GaussDB的向量化处理技术
本文将深入探讨GaussDB中的向量化处理技术,涵盖其常见特性和实际应用。先详细介绍存储数据和即时数据(正在处理的数据)的按列组织格式,并阐述其优势。后通过分析SIMD(单指令多数据流)处理技术的一般原理,探讨在GaussDB中的巧妙运用。
列处理和即时数据
关系数据库管理系统(DBMS)将数据组织在表中,表包含列和行。表通常按行存储,同一行的数据存放在一起。表也可以按列存储,此时表的行被划分为行组,同一行组中同一列的数据存放在一起。
图1展示了一个员工表。在左侧,表按行组织;在右侧,表按列组织,每个行组包含两行。

图1:按行组织和按列组织的员工表
磁盘上存储的持久化数据和内存中正在处理的即时数据都可以按列组织。持久化数据的行组通常较大,旨在实现更好的压缩率和更高的IO效率。而即时数据的行组相对较小,通常只有几千行,旨在减少内存消耗并实现更好的CPU缓存效率。
GaussDB向量SQL引擎就是为即时数据的列式处理而设计的。即时数据在GaussDB向量SQL引擎中的处理单元为 VectorBatch。Vector代表单列的行组,VectorBatch 代表多个单列的行组,参见图2。
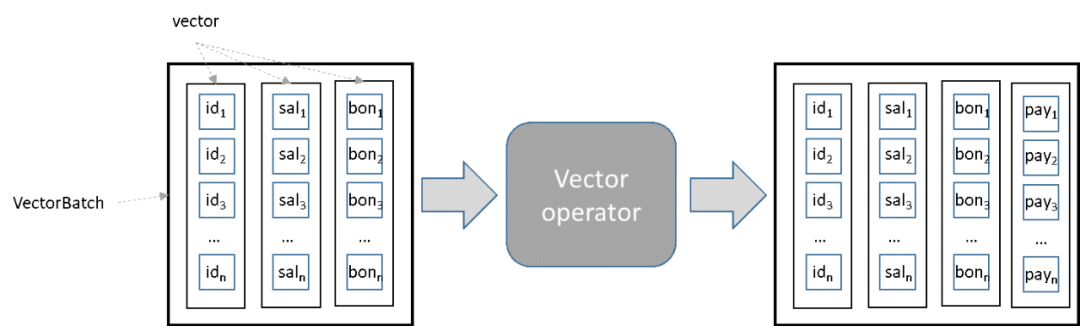
GaussDB向量SQL引擎算子接收一个VectorBatch输出一个VectorBatch。GaussDB向量SQL 引擎算子以批处理模式处理一个 SQL 查询:一次处理一批行,而不是一次处理一行。每个 VectorBatch 包含最多1000行。GaussDB 向量 SQL 引擎算子使用面向列的处理和优化来高效处理 VectorBatch。
例如,当一个算子需要计算多个列的哈希值时,它首先完成对 VectorBatch 中所有行的第一列的哈希值计算,然后是第二列,以此类推。最后,它累加所有列的哈希值。
按列存储和处理数据有几个好处:
1. 按列存储的数据可以更好地压缩
按列存储的数据可以更好地压缩。同一列的数据通常具有较高的重复率或相似的值。这些是压缩算法实现高压缩率的良好数据特征。例如,在员工表中,DeptID(部门ID)列的数据具有高重复率,可以很好地压缩。
2. 处理按列存储的数据显著减少IO
不仅因为更好的压缩率减少了IO的数量,还因为列存可以实现“延迟物化”技术。SQL 处理通常从 SCAN 算子开始,列存的SCAN 算子负责将磁盘上存储的行组转换为内存中的行组,这个过程中谓词评估可以被推入SCAN算子中以实现“延迟物化”。
例如,要处理查询“select * from employees where salary > 20”,向量SQL引擎首先读取salary列的行组,并判断行组中每一行是否满足谓词条件“salary > 20”,那些不满足谓词条件的行所对应的其他列将不会被读取。
3.批处理可以减少函数调用的次数,减少CPU开销
GaussDB 向量 SQL 引擎算子的处理单元是一个 VectorBatch,包含一千行。基于行的 SQL 引擎算子通常一次处理一行。因此,处理相同数量的数据,向量 SQL 引擎需要的函数调用次数要少得多。
