成统计结果,但我们大多希望在伪码阶段,便能预测程序的执行性能。 因此这种事后统计法不能作为性能预测的方法。
3.测试结果受原始数据特性影响大
以排序为例计算需要所需的时间,试想如果给出的数据就已经是排好序的,那需要的时间几乎等于 0,而如果给出的数据是完全的打乱的,那需要时间肯定非常长。 因此发现测试结果本身就存在差异,除非我们的样本足够的多,否则计算出来的结果往往具有片面性。
总结
所以我们需要一个不用具体的测试数据和测试环境,就可以粗略地估计算法执行效率的方法。 这个方法称作为复杂度也就是大O 记法。
复杂度分析(大 O 记法)是数据结构和算法的精髓和基石,只有掌握好它,才能更好的学习数据结构和算法。
时间复杂度
如何计算时间复杂度?
在现实中无法用实际运行时间预估程序运行时间,但是可以使用步数作为时间复杂度的计算。步数可以简单理解数组的每次索引值的读取,就算作一步,也可以被称作为unit_time。
案例1:数组值获取(O(1))
题目:我们需要获取数组的第 4 个位置的值。
int a[] = {0, 1, 2, 3, 4, 5, 6};
System.out.println(a[3]); // step1
如上step1:获取a第 3 个索引位置的值,把这个时间称作为 1 步。 实际上在计算机底层,计算机可以通过一步跳到任意一个索引的位置进行数据的读取,因此这个时间也被称为单位时间unit_time。
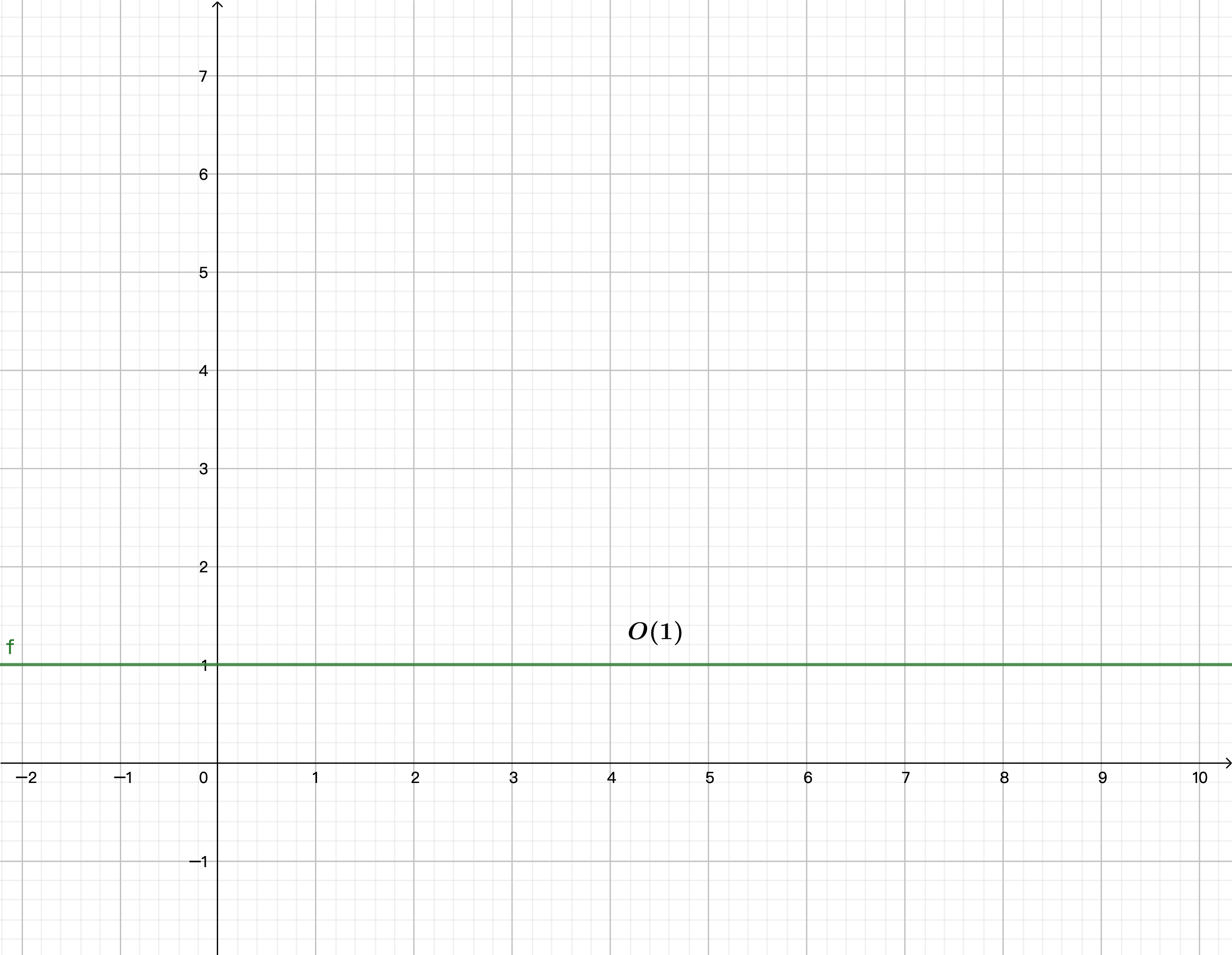
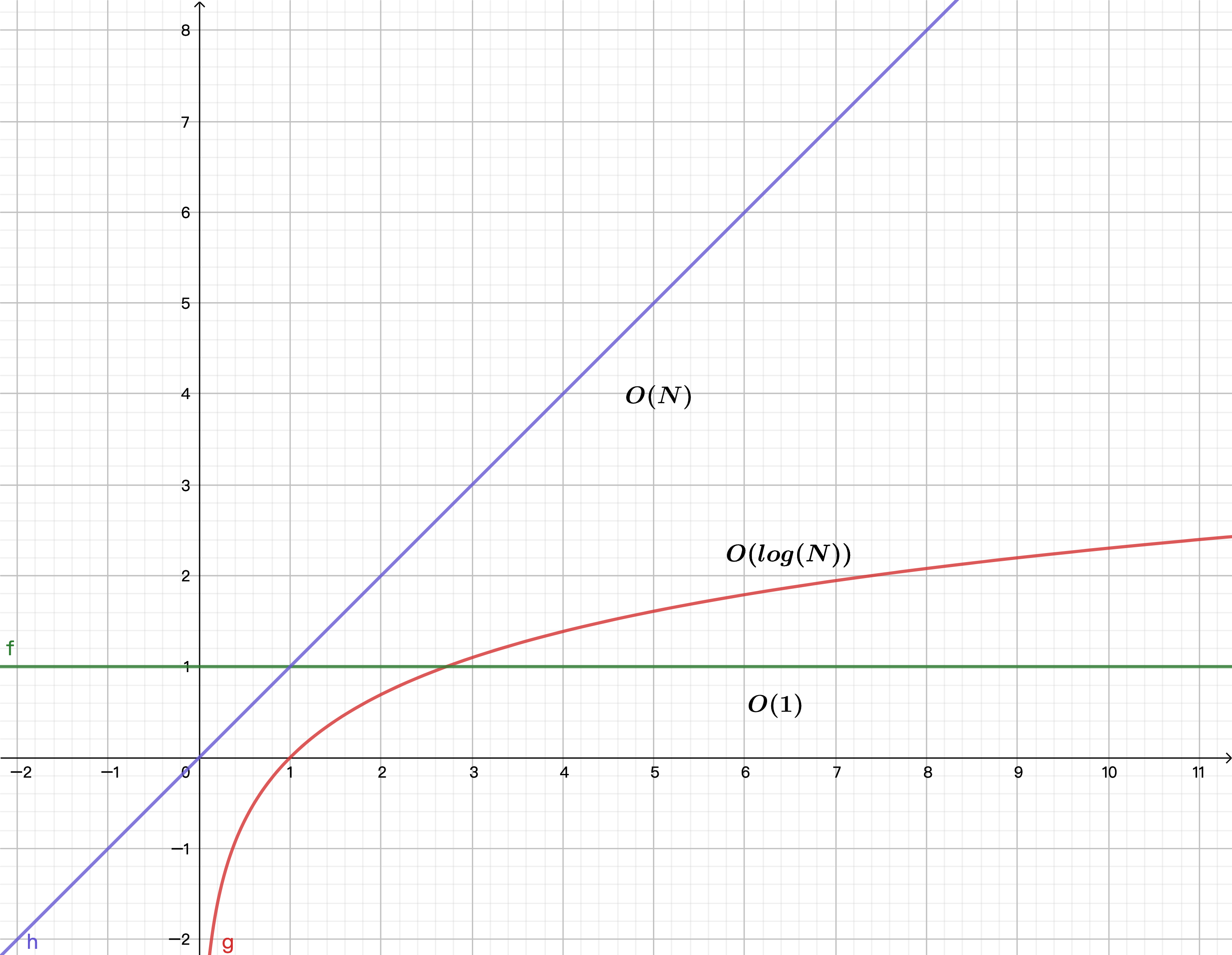
如果用大 O 记法,我们称作为常数时间---O(1)。 用通俗的话解释也就是:无论数组的长度多少,获取数组中某个值的都只是 1 步。随着数组数量增加,时间复杂度并不会提升。
如果用数学公式表示程序运行所需的时间(x 表示数组的长度,后面坐标图都一样),结果是:
案例2:猜数字游戏(O(logN))
在上一章,我们学习过的猜数字的游戏,我们知道需要的步数为log(N),我们称为对数时间---O(log(N))。
用数学公式表示如下:

