Hive 2.x 的安装与配置
Hive 2.x 的安装与配置
1 简介
基于Hadoop的一个数据仓库工具,可将结构化数据文件映射为一张数据库表,并提供简单[SQL]查询,可将SQL语句转换为MapReduce任务进行运行。
优点
学习成本低,可通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,适合数据仓库的统计分析。
提供一系列工具,进行数据提取转化加载(ETL),这是种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义简单的类 SQL 查询语言HQL,允许SQL用户查询数据。
也允许熟悉 MapReduce 开发者的开发自定义的 mapper、reducer处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
无专门数据格式,可很好工作在 Thrift 上,控制分隔符,也允许用户指定数据格式。
由[Facebook]开发,也有其他公司使用和开发Hive,如[Netflix]。亚马逊也开发定制版Apache Hive,亚马逊网络服务包中的Amazon Elastic MapReduce包含该定制版本。
2 环境
-
Hadoop版本 hadoop-2.6.0-cdh5.7.0
-
MySQL版本

-
mysql-connector-java 5.1.37
-
Hive版本 2.3.4
3 安装Hive
3.1 先确保已经正确安装并运行了hadoop
3.2 下载Hive安装包
官网下载
将安装包移动至: ../hadoop-2.6.0-cdh5.7.0/ 目录,本地安装Hadoop的目录
移动至此处后,解压缩
tar -xzvf apache-hive-2.3.4-bin.tar.gz
将解压后的文件名改为hive,方便配置。 如本机Hive的安装路径: 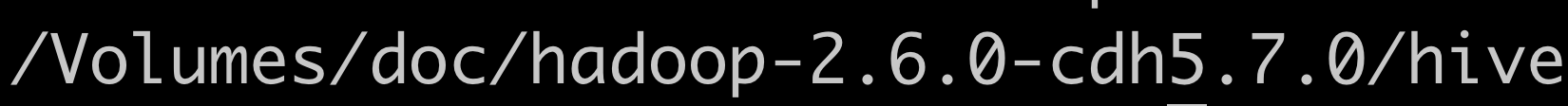
3.3 配置系统环境变量
3.3.1 修改~/.bash_profile
// 或者修改/etc/profile文件
vim ~/.bash_profile
添加内容
export HIVE_HOME=/Volumes/doc/hadoop-2.6.0-cdh5.7.0/hive
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/conf