4.列化数据处理可以实现更好的CPU缓存效率
列式数据可以避免CPU缓存被无关数据污染。图3展示了 GaussDB 向量 SQL 引擎在计算员工表的ID列的哈希值时的CPU缓存状态。当数据按列组织时,只有ID列数据被加载到CPU缓存中。name等列稍后才需要,所以它们必须包含在 VectorBatch 中。但在哈希值计算期间不需要它们,因此它们尚未加载到CPU缓存中。当数据按行组织时,所有列可能都必须加载到CPU缓存中,因为它们与 ID 列相邻存储。
图3:按行组织与按列组织的 CPU 缓存状态
5.列式处理方式有利于单指令多数据(SIMD)操作
在下一章节中有详细解释。
什么是SIMD
单指令多数据 (SIMD) 是60/70年代由Michael Flynn提出的计算分类之一。SIMD 描述了一种数据并行处理技术。其中单一指令可以同时应用于一组输入数据。例如,在大量使用矩阵/向量运算的计算机图形学中,专门的GPU协处理器被用来高效地执行这些计算密集型运算。
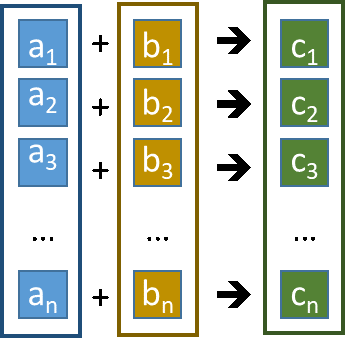
图4: 一个简单的向量加法示例图解,该操作可应用SIMD
除了GPU,SIMD处理也在CPU中得到实现。X86和ARM架构分别有支持不同程度数据并行和操作的指令集。SIMD寄存器的宽度决定了一次可以容纳的操作数数量;同时也决定了一条SIMD指令可以执行的操作数量。
例如,在X86架构中,AVX2将大多数指令扩展到256位寄存器(即:最多4个64位操作数),而AVX-512提供了使用高达512位的寄存器(即:每条指令最多8个64位操作数)。相应地,NEON指令集在ARM架构上实现了SIMD。
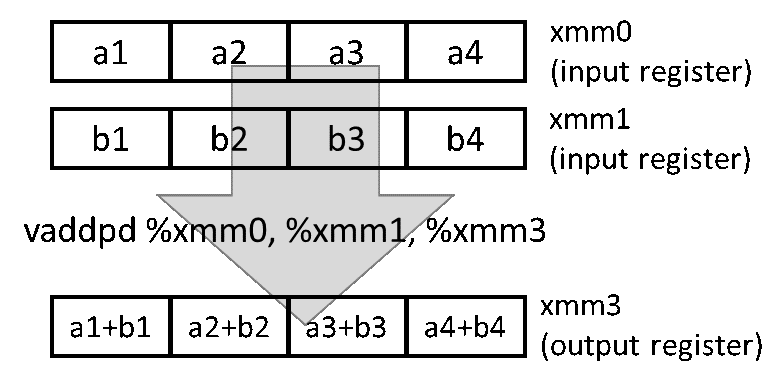
图5: SIMD 示例图解,一条指令内完成4个元素的加法
向量化处理
向量化处理用于描述列式内存布局(通常被称为向量)以及在可能的情况下对其进行的SIMD操作。让我们以一个计算示例来说明:salary + bonus èpayout。
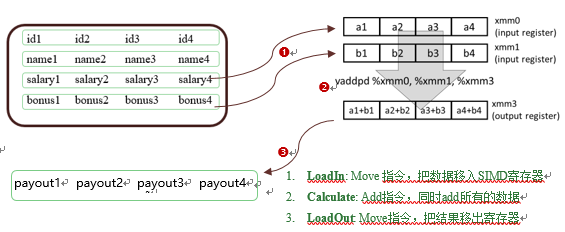
图6:向量化处理的计算示例图
虽然在行式内存布局上执行SIMD操作是可能的,但效率较低。因为 “salary” 和 “bonus”的内存位置都不连续。步骤1和3中将数据移入/移出SIMD寄存器的操作会变得更加昂贵,有时这种开销可能会抵消SIMD操作带来的所有潜在速度提升。这就是向量内存布局和SIMD常常密不可分的原因。
GaussDB中的向量化处理
自动向量化
GaussDB是用C/C++实现的,C/C++可以支持多种方法在目标硬件上使用SIMD指令。其中两个方法是使用内联汇编和内部函数,尽管它们给程序员提供了精细的控制,但编程更加困难(尤其是汇编)。
此外,这两个方法都是平台相关的。还有一个方法是利用编译器的自动向量化,这个方法让现代编译器在为目标硬件平台编译时能够自动优化某些代码。
只要有可能,程序员就可以编写代码来帮助/建议编译器使其可向量化/SIMD化。以下是几个例子:

图7:代码帮助编译器使GaussDB自动向量化/SIMD化