可以看到O(log(N))比O(1)增长的更快一些,性能更差一点。
案例3:计算 N 的阶乘(O(N))
题目:我们需要定义一个函数,这个函数能计算传入参数 N 的阶乘 N!。
![]()
public int factorial(int n) {
int result = 1; //step1
for (int i = 1; i <= n; i++) { //step2
result *= i; // step3
}
return result;
}
这里就比上面复杂,如果对数据操作一次,算作一步,大致数一数一共需要多少步:
- step1 : 初始化变量
result: 1 步; - step2 : 初始化变量
i。1 步;i++相当于i = i + 1,需要执行 N 次,因此 step2 一共 N + 1 步; - step3 : 执行 N 步。
(注意,在此处暂时只考虑数据赋值操作情况,暂时不考虑i <= n代码)
那么一共的时间复杂度为2N + 2。如果用大 O 记法,称作为**线性时间---O(2N + 2)**。
忽略常量
通过这两个案例,大家已经发现大 O 记法,表示的是代码执行时间随数据规模增长的变化趋势,也就是需要把 N 想象成 1W,100W 甚至更大。
而在这种情况下,常量、系数部分并不左右增长趋势,所以都可以忽略。
所以上面**O(2N + 2),通常我们会表示为O(N)**。
因此上面三个案例,用图示为:
再看一个更复杂的案例:
案例4:计算一个数组中的所有组合方式(O(N^2))
定义一个函数,能打印传入参数的两两组合情况。 例如:传入一个数组{"hi", "m", "a", "c"},里面有 4 个英文词语,两两组合,一共有哪些组合情况呢?
public void combine(String args[]) {
for (int i = 0; i < args.length; i++) { //step1
for (int j = i + 1; j < args.length; j++) { //step2
System.out.println(args[i] + args[j]); //step3
}
}
}
对于上面的时间复杂度:

