【命令操作】Linux三剑客之awk详解 _ 统信 _ 麒麟 _ 方德
原文链接:【命令操作】Linux三剑客之awk详解 | 统信 | 麒麟 | 方德
Hello,大家好啊!今天带来一篇关于Linux三剑客之awk命令详解的文章。在文本处理工具中,awk以其强大的文本筛选、格式化和数据处理功能而闻名。它能够在处理结构化文本和日志分析时快速提取信息、筛选数据,甚至能实现小型脚本的功能,非常适合Linux系统管理员和开发者。
本文将详细介绍awk命令的用法和常见应用场景,帮助大家掌握这款功能丰富的文本处理利器!欢迎大家分享转发,点个关注和在看吧!
什么是awk?
awk是一款编程语言,专门用于文本处理和格式化输出。它逐行扫描文件,根据用户设定的模式或条件对每一行进行处理,能够从文本中提取所需的字段并进行计算操作,是处理结构化文本(如表格、CSV文件)的理想工具。
1.基本语法
awk '条件 {动作}' 文件名
awk会逐行读取文件,匹配满足条件的行,然后对这些行执行指定的动作。
示例文件
以下示例基于一个名为pdsyw.txt的文件内容:
1 Alice 85
2 Bob 90
3 Carol 78
4 Dave 92
每行包含3列:ID、姓名和分数。
2.基本用法
显示文件的所有内容:
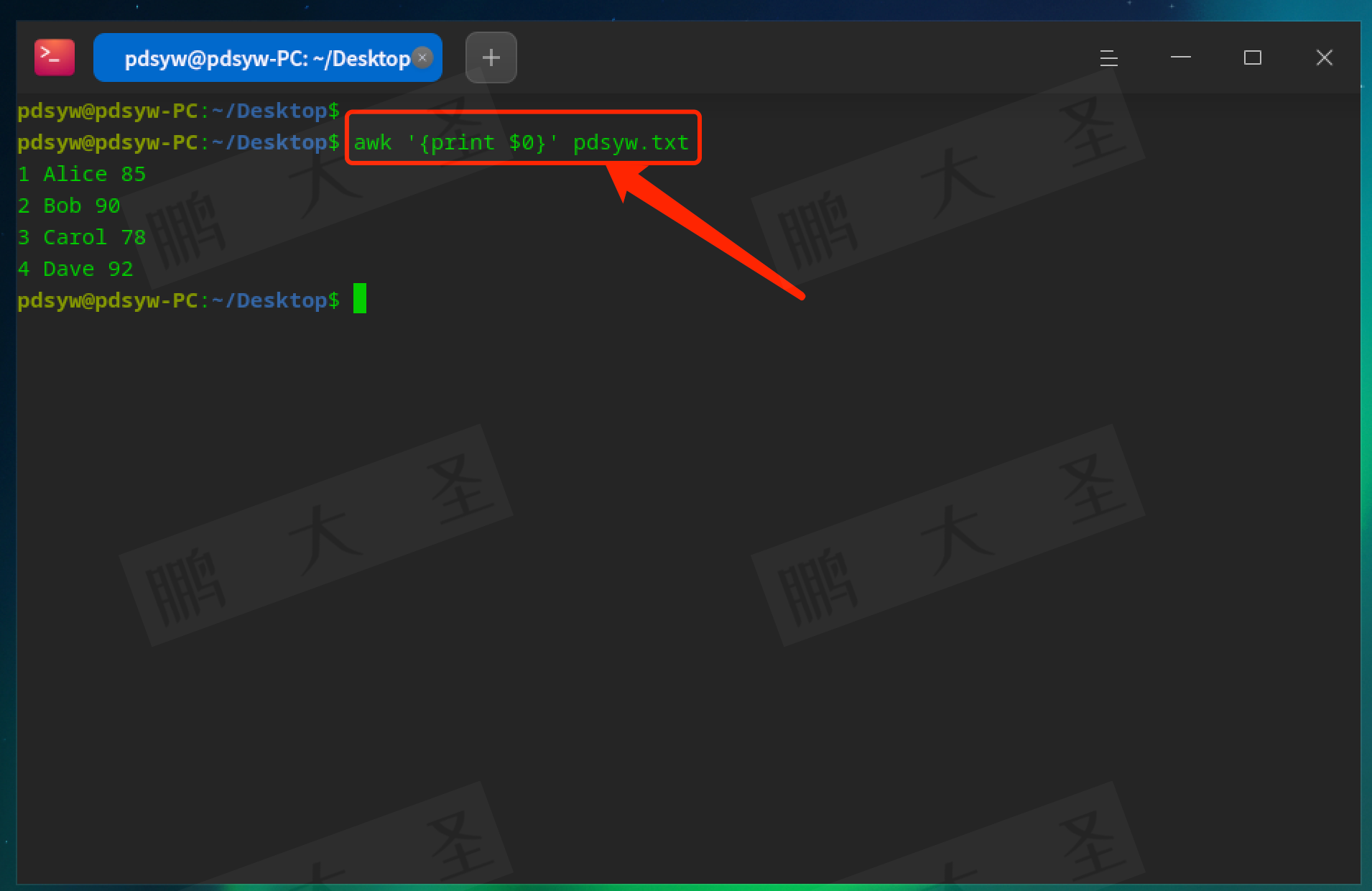
pdsyw@pdsyw-PC:~/Desktop$ awk '{print $0}' pdsyw.txt
$0代表当前整行内容,print $0会输出文件的每一行。