退出保存后,在终端输入,使环境变量立即生效
source ~/.bash_profile
4 修改Hive配置
4.1 新建hive-site.xml
在 ../hive/conf: 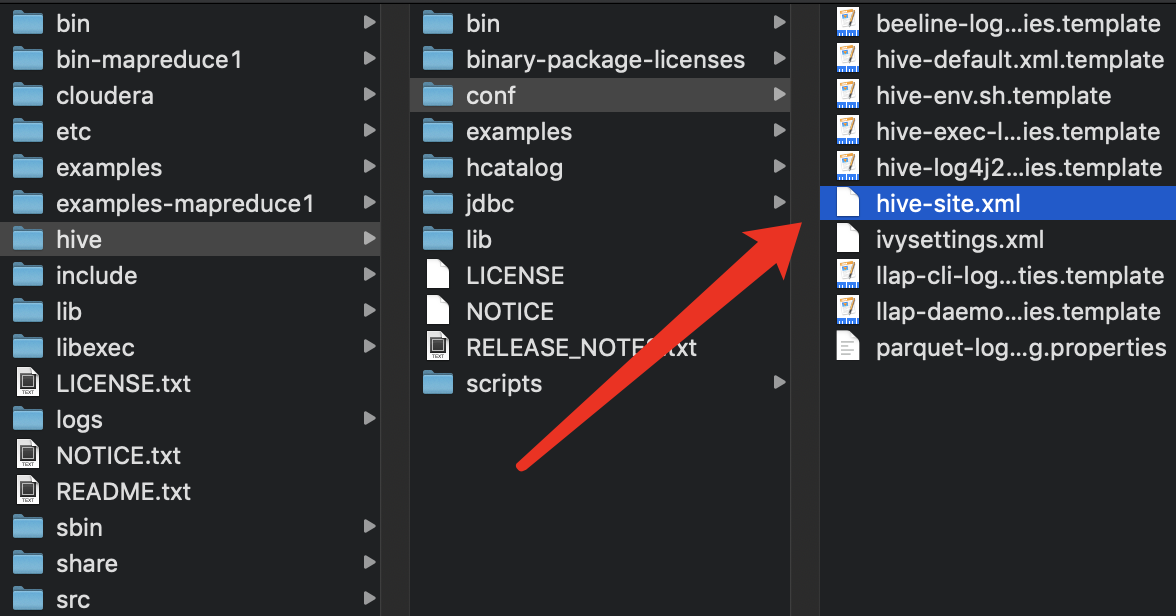
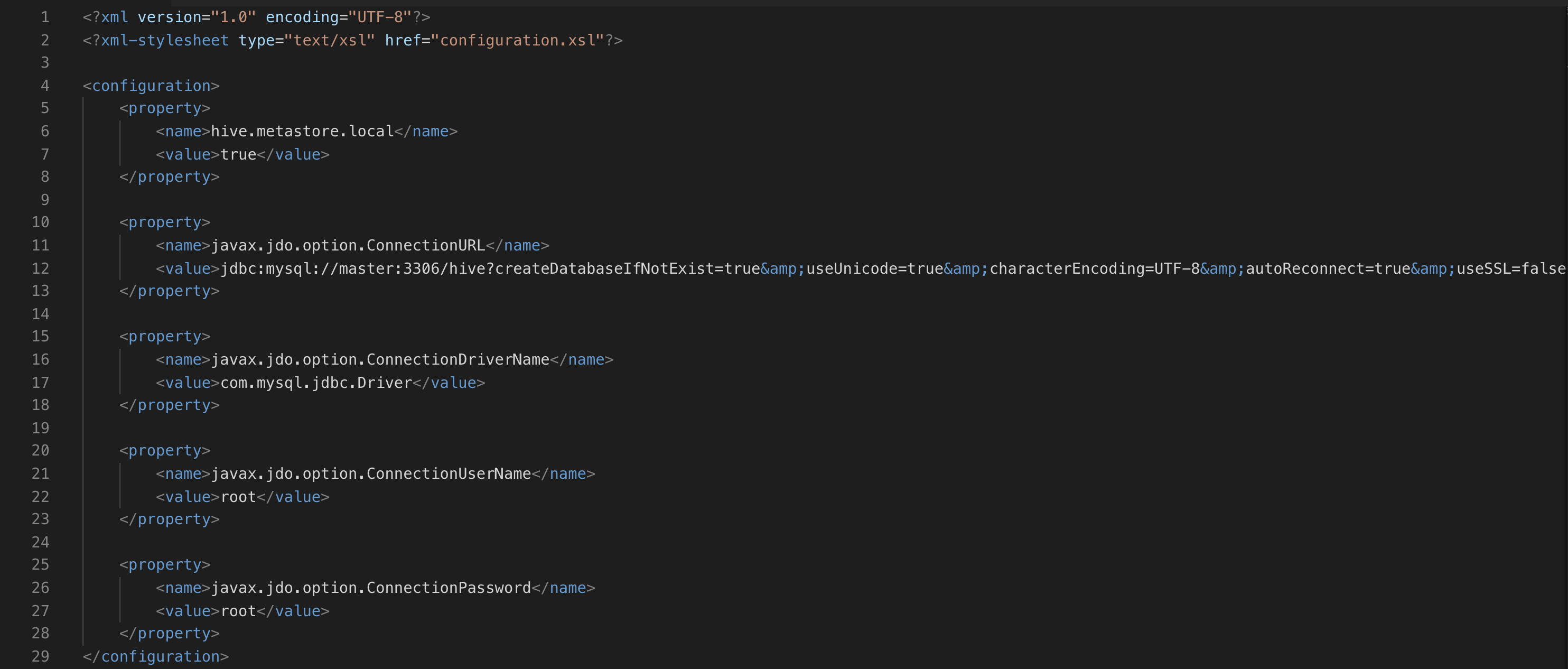
添加hive-site.xml内容:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 使用 JDBC 存储 Hive 元数据 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://<hostname>:<port>/<database_name>?createDatabaseIfNotExist=true</value>
<description>JDBC connection URL for a JDBC metastore.</description>
</property>
<!-- 指定 JDBC 驱动程序类 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 指定数据库用户名和密码 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value><username></value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value><password></value>
<description>password to use against metastore database</description>
</property>
<!-- 指定数据库类型 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 指定 Hive 元数据的存储位置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!-- 指定 Hive 元数据的存储方式 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Fail metastore startup if the schema version does not match.