关于GCC和CLANG中的自动向量化,另见参考文献1和2。
GaussDB 旨在尽可能利用自动向量化,以充分发挥编译器生成目标硬件可执行文件的能力,同时保持代码的平台独立性。在特殊情况下,如果编译器无法生成我们想要的代码,内部函数将作为一种后备方法。
启用快速路径
在某些情况下,SIMD无法应用于给定的输入数据/向量。例如,编译器自动向量化通常要求循环必须是无分支的。然而,分支在输入向量中进行空值/空检查时很常见。
为了最大化SIMD向量化的机会,我们首先对输入数据/向量执行条件检查,如果满足可以应用SIMD的条件,就会调用专门的"快速路径",否则就回退到常规路径。在空值/空检查的情况下,由于空值标志也是以列/向量格式存在,检查本身也是向量化的。
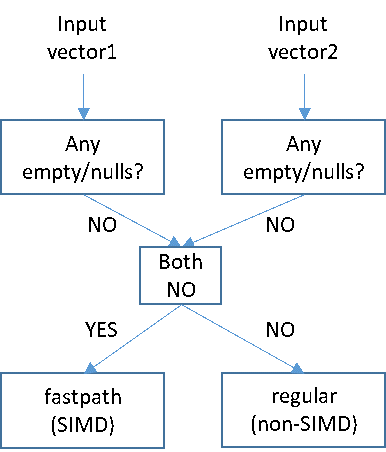
图8:最大化SIMD向量化启用快速路径示意图
此外,这种方法是按每个VectorBatch应用的,这意味着如果空值 (empty) 或 null 值很稀疏,大多数计算将利用快速路径,只有少数会回退到常规代码路径。
处理不同的数据类型
为了处理不同的数据类型,模板类可以为不同的操作数类型组合生成代码。编译器将尽可能自动向量化。
向量适配器
GaussDB实现了 '向量适配器' (Vector Adapter),原本按行组织的数据也可以利用GaussDB向量SQL引擎的优势。例如,以下查询计划显示,在扫描完按行组织的表(lineitem表)后,这些行被 '向量适配器' 转换成 VectorBatch,然后GaussDB向量SQL引擎接管并继续处理查询。在这个查询中使用向量引擎是有益的,因为进入 ' Hash Aggregate' 算子的数据量很大。
Row Adapter
-> Vector Sort
Sort Key: l_returnflag, l_linestatus
-> Vector Hash Aggregate
Group By Key: l_returnflag, l_linestatus
-> Vector Adapter(type: BATCH MODE)图9:GaussDB'向量适配器' 代码实现
性能结果
作为GaussDB最新版本的一部分,使用SIMD向量化的优化被添加到过滤器 (filter) 和表达式 (expression) 计算中。相比之前的实现显示出良好的性能提升。下面是与基线版本的性能对比,测试使用TPC-H SF=100数据库进行,下图显示Q1、Q6、Q9和Q15有显著改进;最高达到3倍的提升。

图10:GaussDB最近版本添加SIMD向量化前后的性能对比。
基准测试在X86机器上运行,并行度(query_dop)为 48;
使用TPC-H SF=100,浮点数值类型为双精度 (double)
引用
文献1:GCC 中的自动向量化
https://gcc.gnu.org/projects/tree-ssa/vectorization.html
文献2:LLVM 中的自动向量化
https://llvm.org/docs/Vectorizers.html