指定输出某些列:
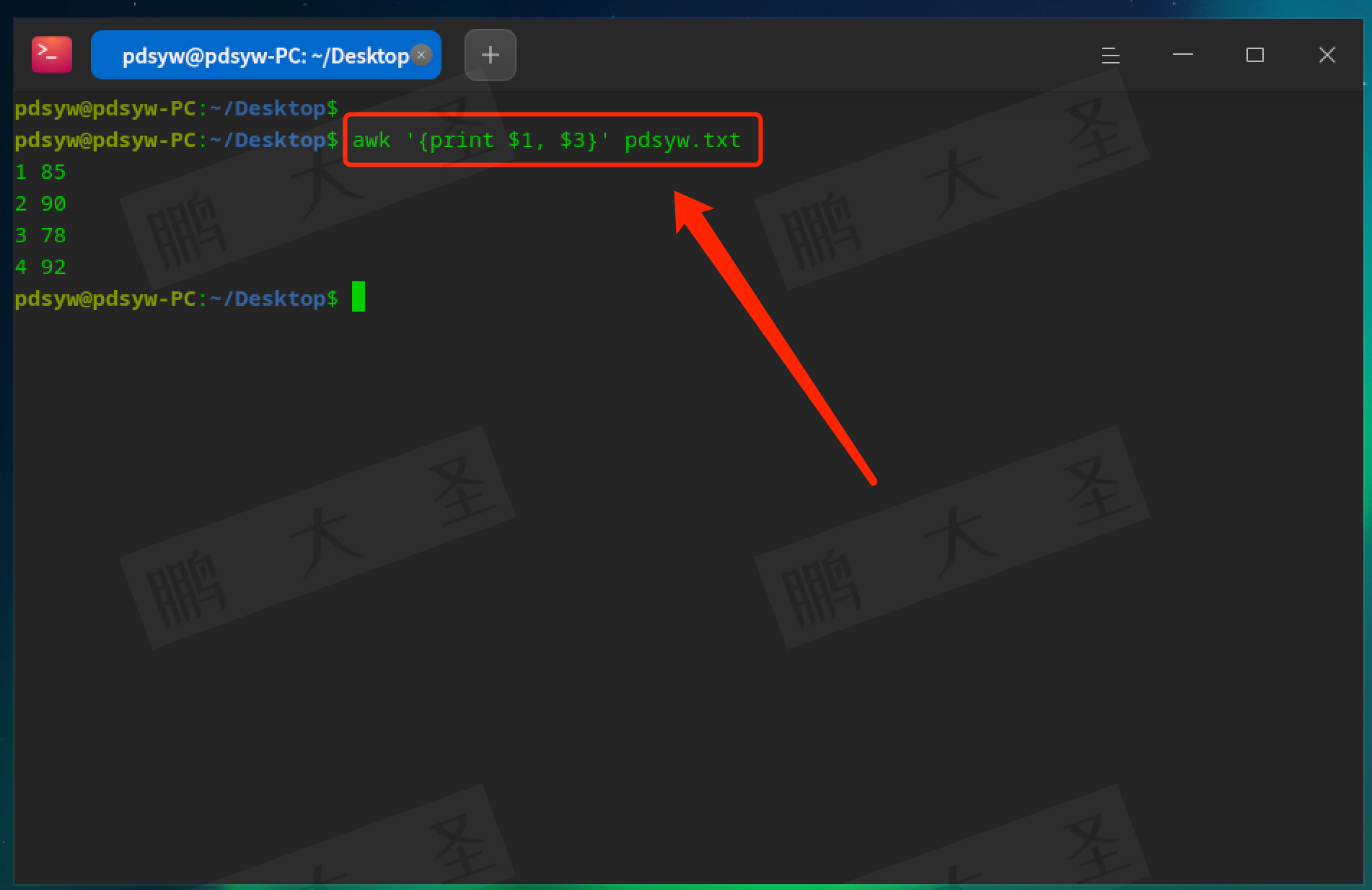
pdsyw@pdsyw-PC:~/Desktop$ awk '{print $1, $3}' pdsyw.txt
$1和$3分别表示第一列和第三列,这个命令会输出ID和分数。
输出带分隔符的内容:
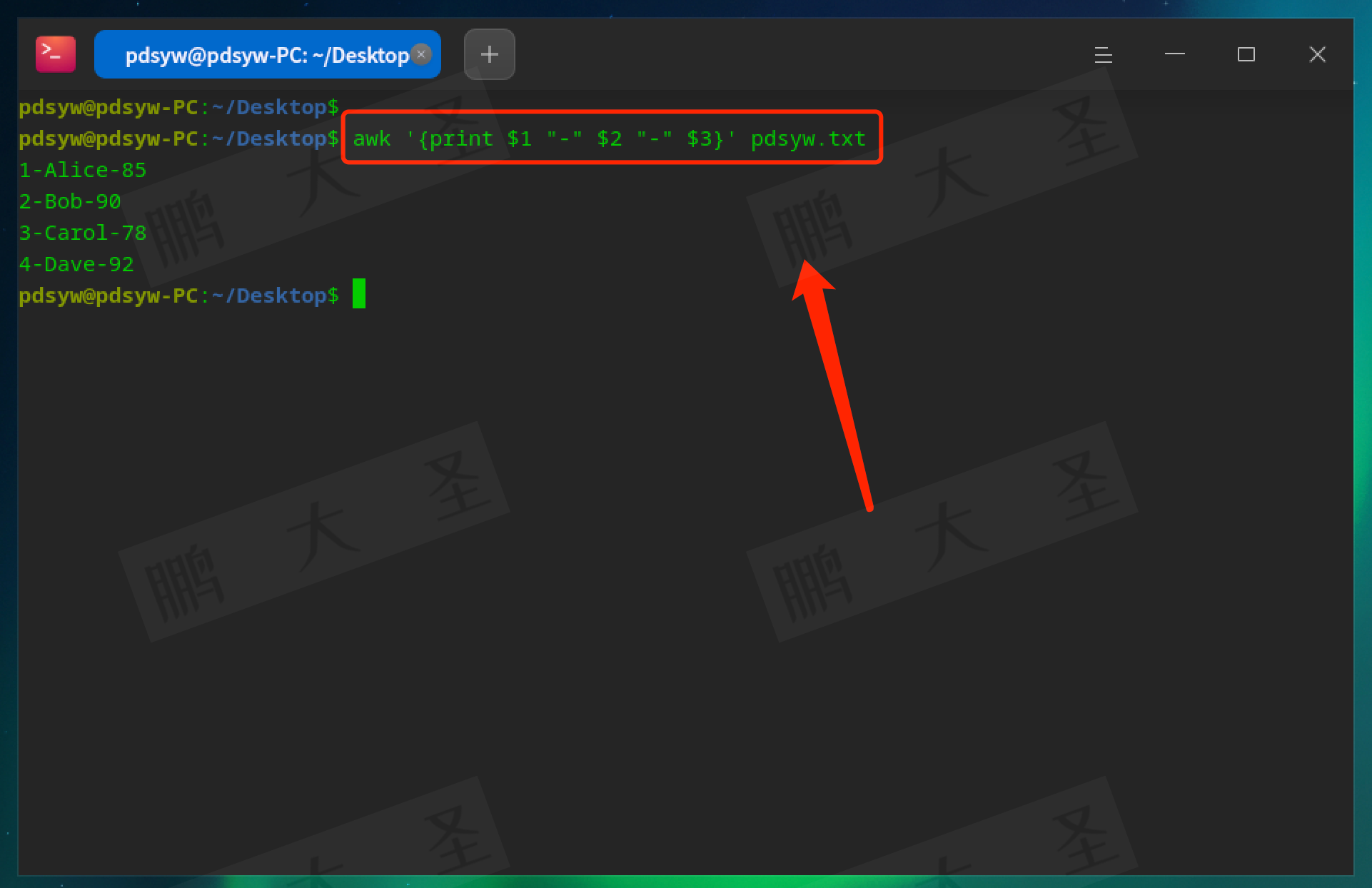
pdsyw@pdsyw-PC:~/Desktop$ awk '{print $1 "-" $2 "-" $3}' pdsyw.txt
会在各列之间输出“ - ”分隔符。
3.常用选项
-F:指定输入的分隔符(默认是空格或制表符)。
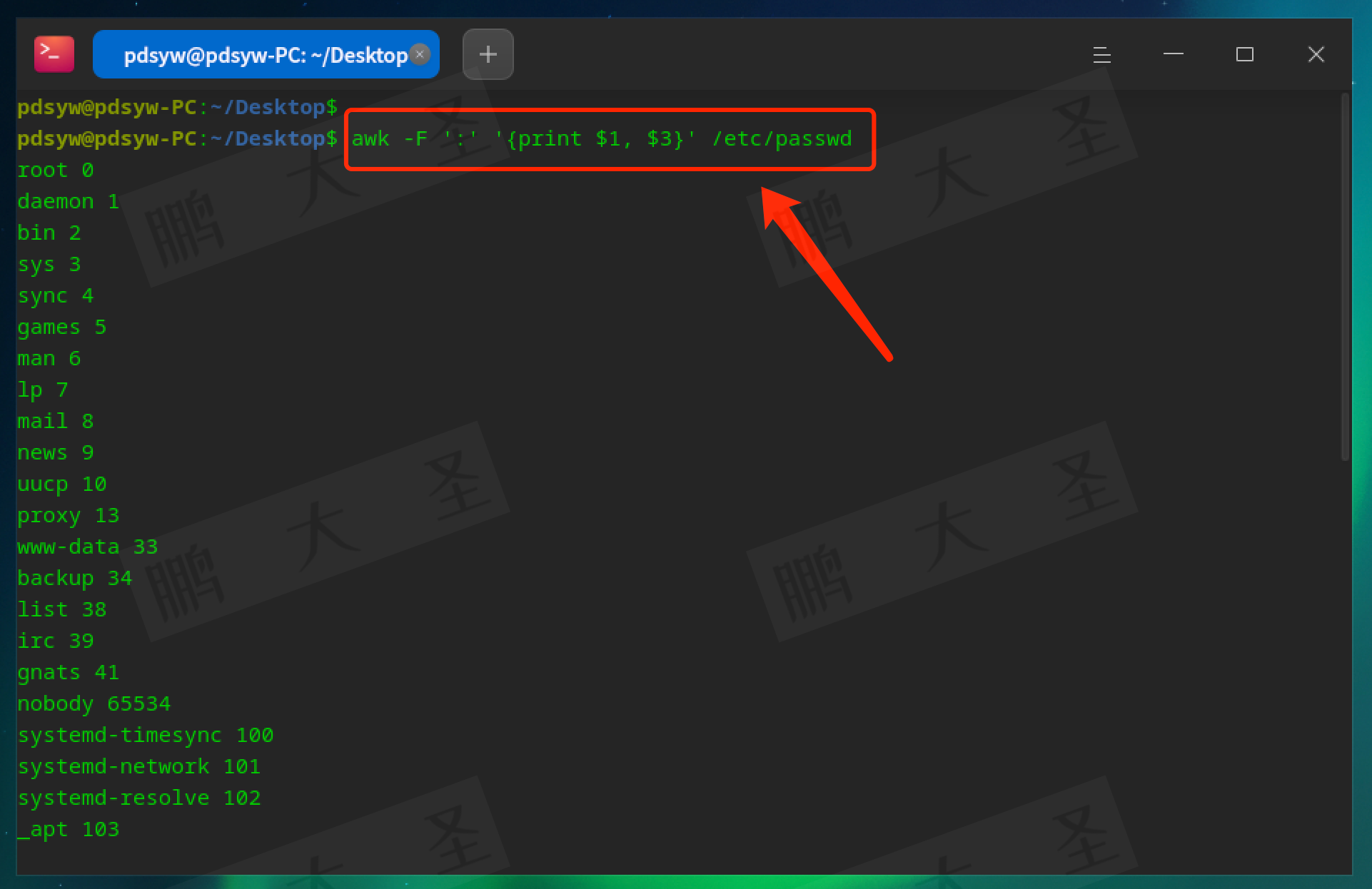
pdsyw@pdsyw-PC:~/Desktop$ awk -F ':' '{print $1, $3}' /etc/passwd
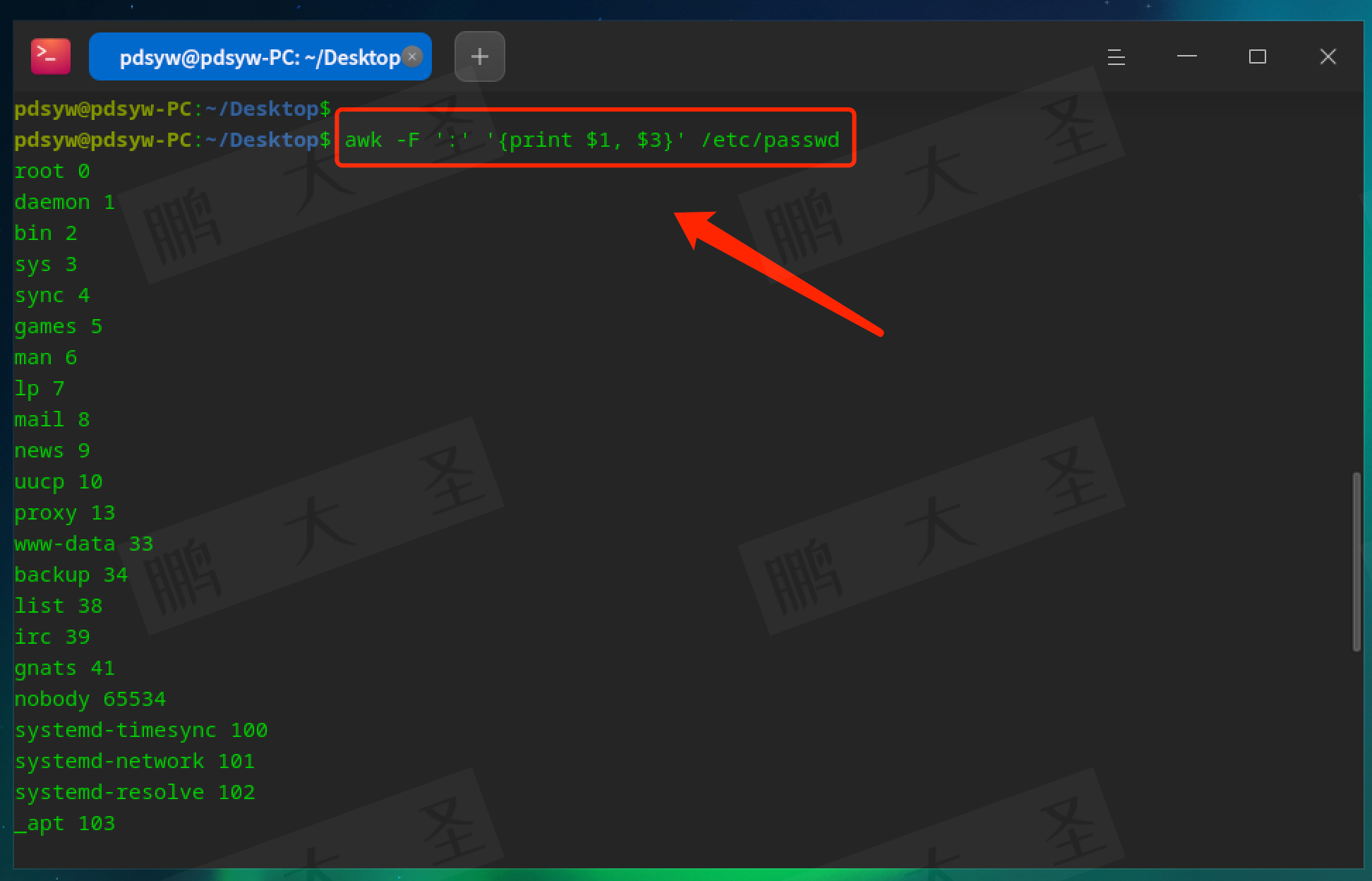
以冒号:为分隔符,输出第一列和第三列内容。
-v:定义变量,用于传入自定义的值。
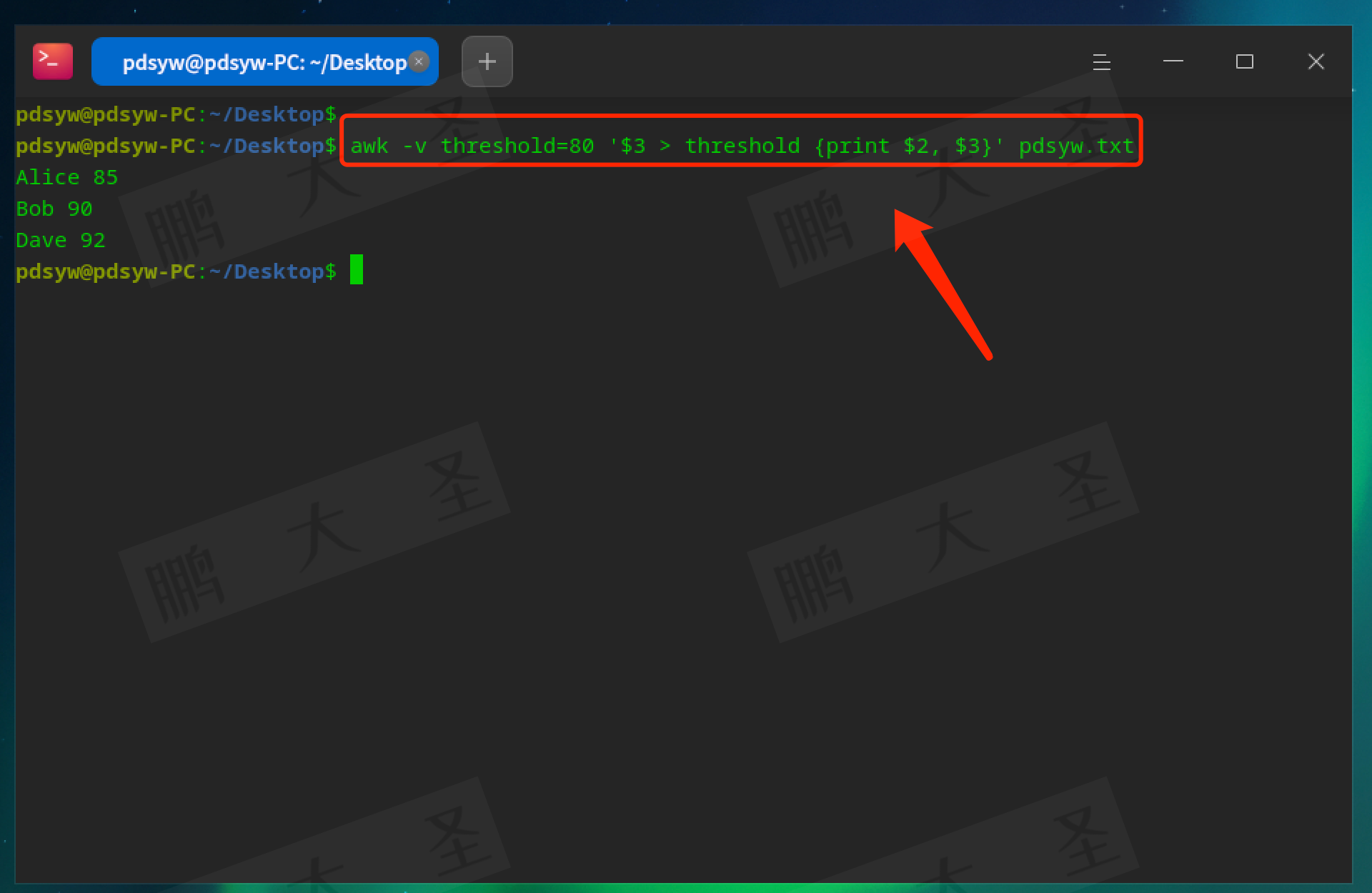
pdsyw@pdsyw-PC:~/Desktop$ awk -v threshold=80 '$3 > threshold {print $2, $3}' pdsyw.txt
定义一个名为threshold的变量,将其值设为80。然后输出分数大于80的学生姓名和分数。