- step1:
int i = 01 步,i++N 步,因此一共 N+1 步 - step2: 分别执行 (N) + (N-1) + (N-2) + ... + 2 + 1 = N*(N + 1) / 2
- step3: 执行了 N*(N - 1) / 2
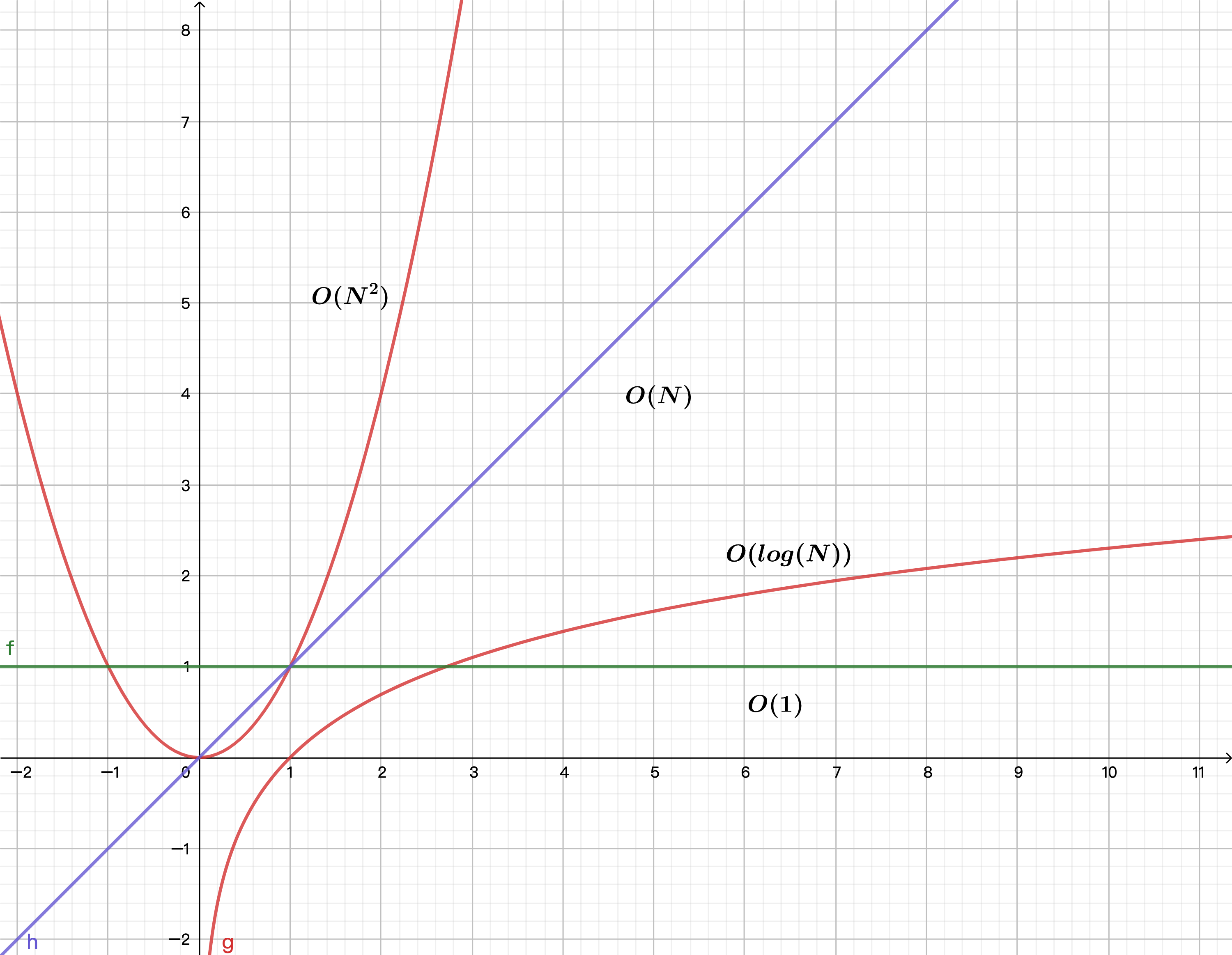
最终的结果为 N^2 + N + 1步。 注意,此次有指数出现了,称为指数时间--O(N^2 + N + 1),忽略常数为O(N^2)**。对于指数时间而言,线性时间都可以被忽略,例如:O(N^2 + N + 1),最终忽略以后的结果为 O(N^2)
把三个案例放一起,对比时间复杂度的趋势(只关注关心右上角(X > 0 区域)):
总结
从上面 3 个案例我们可以总结出规律:大 O 记法,只保留最大趋势公式,指数 > 线性 > 对数 > 常数。因此在计算时间复杂度的时候,其实并不需要一行行看代码,只需要关注for 循环嵌套情况。写代码的时候,如果能用线性复杂度的代码,替换指数复杂度的代码,那就是大大性能优化。
空间复杂度
如何计算空间复杂度?
空间复杂度和时间复杂度一样,同样遵循大 O 记法。
时间复杂度是以步作为基础单位,空间复杂度是以一个基础数据类型值当做基础单位。
O(1)
int a = 0;
int j = 0;
O(N)
int a[] = new int[n]
优先考虑时间复杂度
大多数情况只会考虑时间复杂度,因为默认计算机内存足够大的,足够使用。 大家是否听说过摩尔定律。
当价格不变时,集成电路上可容纳的元器件的数目,每隔 18-24 个月便会增加一倍,性能也将提升一倍。换而言之,每个 18-24 个月,同样大小的芯片里可存储的数据量将翻一倍。 因此完全可以忽略内存空间不够的情况。除非参与嵌入式开发,参与单片机相关的编程开发,才需要注意空间问题。
性能优化小案例1 - 二分查找
有序数组查找
如果一个数组中的值是按一定顺序进行排列的,就称为有序数组。比如数组[2, 3, 22, 75, 80, 90, 100]
如果希望完成一个函数,查找某个数字是否存在数组中。例如:22 存在数组中,索引值是 250 不存在数组中。
线性查找
同样给出最粗暴的解决方案,依次遍历整个数组,判断给定的数字是否存在。
public static int find(int[] array, int aim) {
for (int i = 0; i < array.length; i++) {
if (aim == array[i]) {
return i;
}
}
return -1;
}这种查找方法的时间复杂度为:O(N)。但还有更快的查找办法:二分查找法。
二分查找法
和猜数字游戏类似,因为数组是有序的,可以先比对中间索引值,再来缩小查找的范围。
怎么能让数组缩小呢?
为了不破坏原数组(因为原数组可能还会在其他地方使用),可以定义两个变量 left, right 分别表示数组可筛选区域左侧和右侧的索引(下标)。
代码如下:
public static int find(int[] array, int aim) {
// 初始化left = 最左侧, right = 最右侧
int left = 0;
int right = array.length - 1;
// 当left > right则表示遍历完成
while (left <= right) {
// 获取中间的值
int middle = (left + right) / 2;
int middleValue = array[middle];
if (middleValue == aim) {
// 已经找到目标
return middle;
} else if (middleValue < aim) {
// 目标在middle的右侧,重置left
left = middle + 1;
} else {
// 目标在middle的左侧,重置right
right = middle - 1;
}
}
return -1;
}| 暴力查找 | 二分法查找 | |
|---|---|---|
| 时间复杂度 | O(N) | O(log(N)) |
| 数组 100 个 | 100 | 6.64 |
| 数组 1W 个 | 1W | 13.28 |
| 数组 100W 个 | 100W | 19.93 |
从上面可以看到,数组越大,数据量越大,最终性能提升相当的明显,相差了几个量级
小提示:在 Java 中可以使用String对象compareTo方法比较字符串的先后顺序,语法规则为
str1.compareTo(str2)
结果如果是负数则表示str1排序在str2前面
举例:
import java.util.ArrayList;
import java.util.Comparator;
public class Address {
public static int find(ArrayList<String> array, String aim) {
// 初始化left = 最左侧, right = 最右侧
int left = 0;
int right = array.size();
// 当left > right则表示遍历完成
while (left <= right) {
// 获取中间的值
int middle = (left + right) / 2;
String middleValue = array.get(middle);
if (middleValue.equals(aim)) {
// 已经找到目标
return middle;
} else if (middleValue.compareTo(aim) > 0) {
// 目标在middle的左侧,重置right
right = middle - 1;
} else {
// 目标在middle的右侧,重置left
left = middle + 1;
}
}
return -1;
}
public static void main(String[] args) {
ArrayList<String> array = new ArrayList<>();
array.add("Allen");
array.add("Emma");
array.add("James");
array.add("Jeanne");
array.add("Kelly");
array.add("Kevin");
array.add("Mary");
array.add("Natasha");
array.add("Olivia");
array.add("Rose");
int result1 = find(array, "Kelly");
if (result1 == -1) {
System.out.println("Kelly 不存在名单中");
} else {
System.out.println("Kelly 存在名单中,位置是 " + result1);
}
int result2 = find(array, "Edith");
if (result2 == -1) {
System.out.println("Edith 不存在名单中");
} else {
System.out.println("Edith 存在名单中,位置是 " + result2);
}
}
}
性能优化小案例2 - 二次问题
假设给定一个数字数组,数组里面每个数字介于 0 - 10 之间,请找出里面重复的数字。
举个例子:
数字数组为:[0, 8, 2, 3, 5, 6, 2, 2, 10, 8]
重复数字为:[8, 2]
暴力破解法
每次获取一个元素,依次判断这个元素和之后的元素是否有重复,图示如下:

第一步,我们选择第一个元素 0, 判断与后面 8 个元素是否相同。 第二步,我们选择第二个元素 8, 判断与后面 7 个元素是否相同。 ... 以此类推
代码如下:
public static ArrayList<Integer> repeat(int[] array) {
ArrayList<Integer> result = new ArrayList<>();
for(int i = 0; i < array.length; i++){
// 以此判断i位置元素和后面j位置元素是否相等
for(int j = i + 1; j < array.length; j++){
if(array[i] == array[j]){
// 如果之前result没有,则进行添加
if(!result.contains(array[i])){
result.add(array[i]);
}
}
}
}
return result;
}
最终的运行结果,我们看到打印出[8, 2]和我们预期一样。
时间复杂度是多少呢?很容易算出来,两个for循环嵌套,所以是O(N^2)(此处我们还未计算containes的复杂度)。
标记法
再次阅读下题目的要求:
假设给定一个数字数组,数组里面每个数字介于 0 - 10 之间,请找出里面重复的数字。
从这个题目要求知道数组里面每个数字都是介于 0 - 10 之间。 我们是否可以先用11 长度的数组来标记 0 - 10 这 11 个数字是否存在;空 表示不存在,1 表示存在一次,2 表示存在 2 次。
如下图所示:

假设现在有一个数组为0, 2, 3,那么exists数组中索引0, 2, 3位置会被标记成 1。
那怎么判断重复呢?
一旦出现一个数字就将exists对应索引位置的值 + 1。下次如果遇到对应的位置已经为 >= 1,则表示重复了。
详细步骤:
前置