False: Warn and continue metastore startup even if the schema version does not match.
</description>
</property>
</configuration>
4.2 hive-env.sh
复制hive-env.sh.template为hive-env.sh 
修改hive-env.sh内容 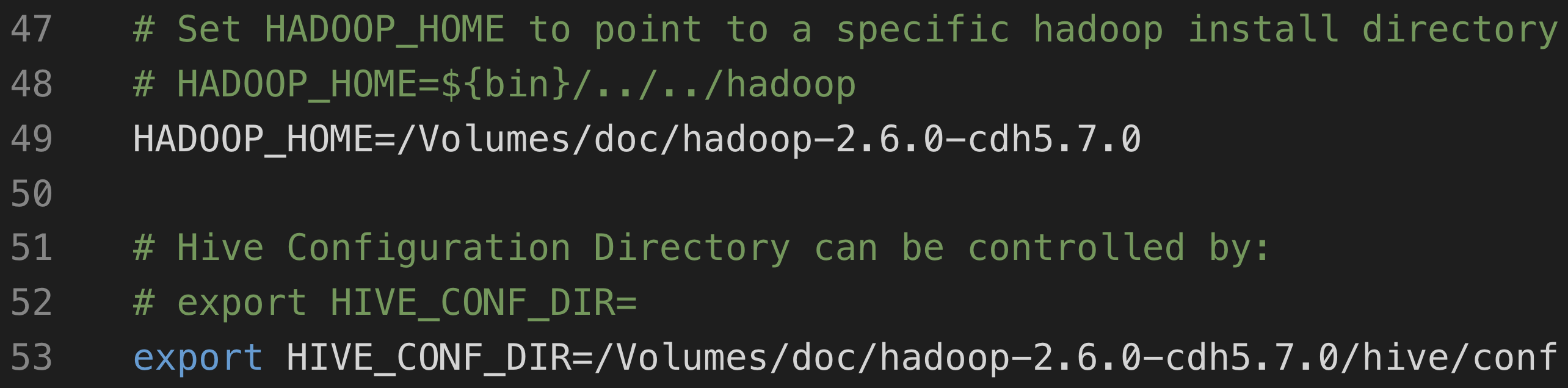
5 MySQL 权限配置
5.1 给用户赋予权限
使该用户可以远程登录数据库: 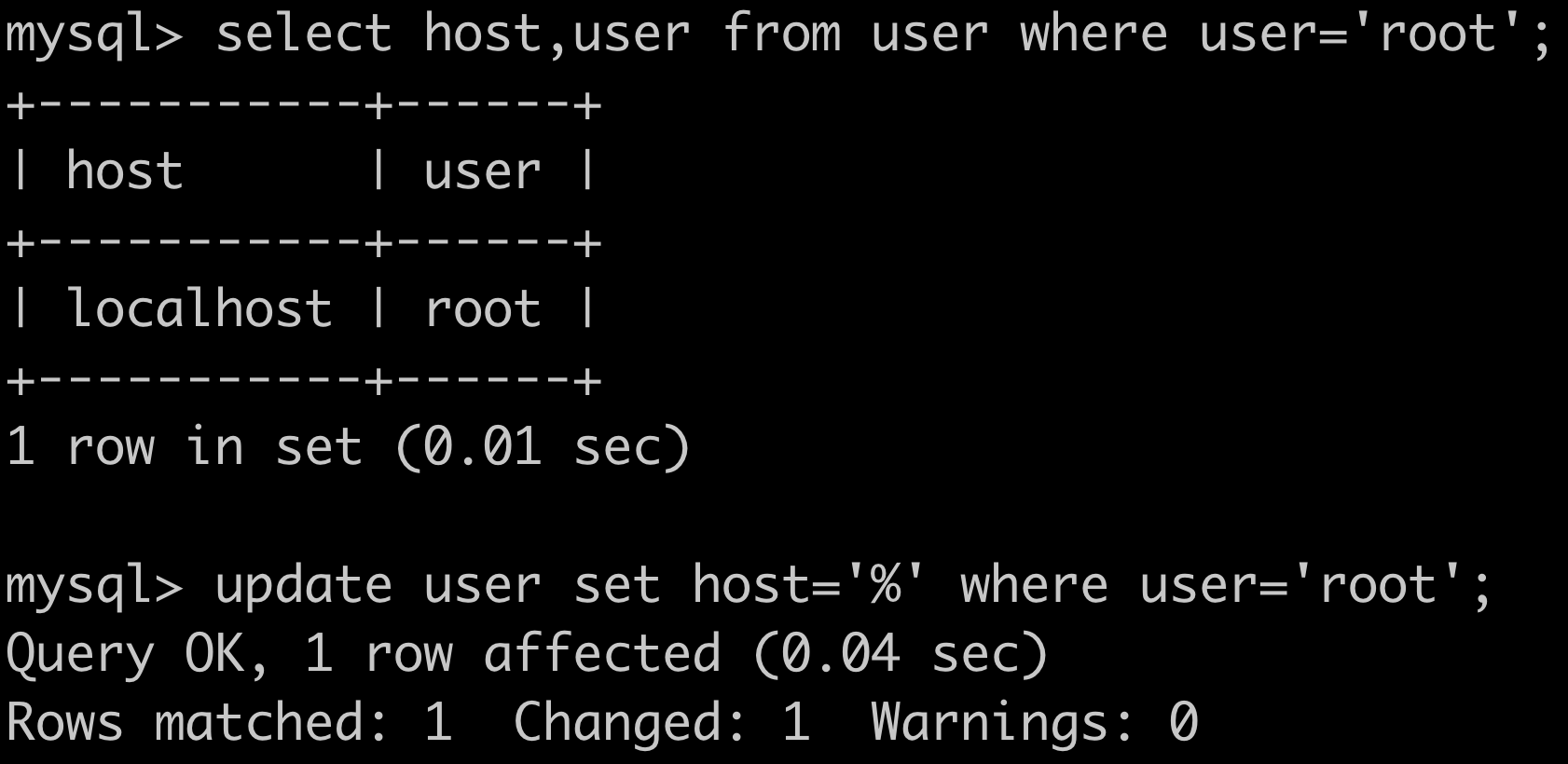
如果上面查询到有信息,但host为localhost或其他值,就需要根据实际需求来更新表信息
grant all privileges on 库名.表名 to '用户名'@'IP地址' identified by '密码' with grant option;
flush privileges;
库名:要远程访问的数据库名称,所有的数据库使用“” 表名:要远程访问的数据库下的表的名称,所有的表使用“” 用户名:要赋给远程访问权限的用户名称 IP地址:可以远程访问的电脑的IP地址,所有的地址使用“%” 密码:要赋给远程访问权限的用户对应使用的密码
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
使改变立即生效:
FLUSH PRIVILEGES;