4.条件判断
基于数值的条件:
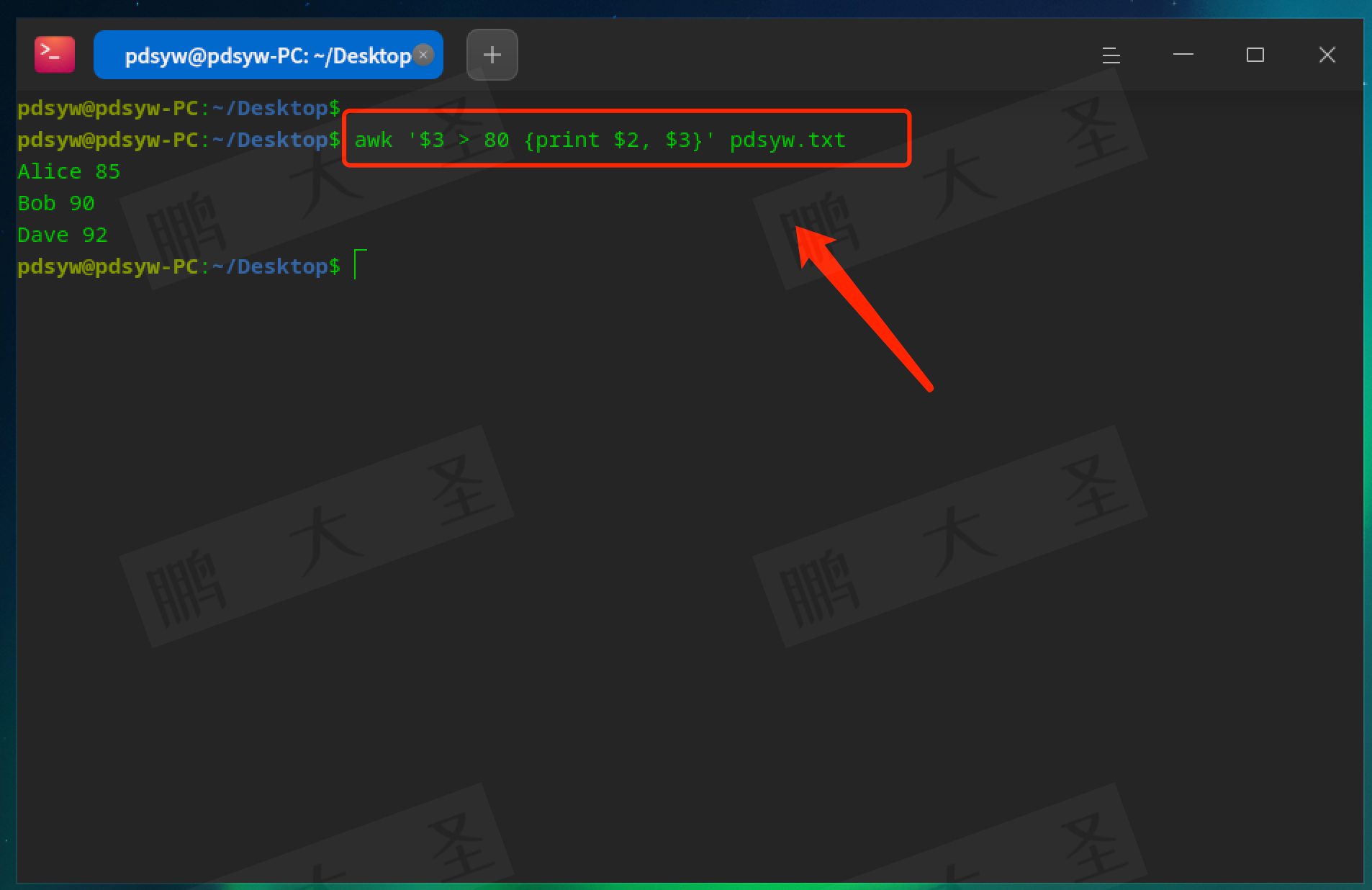
pdsyw@pdsyw-PC:~/Desktop$ awk '$3 > 80 {print $2, $3}' pdsyw.txt
输出分数大于80的学生姓名和分数。
基于字符串的条件:
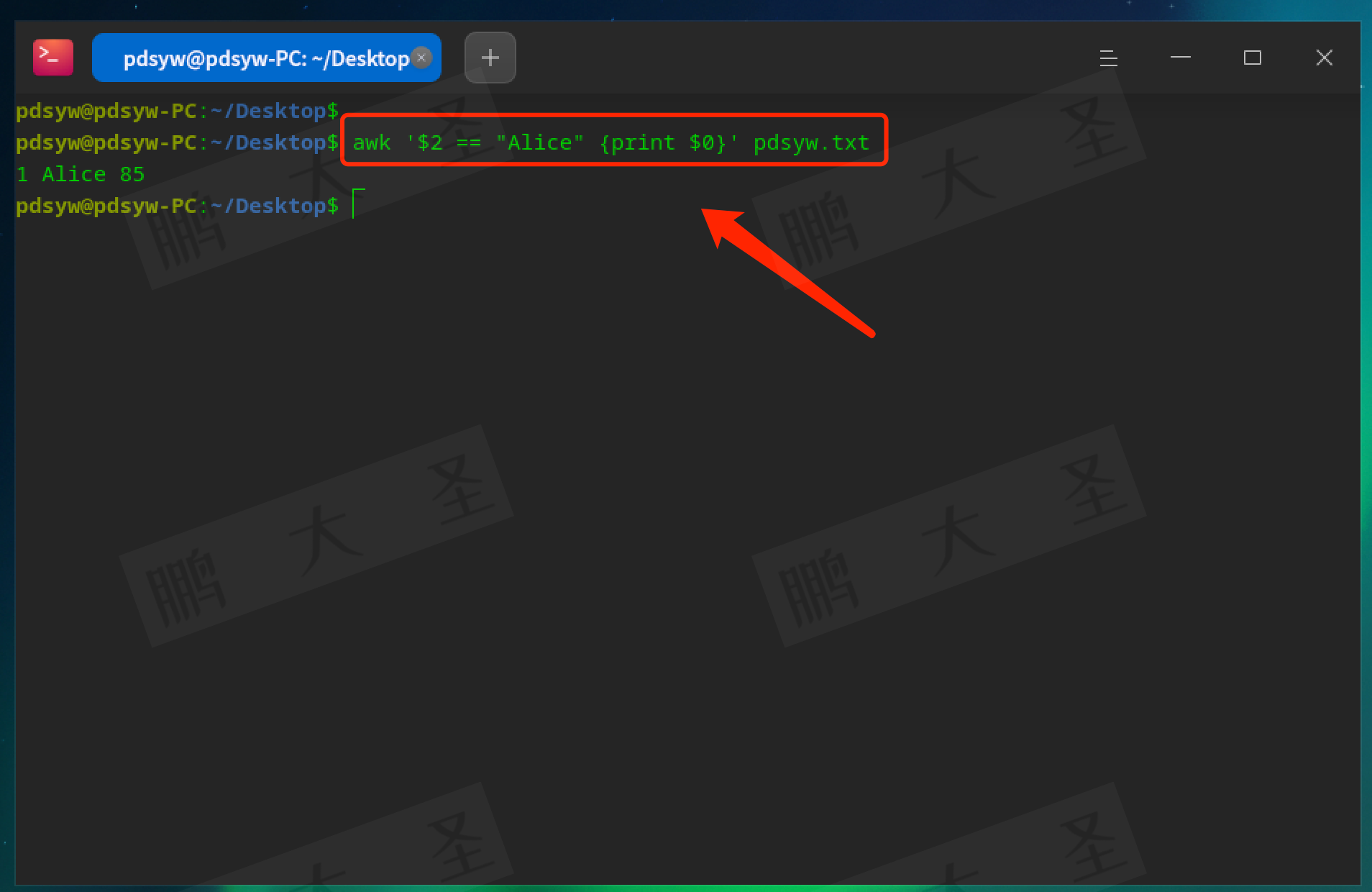
pdsyw@pdsyw-PC:~/Desktop$ awk '$2 == "Alice" {print $0}' pdsyw.txt
输出姓名为Alice的行。
使用逻辑操作符:
&&:表示“与”。
pdsyw@pdsyw-PC:~/Desktop$ awk '$3 > 80 && $3 <= 90 {print $2, $3}' pdsyw.txt
输出分数大于80且小于等于90的学生姓名和分数。

||:表示“或”。
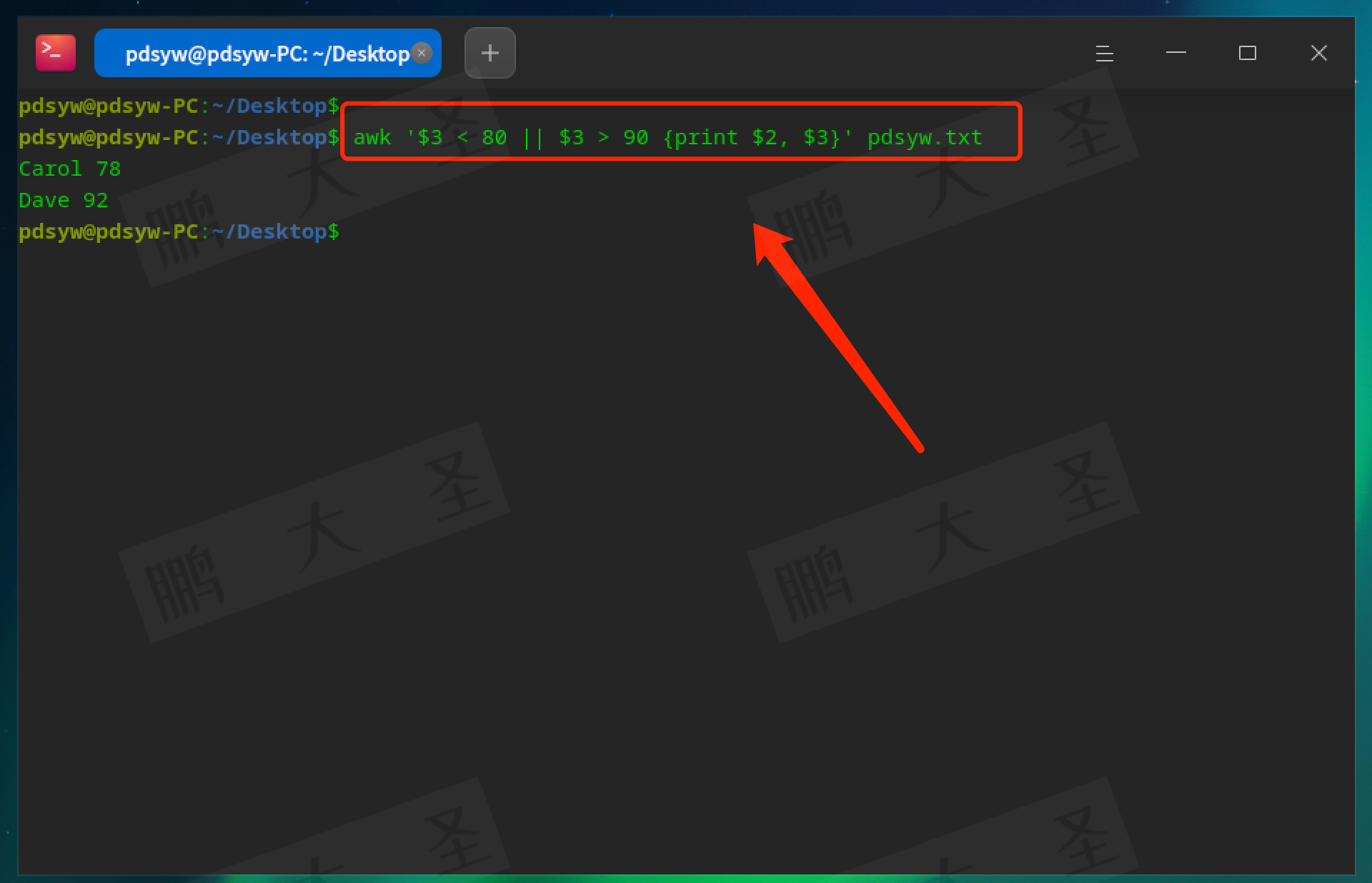
pdsyw@pdsyw-PC:~/Desktop$ awk '$3 < 80 || $3 > 90 {print $2, $3}' pdsyw.txt
输出分数小于80或大于90的学生姓名和分数。
5.内置变量
awk有一些常用的内置变量,可以在脚本中直接使用:
NR:当前处理的行号。
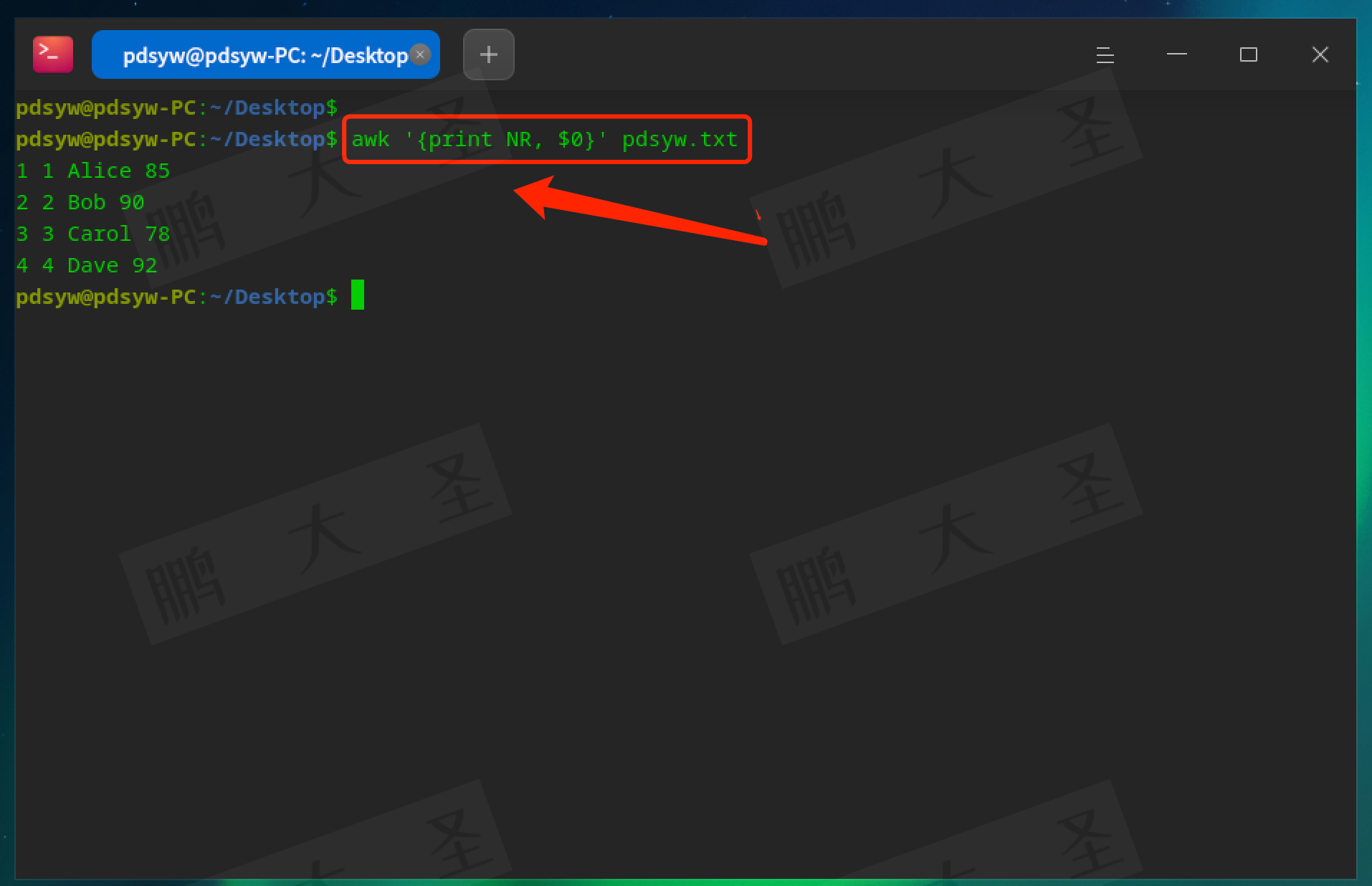
pdsyw@pdsyw-PC:~/Desktop$ awk '{print NR, $0}' pdsyw.txt