首先申请一个数组,数组名称为exists,表示数字是否存在。 数组的长度为 11,并且数组里面的值默认都为 0,表示 0 - 10 这 11 个数默认都不存在。
第一步

第一步,我们扫描到数字0,因此我们将exists数组中索引值为 0 的数字设置为 1。
exists[0] = 1
第二步

第二步,我们扫描到数字8,因此我们将exists数组中索引值为 8 的数字设置为 1。
exists[8] = 1
以此类推
第六步
第六步的时候,我们的exists数组0, 2, 3, 5, 8索引位置已经设置为 1。

扫描到原始数组第 6 位为 2,我们发现exists数组中索引为 2 的位置已经为 1 了,所以我们知道 2 这个数字重复了。
然后将2写入result的数组中,并且将2对应的索引值改为 2,表示出现过 2 次了。
后面再出现 2 该怎么办呢
这时候不能继续往result里面添加元素了,所以我们需要判断对应的标记位为 1 时,才添加到result中。
用代码来完善一下:
public static ArrayList<Integer> repeat(int[] array) {
ArrayList<Integer> result = new ArrayList<>();
int[] exists = new int[11];
for (int i = 0; i < array.length; i++) {
int value = array[i];
// 只有当前位置已经为1,标示重复,并且输出,>1情况则不输出了
if (exists[value] == 1) {
result.add(value);
}
// 用exists标示记录
exists[value]++;
}
return result;
}
很明显,从代码可以看出,一次循环就能完成题目要求,所以时间复杂度为O(N)。
同样,看看它们效率的差距:
| 暴力查找 | 标记查找 | |
|---|---|---|
| 时间复杂度 | O(N^2) | O(N) |
| 数组 100 个 | 1W | 100 |
| 数组 1W 个 | 1 亿 | 1W |
| 数组 100W 个 | 1W 亿 | 100W |
随着数组数量增加,性能差距越来也明显。
数组
计算机内存管理
计算机的程序都是运行在内存中。
内存的工作原理
我们可以简单的将内存当做寄存柜。假设我们去游泳,需要将东西先寄存起来,寄存处有几个大箱子,每个箱子都有很多抽屉。
每个抽屉里可以放一样东西,如果你有 4 样东西,就需要放在 4 个抽屉里。 每个抽屉都有自己的编号,方便你查找和记录。 接下来,你就去游泳了,当你结束的时候,再将 4 个抽屉里面的东西带走。
这其实就是计算机内存的工作原理。
每个抽屉都可以当做内存的一个存储单元,而抽屉编号可以当做每个存储单元的内存地址。