6 lib中添加MySQL驱动
向/usr/hadoop/hadoop-2.6.2/hive/lib中添加MySQL连接库:
下载驱动
将下好的包解压
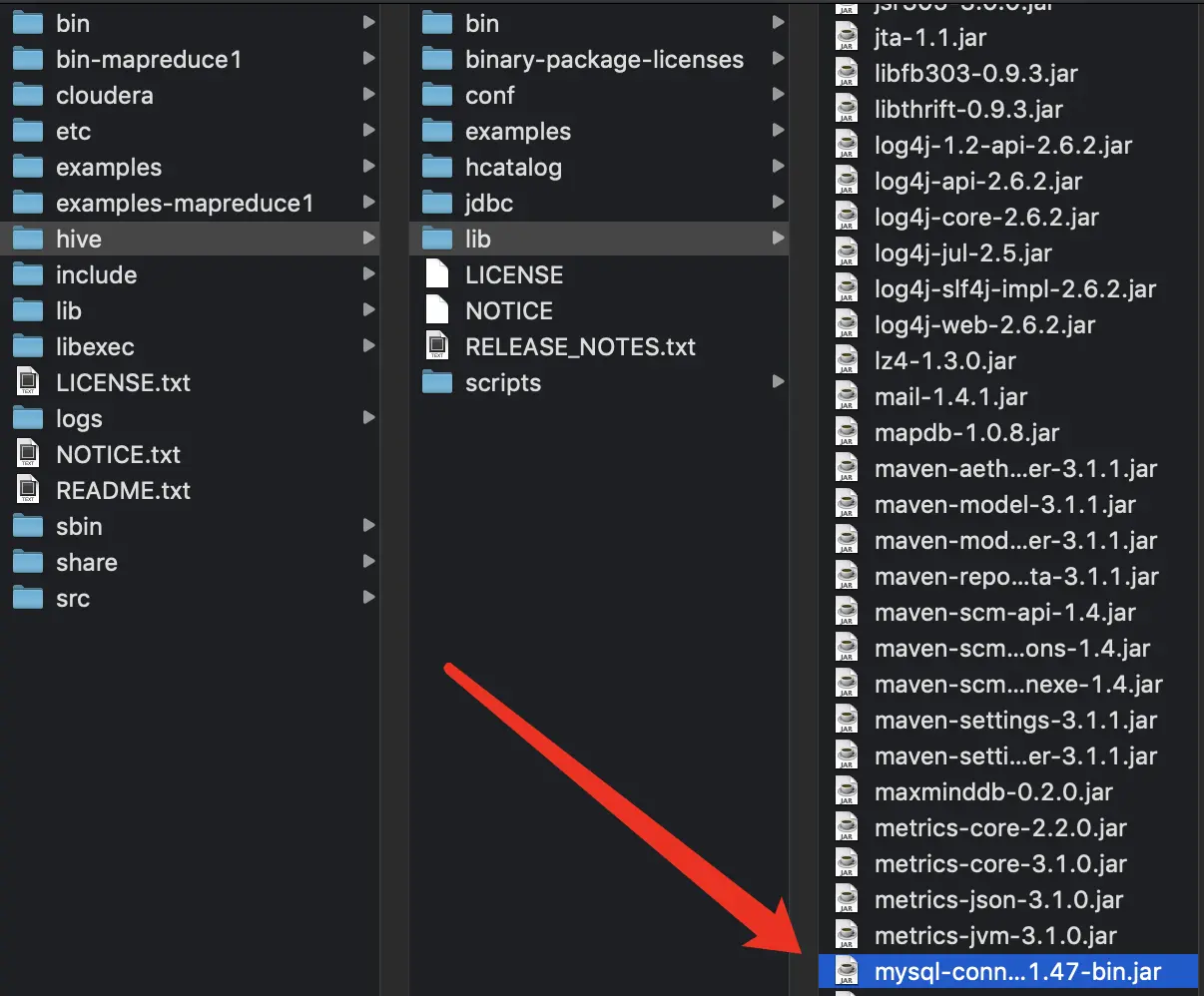
解压后,将此文件夹下mysql-connector-java-8.0.15.jar
复制到../hive/lib:
需要给/tmp文件夹设置写权限,同时确保 hadoop不在安全模式下,可以执行此命令使hadoop退出安全模式:hadoop dfsadmin -safemode leave
7 启动Hive
在命令行运行 hive 命令时必须保证HDFS 已经启动。可以使用 start-dfs.sh 脚本来启动 HDFS。
7.1 第一次启动Hive
要先执行初始化命令:
schematool -dbType mysql -initSchema

7.2 启动Hive
javaedge@JavaEdgedeMac-mini bin % ./hive
ls: /Users/javaedge/Downloads/soft/spark-2.4.3-bin-2.6.0-cdh5.15.1/lib/spark-assembly-*.jar: No such file or directory
/Users/javaedge/Downloads/soft/hadoop-2.6.0-cdh5.15.1/bin/hadoop: line 148: /Users/javaedge/Downloads/soft/hive-1.1.0-cdh5.15.1/bin/@@HOMEBREW_JAVA@@/bin/java: No such file or directory
/Users/javaedge/Downloads/soft/hadoop-2.6.0-cdh5.15.1/bin/hadoop: line 148: exec: /Users/javaedge/Downloads/soft/hive-1.1.0-cdh5.15.1/bin/@@HOMEBREW_JAVA@@/bin/java: cannot execute: No such file or directory
/usr/local/Cellar/hbase/2.5.3/libexec/bin/hbase: line 401: @@HOMEBREW_JAVA@@/bin/java: No such file or directory
23/03/25 22:40:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Logging initialized using configuration in jar:file:/Users/javaedge/Downloads/soft/hive-1.1.0-cdh5.15.1/lib/hive-common-1.1.0-cdh5.15.1.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
获取更多干货内容,记得关注我哦。
本文由 mdnice 多平台发布