输出每行的行号。
NF:当前行的字段数(列数)。
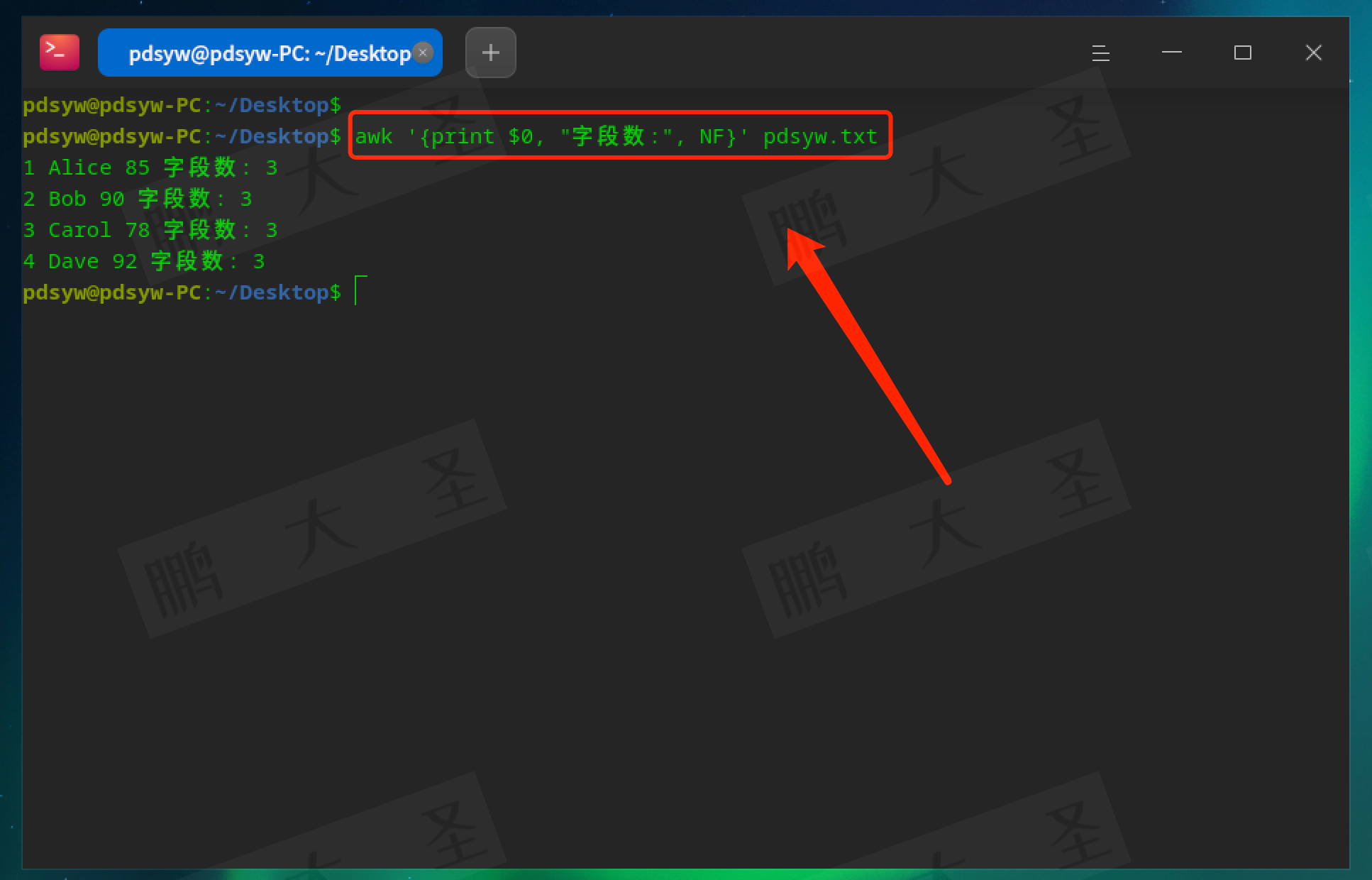
pdsyw@pdsyw-PC:~/Desktop$ awk '{print $0, "字段数:", NF}' pdsyw.txt
输出每行的字段数。
FS:输入字段分隔符(默认是空格)。
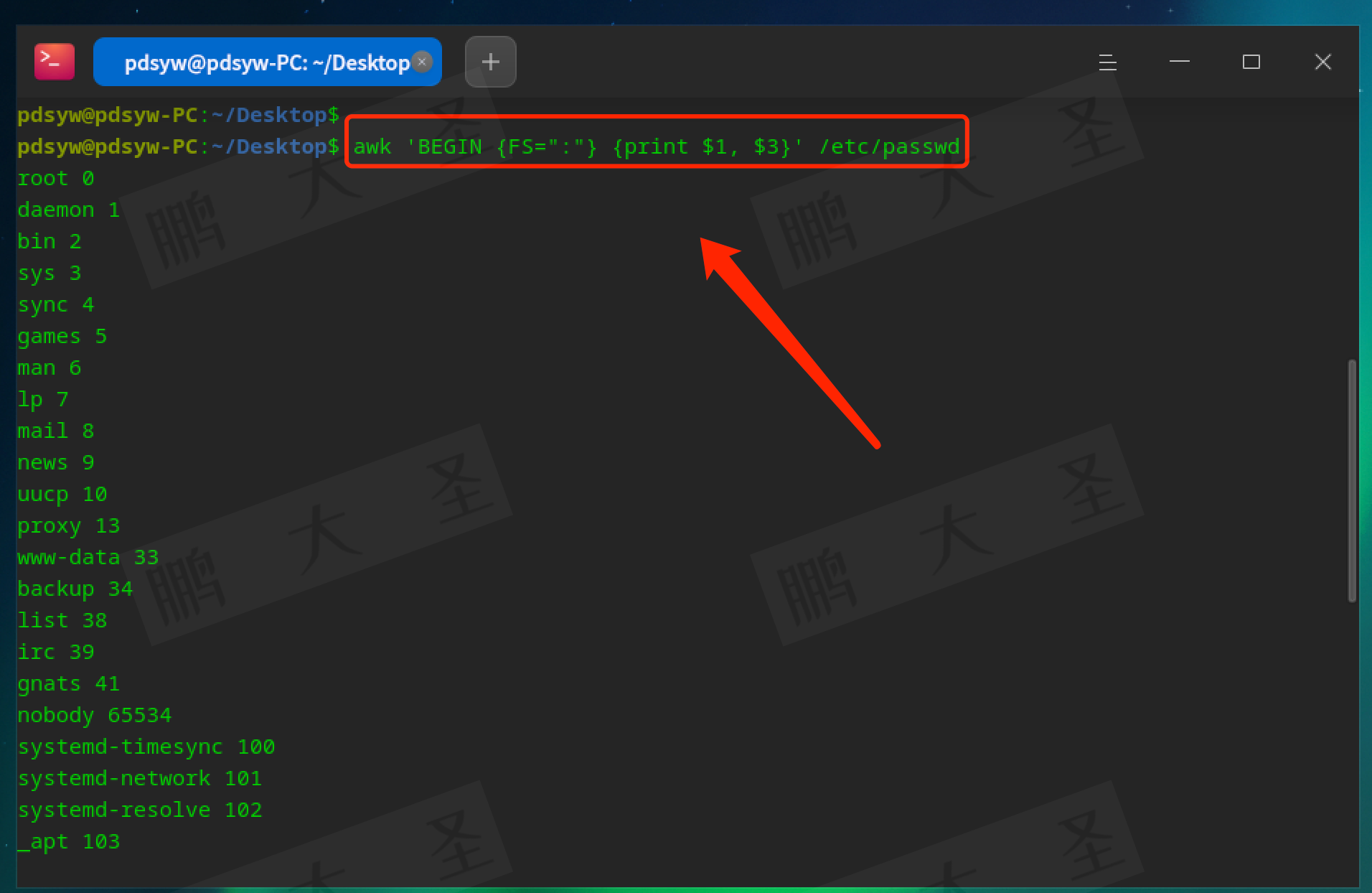
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {FS=":"} {print $1, $3}' /etc/passwd
在BEGIN块中设置FS为冒号,用于以冒号分隔字段。
OFS:输出字段分隔符(默认是空格)。
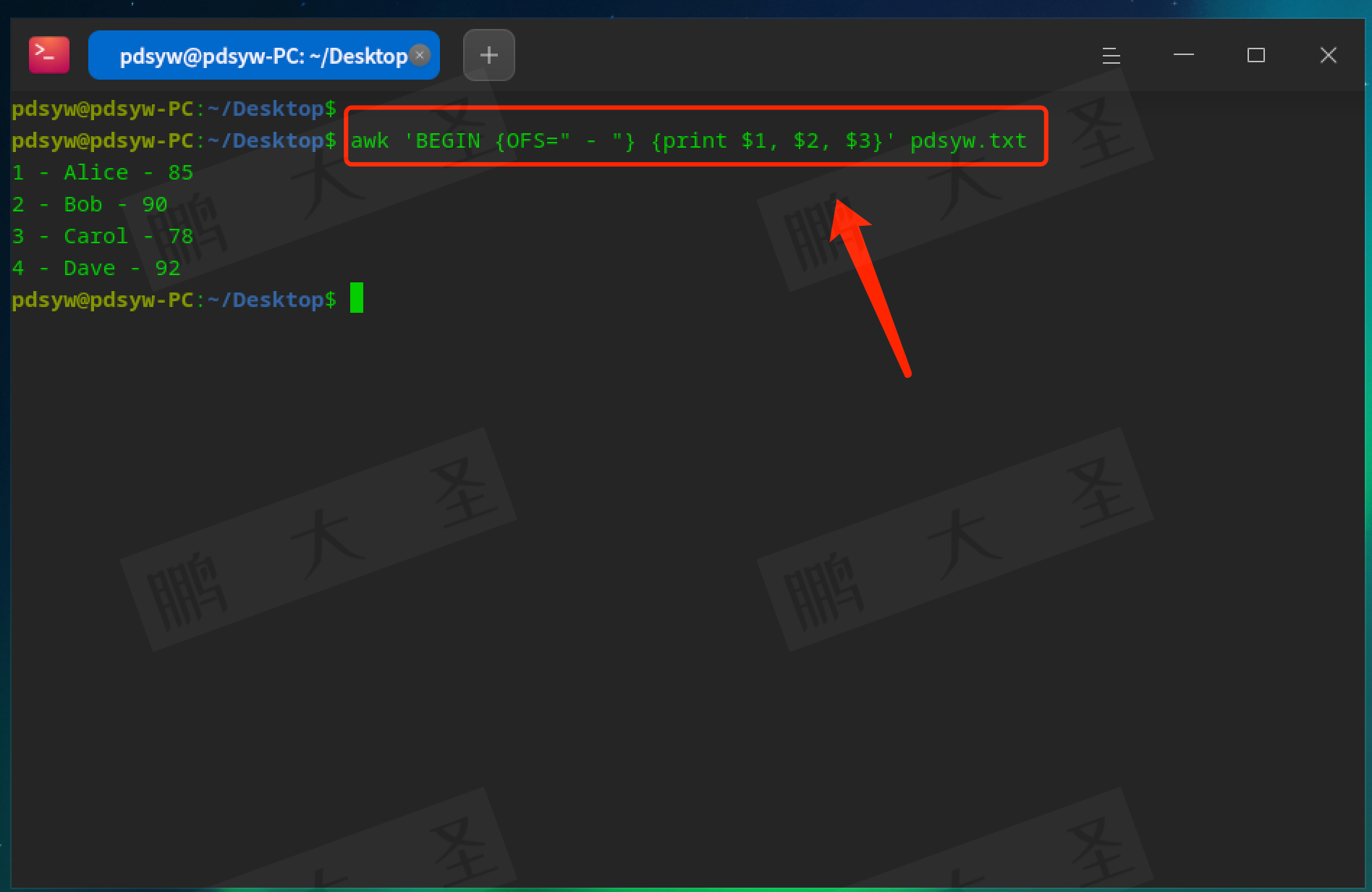
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {OFS=" - "} {print $1, $2, $3}' pdsyw.txt
在输出时使用“ - ”作为分隔符。
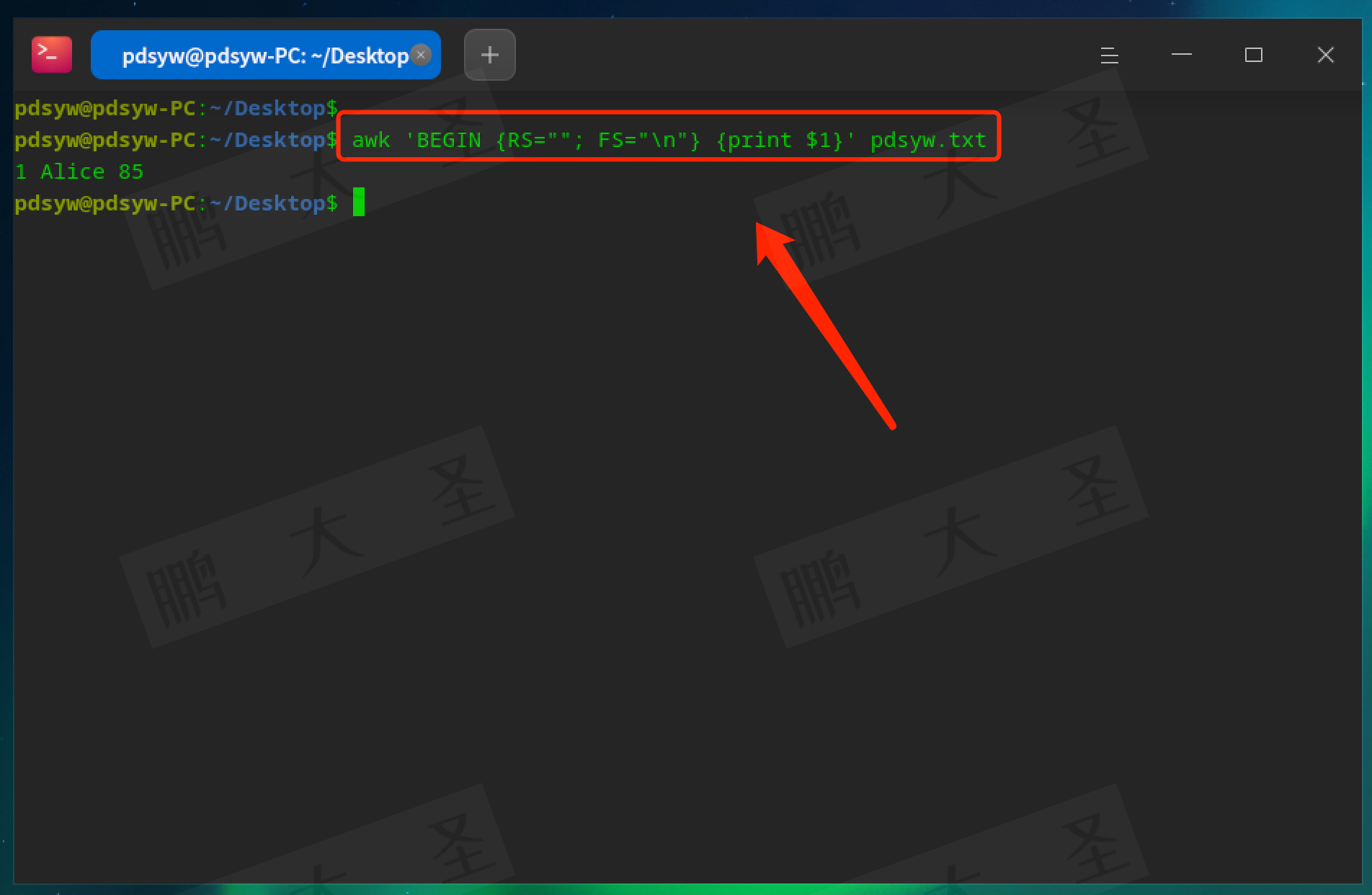
RS:输入记录分隔符(默认是换行符)。
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {RS=""; FS="\n"} {print $1}' pdsyw.txt