为什么连续两个方格内存地址差 8?
因为我们现在电脑基本是 64 位,64 位表示内存存储最小使用单位为64个bit,也就是8个byte。
数组 - 存储和读取
为什么数组的索引从 0 开始?
数组是计算机中最基础的数据结构,每个编程语言中基本都有数组。
数组存储
要回答上面这个问题,首先得明白数组到底是怎么在内存中存储的。
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
- 线性数据结构:表示数组中数据都是按前后这种线性顺序排列的。
- 相同数据类型:数组中的每个值的数据类型都相同。

连续内存空间
举个生活中的例子,现在有 4 个人去电影院看电影,希望坐靠前的位置并挨着坐在一排

那如果变成 5 个人了呢?那就选择第三排。

如果把每个座位当做一块内存空间,那边连续位置就相当于数组的连续内存空间。
数组读取
理解了数组的内存存储,接下来看看如何获取数组某个索引下的值?
每个数组都有对应的内存地址,将其称作为数组开始地址 --- start_address。
数组在定义的时候已经确定每个数组元素的数据类型,也就是知道每个元素需要的内存空间大小,称为 --- item_size。

那么数组里每个元素内存地址s都能被计算出来:
// 第一个元素地址
start_address
// 第二个元素地址
start_address + item_size * 1
// 第三个元素地址
start_address + item_size * 2
第 N 个元素地址公式如下:
// 第N个元素地址
start_address + item_size * (N - 1)
从这个公式可以得到两点信息:
- 数组的索引访问的时间复杂度是O(1)
- 内存地址的计算规则决定开始地址为
start_address + item_size * 0,在计算机中为了方便位置的计算,所以数组索引从 0 开始。
补充:获取数组长度
public class ArrayLengthExample {
public static void main(String[] args) {
int[] array = {1, 2, 3, 4, 5};
int length = array.length;
System.out.println("数组的长度为: " + length);
}
}数组获取索引值
public class ArrayIndexAccess {
public static void main(String[] args) {
int[] array = {10, 20, 30, 40};
int index = 2;
int element = array[index];
System.out.println("索引 " + index + " 处的元素是: " + element);
}
}数组 - 插入和删除
数组插入
往数组里面插入一个元素的速度,取决于你需要把它插入到哪个位置上。
假设为周末的事情做规划,暂定规划如下
eat breakfast // 吃早饭
shopping // 购物
have lunch // 吃午饭
have dinner // 吃晚饭
如果把安排设置一个类,预留明天 20 个任务,那么代码如下:
public class Schedule {
String[] array = new String[20];
private int size = 0;
// 内置4个安排
public Schedule(){
array[0] = "eat breakfast";
array[1] = "shopping";
array[2] = "have lunch";
array[3] = "have dinner";
this.size = 4;
}
public void print(){
for(int i = 0; i < this.size; i++){
System.out.print(this.array[i] + " ");
}
}
public static void main(String[] args) {
Schedule schedule = new Schedule();
schedule.print();
}
}
代码中内置了明天 4 个安排任务,并且设置任务数量size为 4。
尾部插入
如果现在突然想在吃完饭之后去看场电影(watch movie):
public class Schedule {
String[] array = new String[20];
private int size = 0;
// 内置4个安排
public Schedule(){
array[0] = "eat breakfast";
array[1] = "shopping";
array[2] = "have lunch";
array[3] = "have dinner";
this.size = 4;
}
public void add(String task){
this.array[this.size] = task;
this.size++;
}
public void print(){
for(int i = 0; i < this.size; i++){
System.out.print(this.array[i] + " ");
}
}
public static void main(String[] args) {
Schedule schedule = new Schedule();
schedule.add("watch movie");
schedule.print();
}
}
在尾部插入元素很容易计算,尾部插入元素内存地址为
start_address + item_size * n // n 为当前数组的个数
中间插入
如果希望在下午吃了午饭后喝一个下午茶(afternoon tea),那应该怎么处理呢?
我们知道,需要在数组中间部分插入数据,但是为了保证数组的顺序和连续的内存空间,插入地方后面部分数据,需要往后依次移动,如图所示:

一共需要几步呢?
- 移动
watch movie - 移动
have dinner - 插入
afternoon tea
如果插入在开始地方,则需要 N 步。
因此平均步数为 (1 + 2 + 3 + ... + N) / N 最终时间复杂度为O(N),也就是数组的插入时间复杂度为线性时间复杂度。
可以新增一个insert3Position在索引位置为 3 的地方,插入一项任务:
// 第三个位置插入
public void insert3Position(String task) {
// 索引值为3的地方
int index = 3;
// 第一步:从右侧开始依次右移
for (int i = this.size - 1; i >= index; i--) {
this.array[i + 1] = this.array[i];
}
// 第二步:插入元素
this.array[index] = task;
// 调整size
this.size++;
}
空间不够
上面我们讨论都是正常情况,如果空间不够了呢?我们再次回顾下电影院的例子:

当我们有 4 个朋友的时候,当前位置是满足要求的。如果突然多来了一个朋友,位置不够了,这个时候需要重新找寻满足 5 个人位置的空间。
这和数组空间不够的原理是一样的,需要通过 3 步完成:

如上图所示,我们一起移动到下一排:
- 开辟新的内存空间
- 复制原来的数组到新的内存空间
- 再进行插入操作
如果所有的内存空间都不足以存储到数组,这个时候系统就会抛出异常 --- Out Of Memory 内存不够。
举例:
public class YKDArrayList {
// 此处需要声明一个数组,作为底层存储
int[] array = new int[20];
int size = 0;
public YKDArrayList() {
}
// 获取数组的长度
public int size() {
return this.size;
}
// 数组获取某个索引值
public int get(int index) {
return this.array[index];
}
// 添加元素在末尾
public void add(int element) {
//相当于调用传入this.size
this.add(this.size, element);
}
// 添加元素在中间
public void add(int index, int element) {
if (index < 0 || index > this.size) {
return;
}
// 支持扩容
this.judgeMemory(this.size + 1);
// 元素依次右移
for (int i = this.size - 1; i >= index; i--) {
this.array[i + 1] = this.array[i];
}
// 插入元素
this.array[index] = element;
// 调整size
this.size++;
}
// 删除元素
public void remove(int index) {
if (index < 0 || index > this.size - 1) {
return;
}
// 元素依次左移
for (int i = index; i < this.size - 1; i++) {
this.array[i] = this.array[i + 1];
}
// 删除最后一个元素
this.array[this.size - 1] = 0;
// 调整size
this.size--;
}
private void judgeMemory(int size) {
// 如果内存不满足,则需要扩容
if (size > this.array.length) {
// 申明两倍空间
int[] newArray = new int[this.array.length * 2];
// 拷贝操作
this.copy(this.array, newArray);
// 新数组赋值给原数组
this.array = newArray;
}
}
// 拷贝操作
private void copy(int[] source, int[] aim) {
for (int i = 0; i < source.length; i++) {
aim[i] = source[i];
}
}
public static void main(String[] args) {
YKDArrayList ykdArrayList = new YKDArrayList();
ykdArrayList.add(1);
ykdArrayList.add(2);
ykdArrayList.add(3);
ykdArrayList.add(4);
ykdArrayList.add(0, 5);
ykdArrayList.remove(3);
}
}
数组删除
数组的删除操作和插入操作刚好相反。
如果是删除尾部元素,则直接删除;

如果是删除中间元素通过两步执行:
- 删除中间元素
- 元素右侧其他元素依次左移

因此我们可以得知数组删除的时间复杂度也为O(N)。
总结
数组优势:数组的查询数据特别快,时间复杂度是 O(1)
数组劣势:数组的插入和删除比较慢,时间复杂度是 O(N) 数组需要连续内存空间,并且会申请额外的内存空间便于其扩展,这种数据结构对内存要求比较高,利用率低。
因为这些优势和劣势,我们在高频查询,低频插入和删除的情况下,可以选择数组作为底层数据结构。同时我们知道 Java 中的ArrayList,实际上在底层就是利用数组实现的。