将整段文本当作一条记录处理,以空行作为记录分隔符。
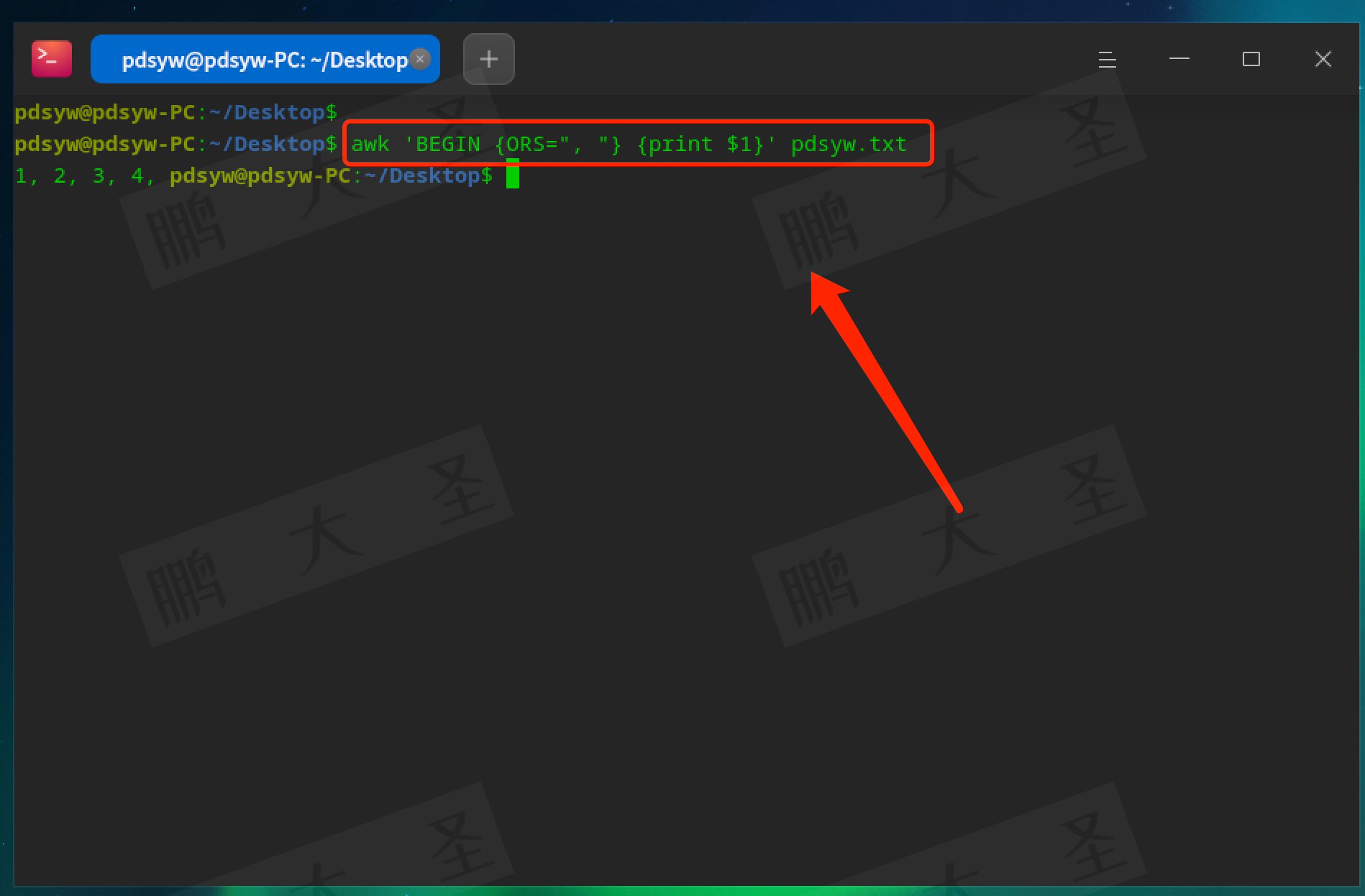
ORS:输出记录分隔符(默认是换行符)。
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {ORS=", "} {print $1}' pdsyw.txt
将输出的每条记录用逗号和空格分隔。
6.内置函数
awk支持许多常用的内置函数,包括数学、字符串和时间处理函数。
字符串函数:
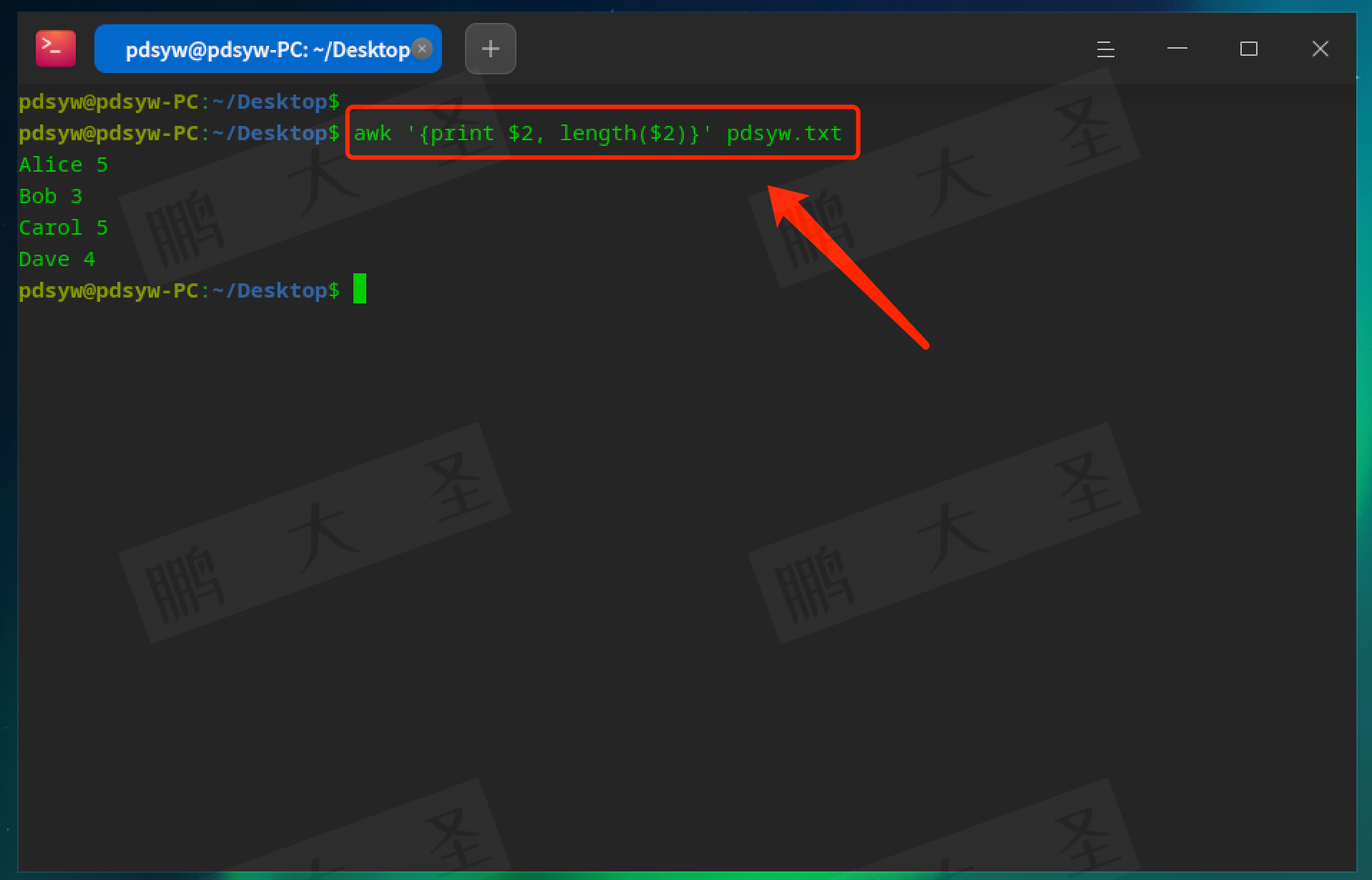
length:返回字符串长度。
pdsyw@pdsyw-PC:~/Desktop$ awk '{print $2, length($2)}' pdsyw.txt
输出每个姓名及其长度。
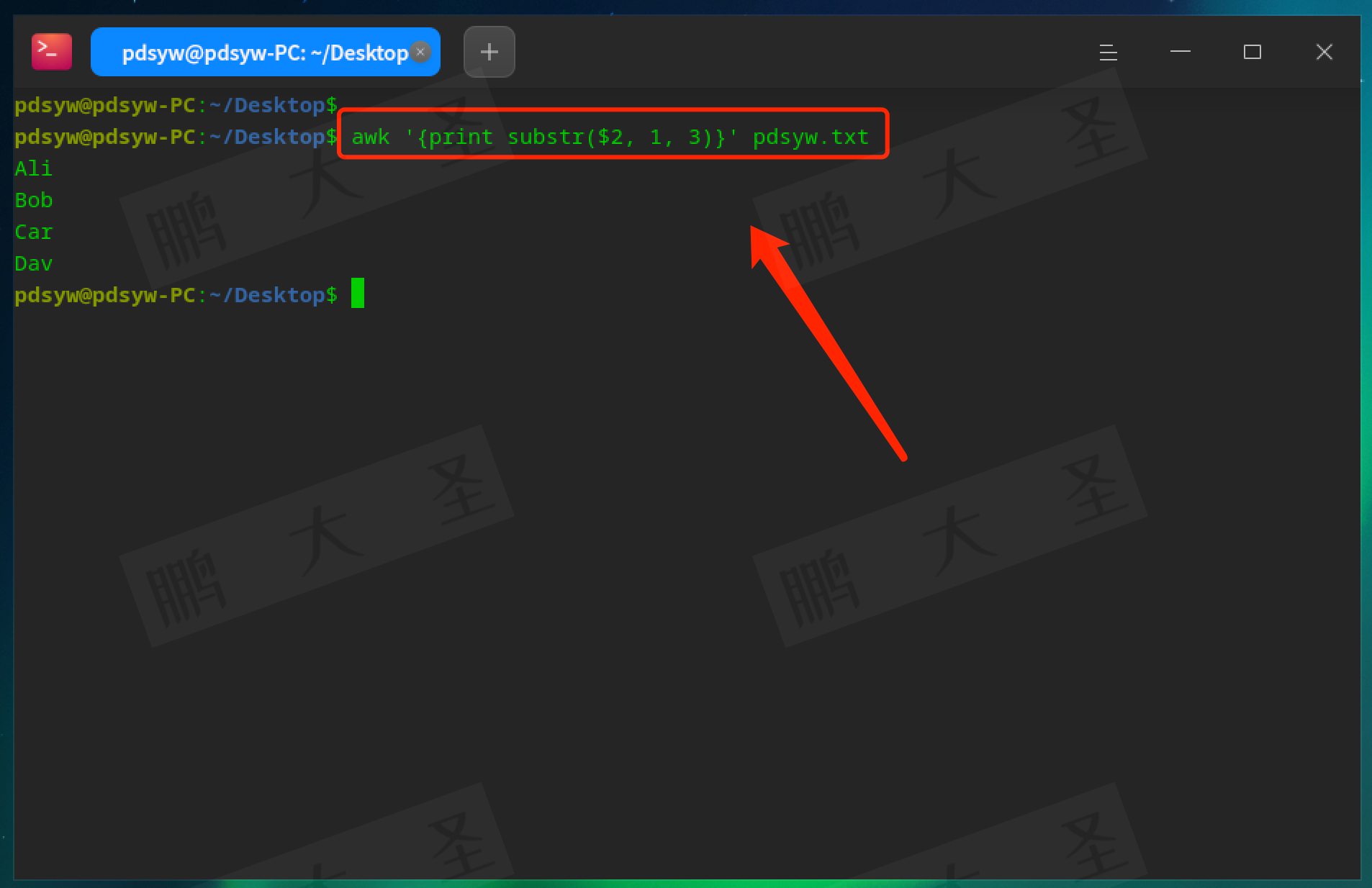
substr:截取字符串。
pdsyw@pdsyw-PC:~/Desktop$ awk '{print substr($2, 1, 3)}' pdsyw.txt
输出每个姓名的前三个字符。
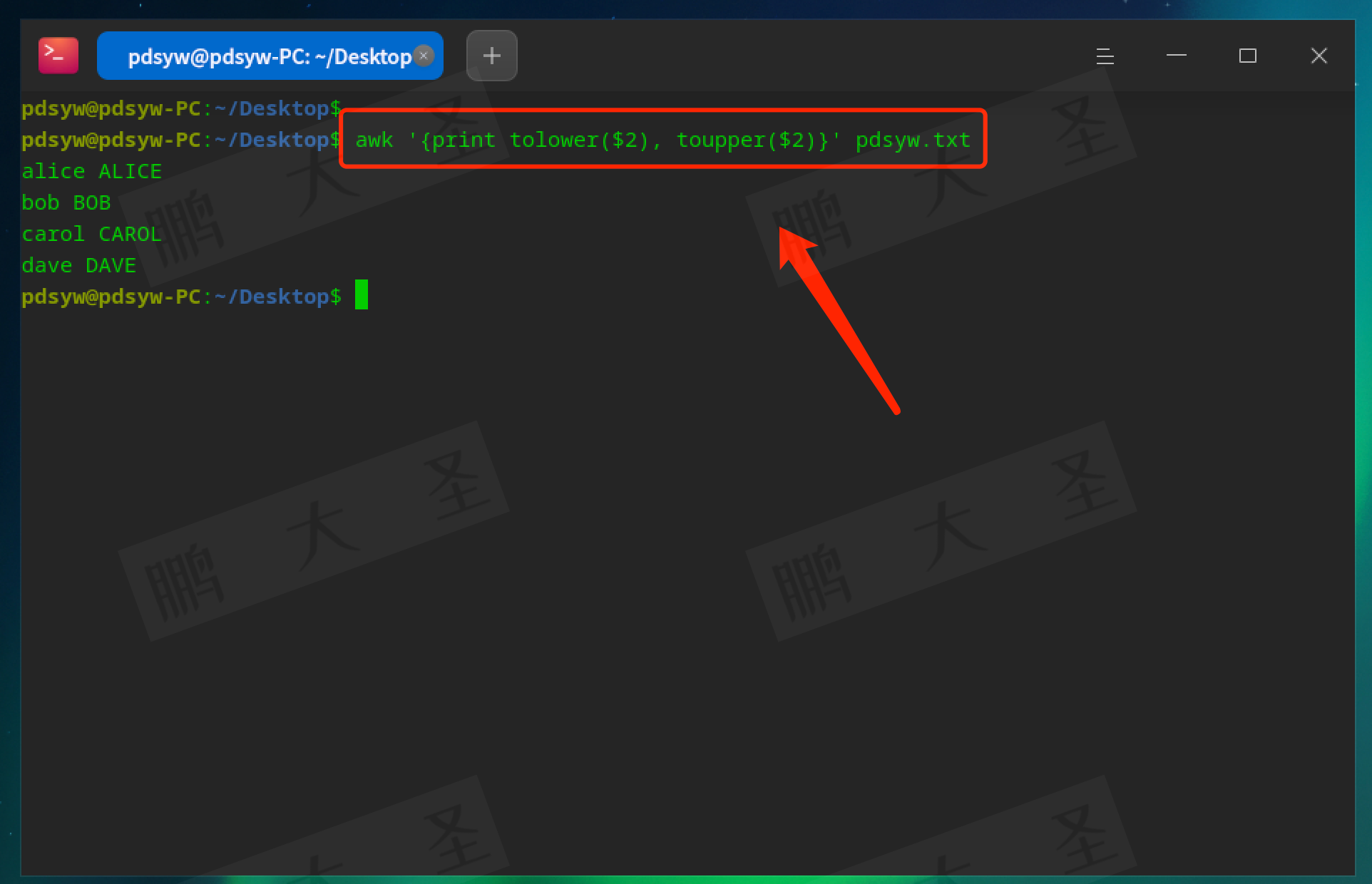
tolower 和 toupper:转换大小写。
pdsyw@pdsyw-PC:~/Desktop$ awk '{print tolower($2), toupper($2)}' pdsyw.txt
输出姓名的小写和大写形式。
数学函数:
int:取整。
pdsyw@pdsyw-PC:~/Desktop$ awk '{print int($3 / 10)}' pdsyw.txt
输出每个分数除以10后的整数部分。

sqrt:计算平方根。
pdsyw@pdsyw-PC:~/Desktop$ awk '{print sqrt($3)}' pdsyw.txt
输出每个分数的平方根。

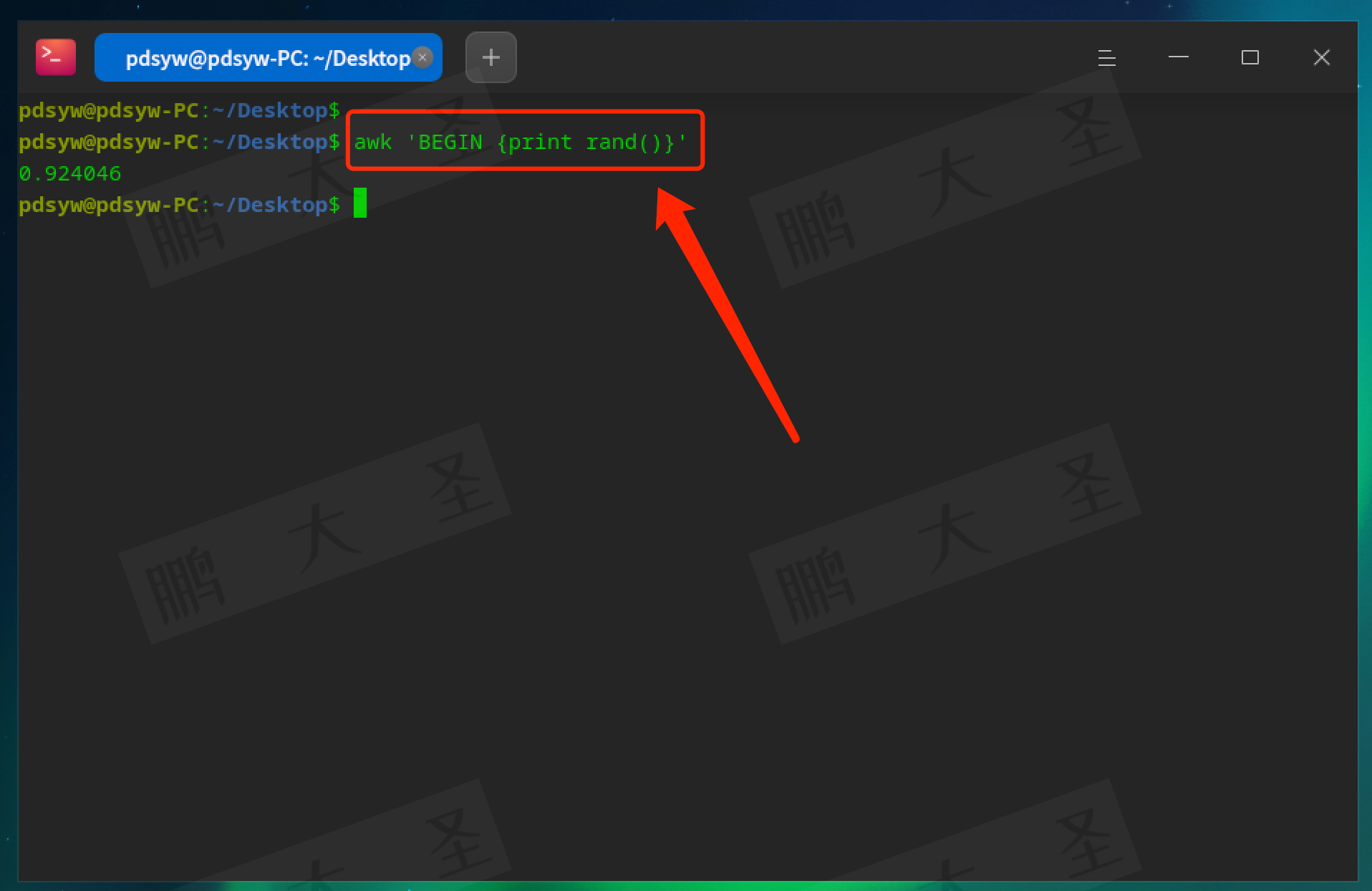
rand:生成随机数。
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {print rand()}'
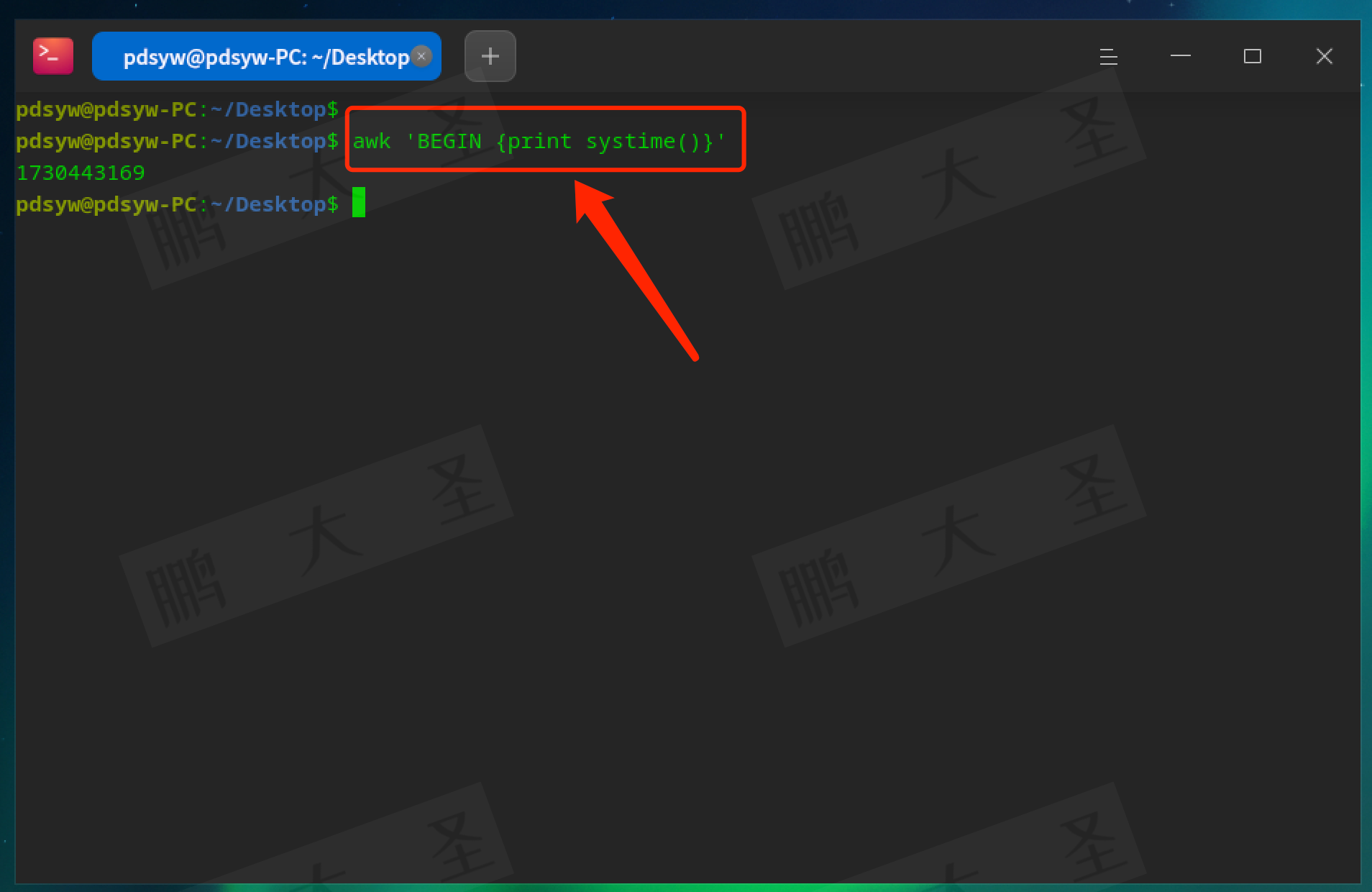
时间函数:
systime:获取当前时间的时间戳。
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {print systime()}'
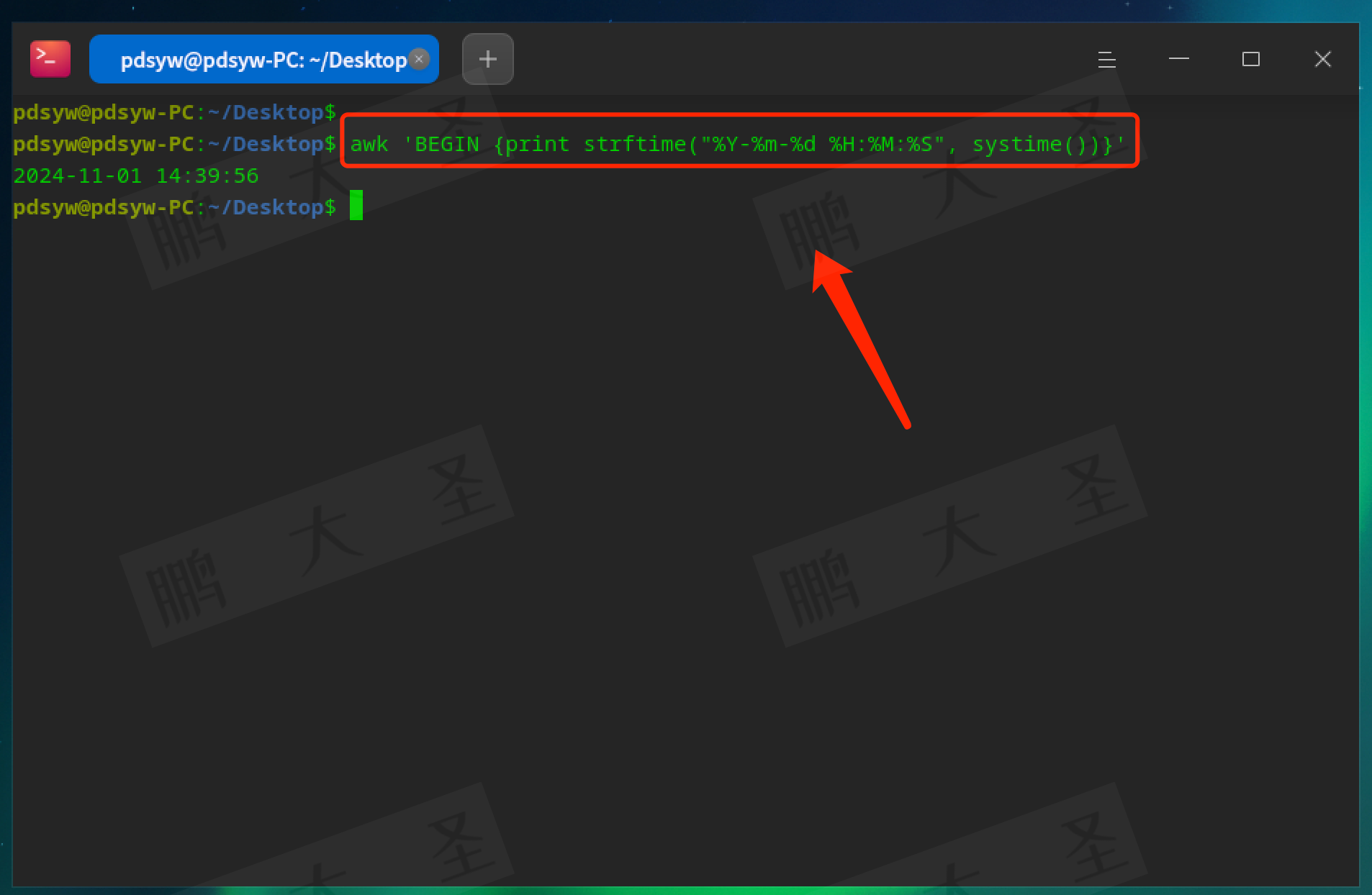
strftime:格式化时间。
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {print strftime("%Y-%m-%d %H:%M:%S", systime())}'
7.多模式匹配
可以在awk中使用多个模式进行匹配,每个模式有不同的动作。
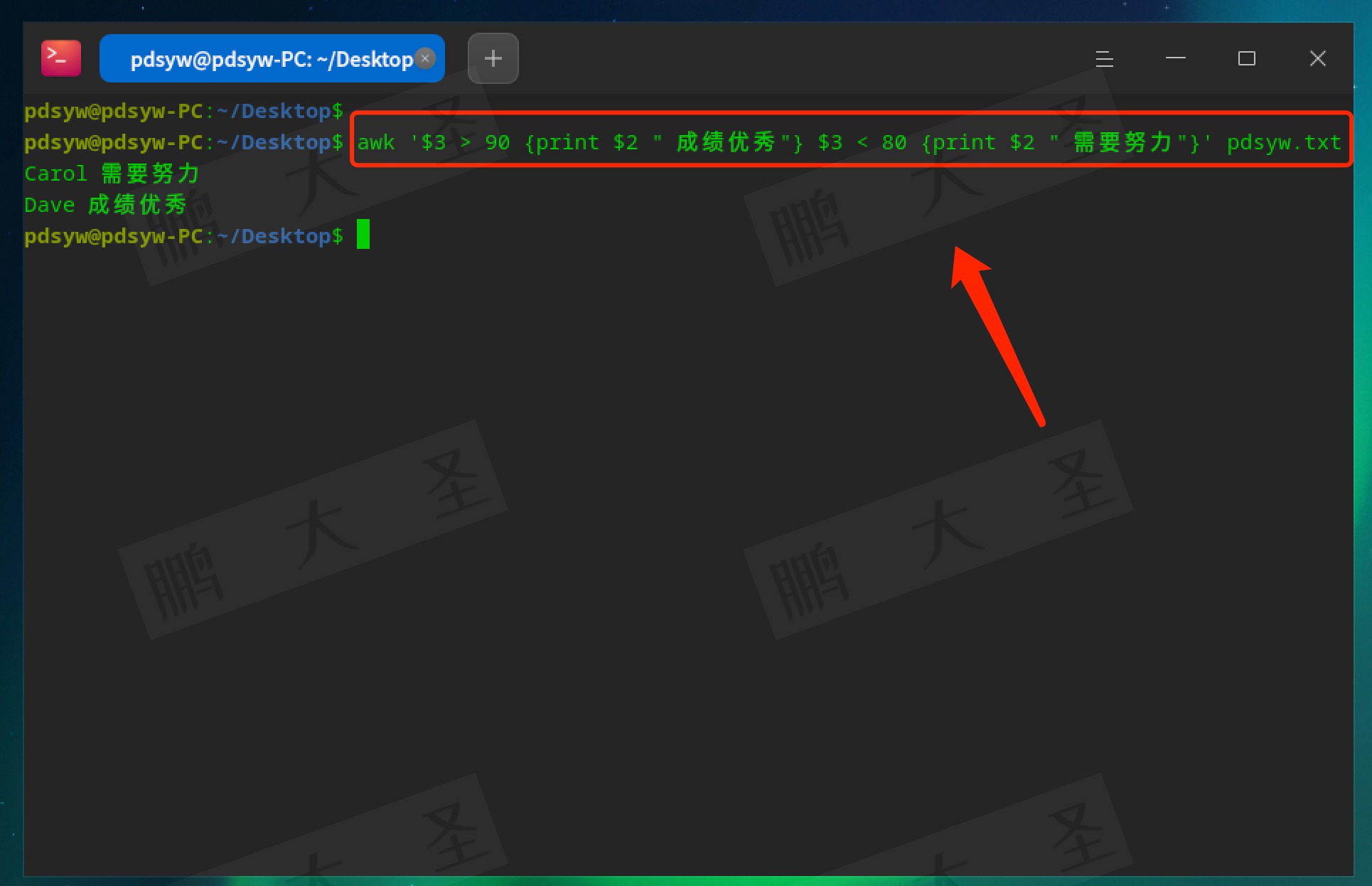
pdsyw@pdsyw-PC:~/Desktop$ awk '$3 > 90 {print $2 " 成绩优秀"} $3 < 80 {print $2 " 需要努力"}' pdsyw.txt
当分数大于90时,输出“成绩优秀”。
当分数小于80时,输出“需要努力”。
8.计算和统计
统计总和:
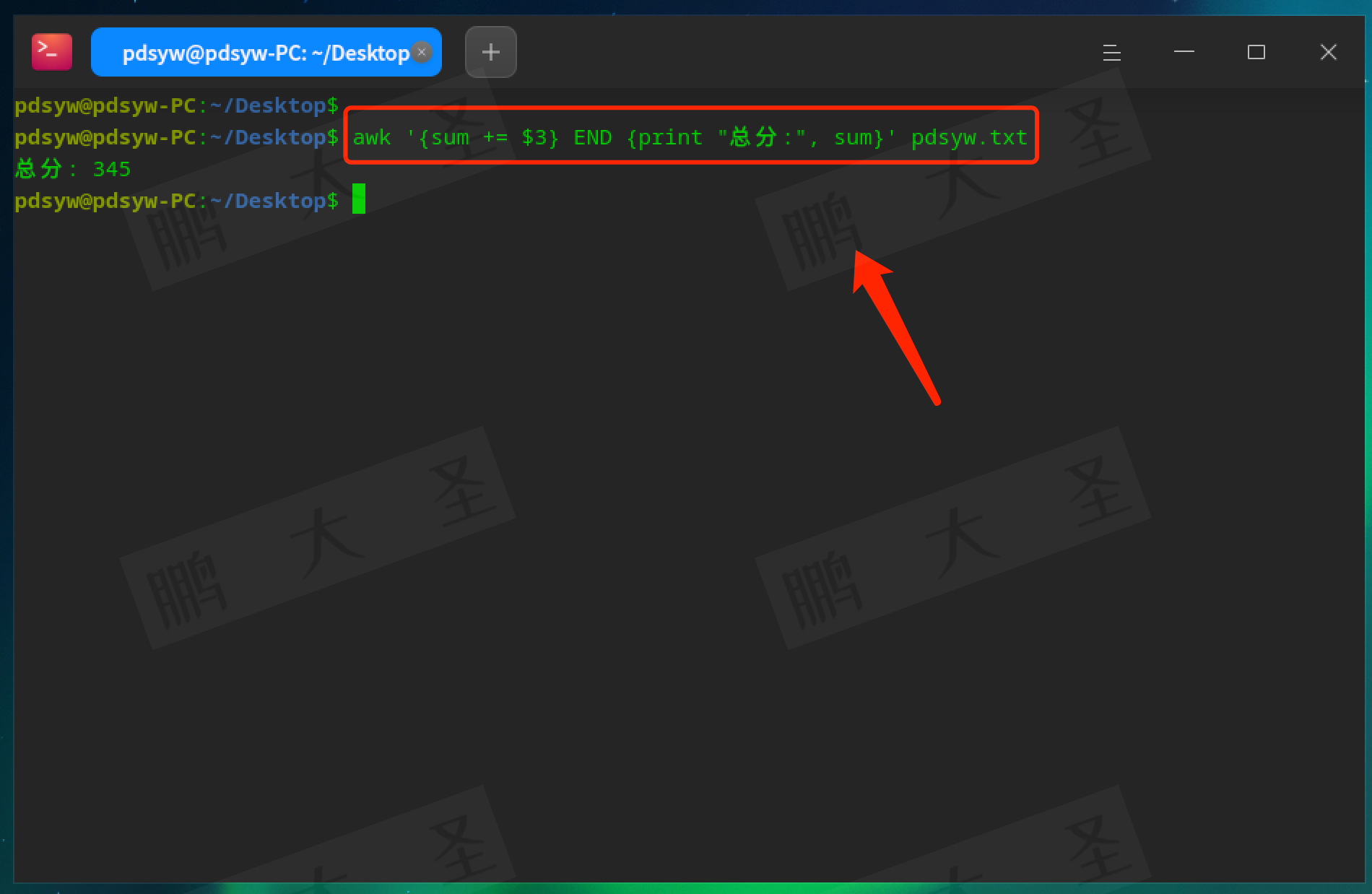
pdsyw@pdsyw-PC:~/Desktop$ awk '{sum += $3} END {print "总分:", sum}' pdsyw.txt
计算第三列(分数)的总和。
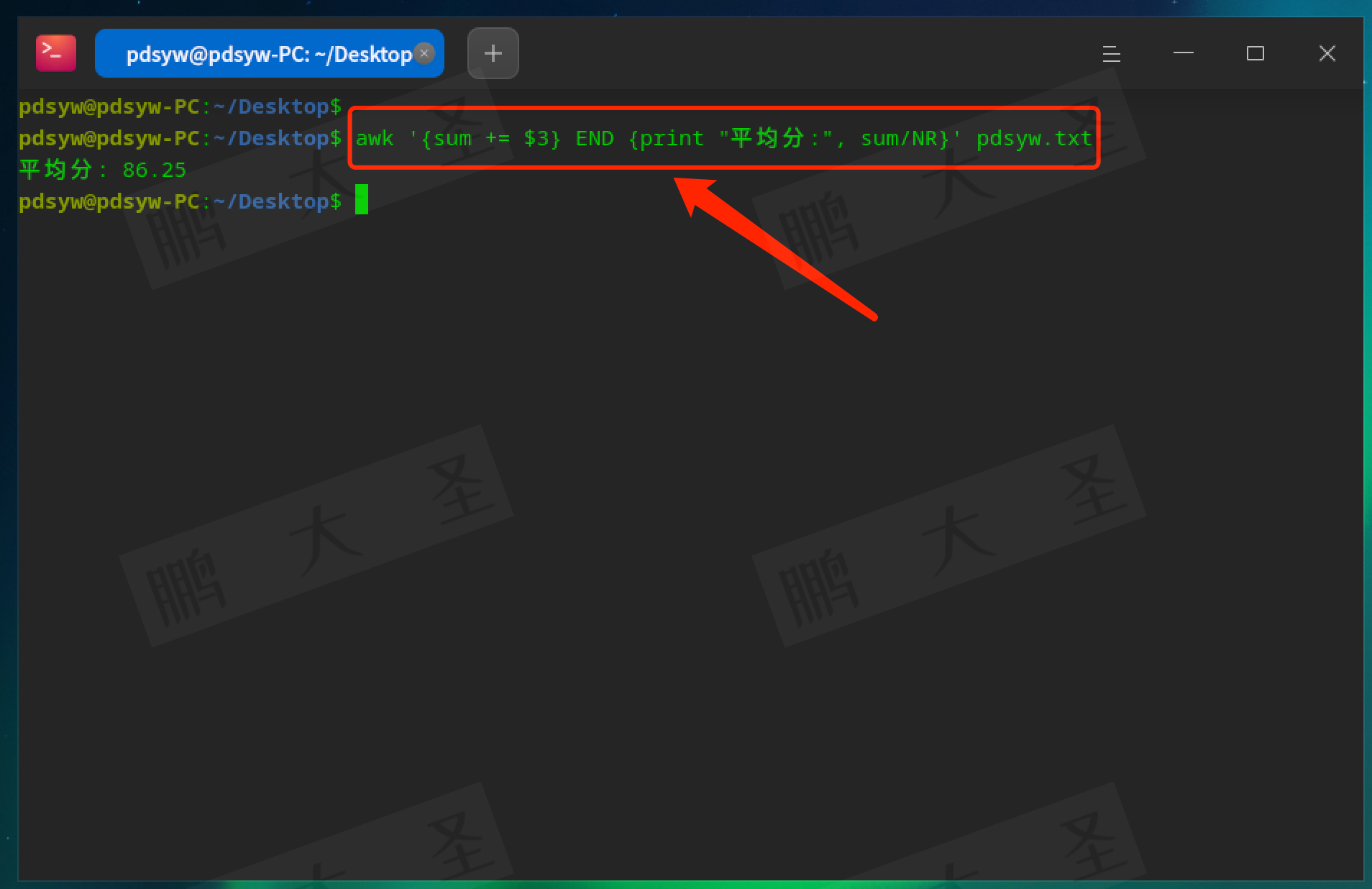
计算平均值:
pdsyw@pdsyw-PC:~/Desktop$ awk '{sum += $3} END {print "平均分:", sum/NR}' pdsyw.txt
计算分数的平均值。
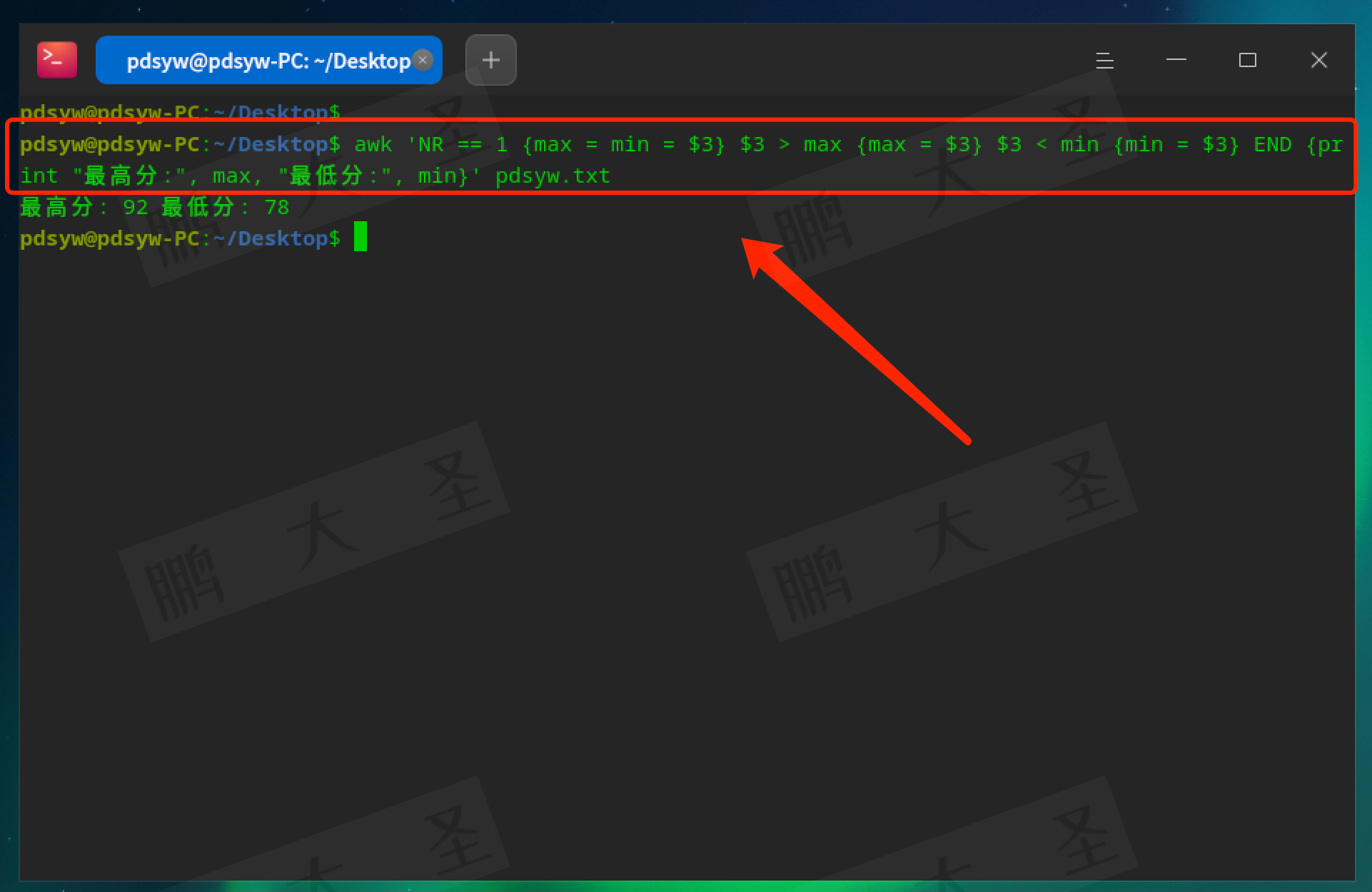
查找最大值和最小值:
pdsyw@pdsyw-PC:~/Desktop$ awk 'NR == 1 {max = min = $3} $3 > max {max = $3} $3 < min {min = $3} END {print "最高分:", max, "最低分:", min}' pdsyw.txt
查找分数中的最大值和最小值。
9.BEGIN 和 END 块
BEGIN:在处理文件之前执行一次。
END:在处理文件之后执行一次。
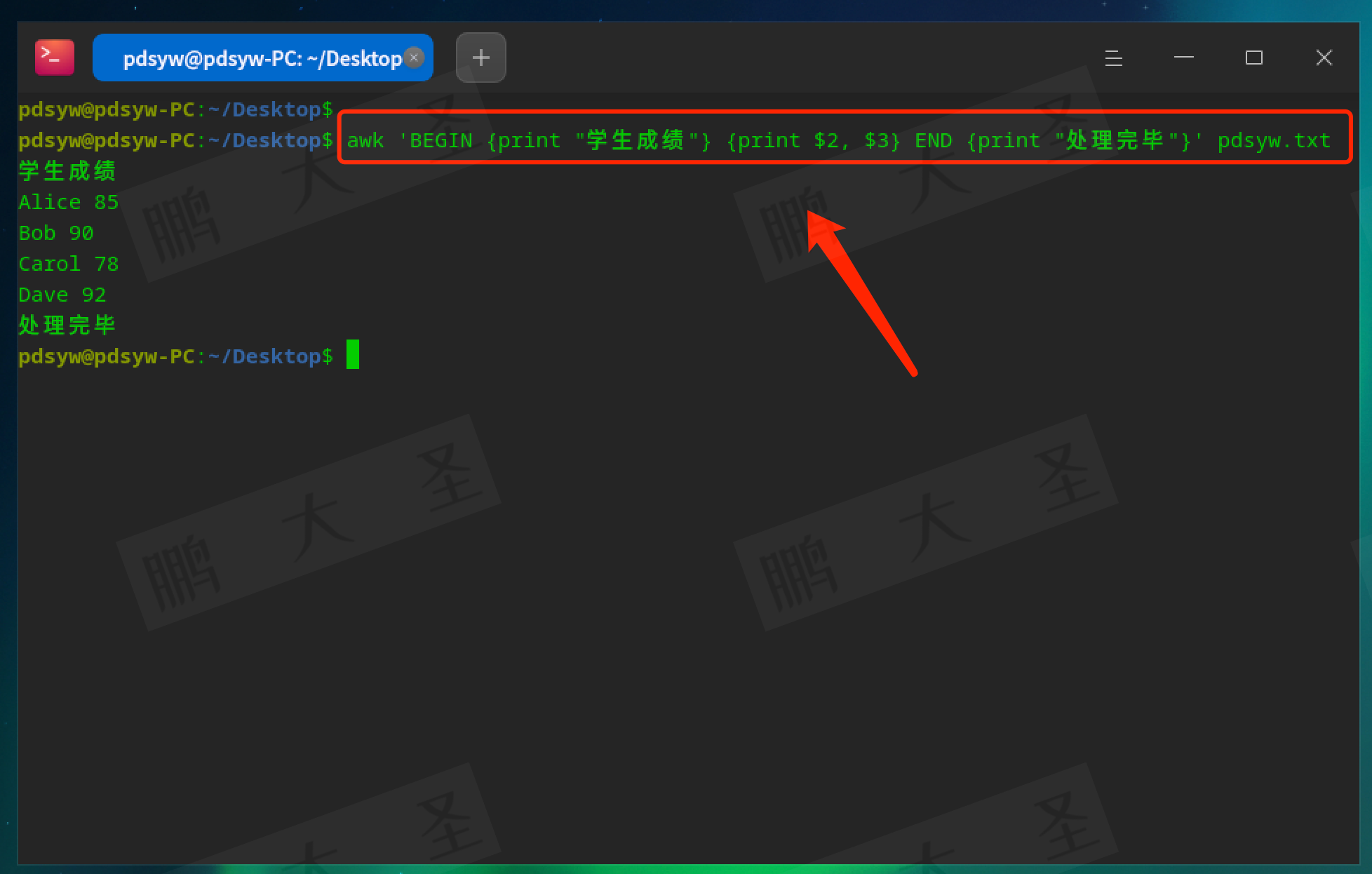
pdsyw@pdsyw-PC:~/Desktop$ awk 'BEGIN {print "学生成绩"} {print $2, $3} END {print "处理完毕"}' pdsyw.txt
输出结果包含了“学生成绩”和“处理完毕”的标识。
10.示例总结
条件输出:
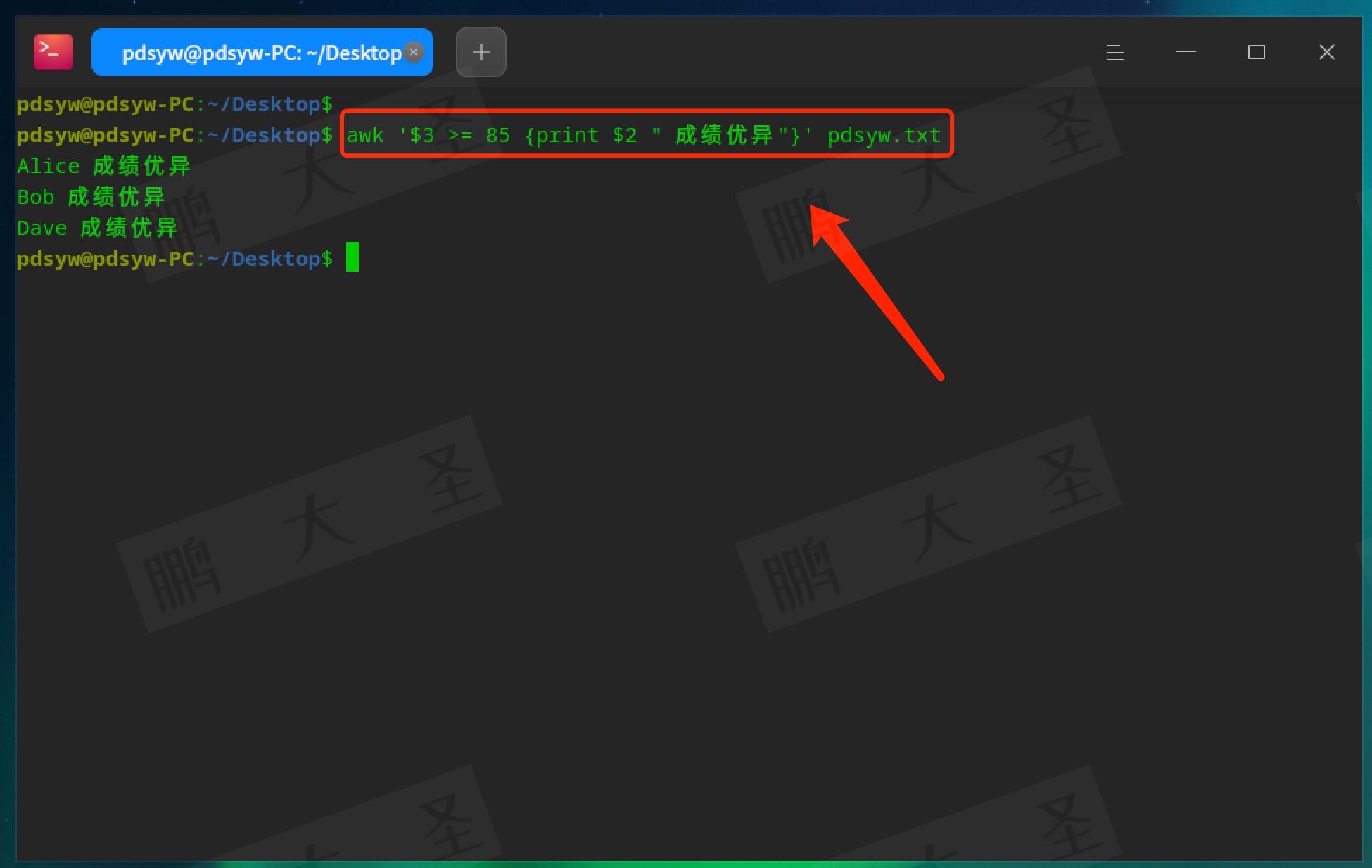
pdsyw@pdsyw-PC:~/Desktop$ awk '$3 >= 85 {print $2 " 成绩优异"}' pdsyw.txt
分数统计和求平均:
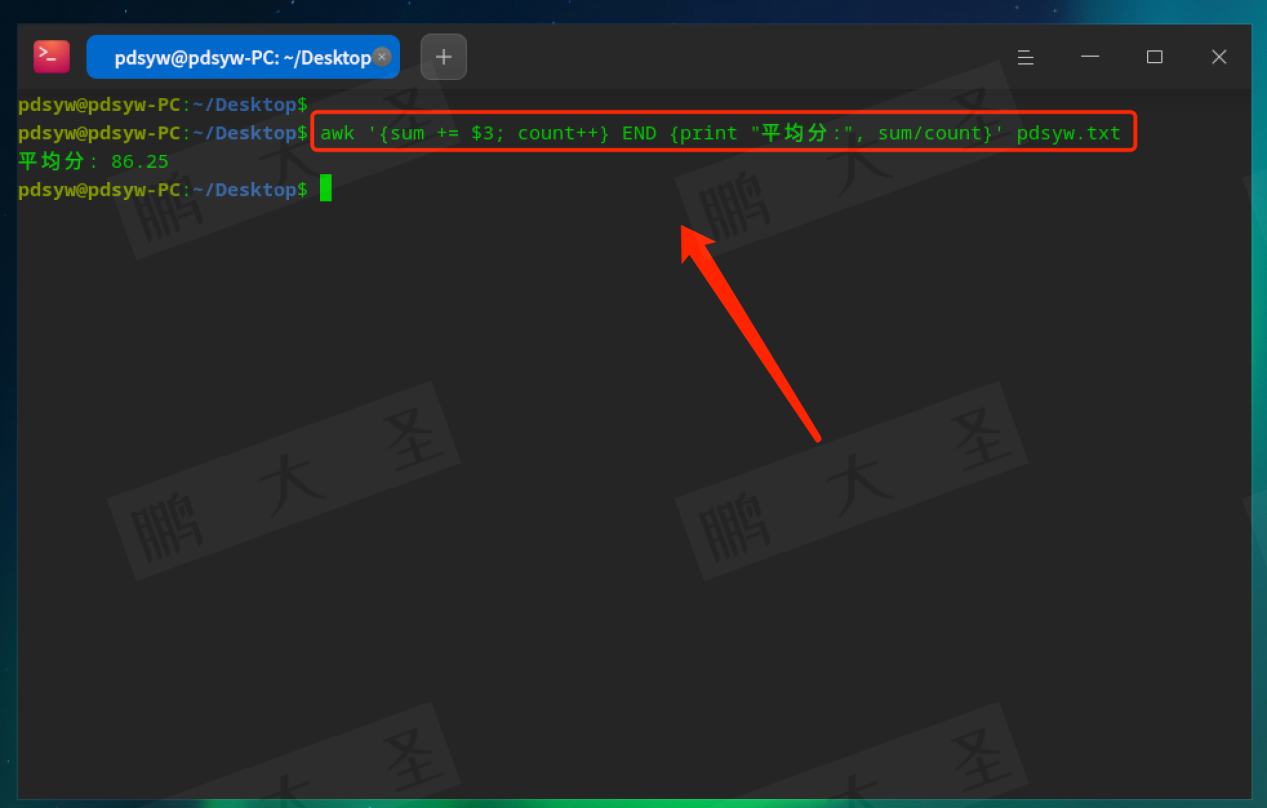
pdsyw@pdsyw-PC:~/Desktop$ awk '{sum += $3; count++} END {print "平均分:", sum/count}' pdsyw.txt
处理带特定分隔符的文件:
pdsyw@pdsyw-PC:~/Desktop$ awk -F ':' '{print $1, $3}' /etc/passwd
通过本文的介绍,大家应该已经掌握了awk命令的基本用法及其强大的数据处理功能。awk在Linux系统中作为三剑客之一,不仅能够快速提取和筛选数据,还可以灵活地应用到各种场景中,极大提升工作效率。如果您觉得这篇文章对您有帮助,别忘了分享、转发,并记得点个关注和在看!感谢大家的阅读,我们下次再见!