JMM(一)[volatilr关键字、乐观锁和悲观锁]
volatile 关键字
如何保证变量的可见性?
在 Java 中,volatile 关键字可以保证变量的可见性,如果我们将变量声明为 volatile ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
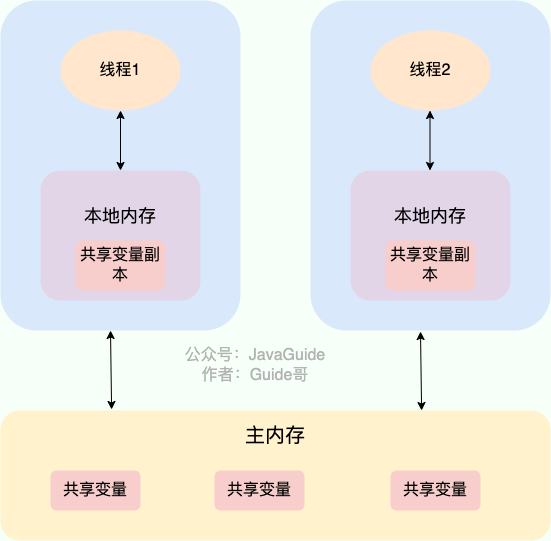
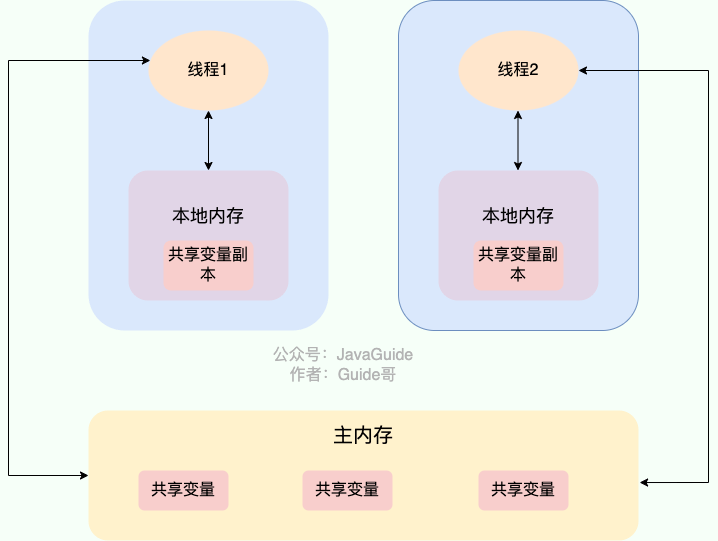
volatile 关键字其实并非是 Java 语言特有的,在 C 语言里也有,它最原始的意义就是禁用 CPU 缓存。如果我们将一个变量使用 volatile 修饰,这就指示 编译器,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。
如何禁止指令重排序?
在 Java 中,volatile 关键字除了可以保证变量的可见性,还有一个重要的作用就是防止 JVM 的指令重排序。 如果我们将变量声明为 volatile ,在对这个变量进行读写操作的时候,会通过插入特定的 内存屏障 的方式来禁止指令重排序。
在 Java 中,Unsafe 类提供了三个开箱即用的内存屏障相关的方法,屏蔽了操作系统底层的差异:
public native void loadFence();
public native void storeFence();
public native void fullFence();理论上来说,你通过这个三个方法也可以实现和volatile禁止重排序一样的效果,只是会麻烦一些。
下面我以一个常见的面试题为例讲解一下 volatile 关键字禁止指令重排序的效果。
面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
双重校验锁实现对象单例(线程安全):
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为
uniqueInstance分配内存空间 - 初始化
uniqueInstance - 将
uniqueInstance指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
volatile 可以保证原子性么?
volatile 关键字能保证变量的可见性,但不能保证对变量的操作是原子性的。
我们通过下面的代码即可证明:

正常情况下,运行上面的代码理应输出 2500。但你真正运行了上面的代码之后,你会发现每次输出结果都小于 2500。
为什么会出现这种情况呢?不是说好了,volatile 可以保证变量的可见性嘛!
也就是说,如果 volatile 能保证 inc++ 操作的原子性的话。每个线程中对 inc 变量自增完之后,其他线程可以立即看到修改后的值。5 个线程分别进行了 500 次操作,那么最终 inc 的值应该是 5*500=2500。
很多人会误认为自增操作 inc++ 是原子性的,实际上,inc++ 其实是一个复合操作,包括三步:
- 读取 inc 的值。
- 对 inc 加 1。
- 将 inc 的值写回内存。
volatile 是无法保证这三个操作是具有原子性的,有可能导致下面这种情况出现:
- 线程 1 对
inc进行读取操作之后,还未对其进行修改。线程 2 又读取了inc的值并对其进行修改(+1),再将inc的值写回内存。 - 线程 2 操作完毕后,线程 1 对
inc的值进行修改(+1),再将inc的值写回内存。
这也就导致两个线程分别对 inc 进行了一次自增操作后,inc 实际上只增加了 1。
其实,如果想要保证上面的代码运行正确也非常简单,利用 synchronized、Lock或者AtomicInteger都可以。
使用 synchronized 改进:
public synchronized void increase() {
inc++;
}使用 AtomicInteger 改进:
public AtomicInteger inc = new AtomicInteger();
public void increase() {
inc.getAndIncrement();
}使用 ReentrantLock 改进:
Lock lock = new ReentrantLock();
public void increase() {
lock.lock();
try {
inc++;
} finally {
lock.unlock();
}
}乐观锁和悲观锁
什么是悲观锁?
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
像 Java 中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
public void performSynchronisedTask() {
synchronized (this) {
// 需要同步的操作
}
}
private Lock lock = new ReentrantLock();
lock.lock();
try {
// 需要同步的操作
} finally {
lock.unlock();
}高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行。
什么是乐观锁?
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法)。
在 Java 中java.util.concurrent.atomic包下面的原子变量类(比如AtomicInteger、LongAdder)就是使用了乐观锁的一种实现方式 CAS 实现的。
// LongAdder 在高并发场景下会比 AtomicInteger 和 AtomicLong 的性能更好
// 代价就是会消耗更多的内存空间(空间换时间)
LongAdder sum = new LongAdder();
sum.increment();高并发的场景下,乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹。但是,如果冲突频繁发生(写占比非常多的情况),会频繁失败和重试,这样同样会非常影响性能,导致 CPU 飙升。
不过,大量失败重试的问题也是可以解决的,像我们前面提到的 LongAdder以空间换时间的方式就解决了这个问题。
理论上来说:
- 悲观锁通常多用于写比较多的情况(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如
LongAdder),也是可以考虑使用乐观锁的,要视实际情况而定。 - 乐观锁通常多用于写比较少的情况(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考
java.util.concurrent.atomic包下面的原子变量类)。
如何实现乐观锁?
乐观锁一般会使用版本号机制或 CAS 算法实现,CAS 算法相对来说更多一些,这里需要格外注意。
版本号机制
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
举一个简单的例子:假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
- 操作员 A 此时将其读出(
version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。 - 在操作员 A 操作的过程中,操作员 B 也读入此用户信息(
version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。 - 操作员 A 完成了修改工作,将数据版本号(
version=1 ),连同帐户扣除后余额(balance=$50 ),提交至数据库更新,此时由于提交数据版本等于数据库记录当前版本,数据被更新,数据库记录version更新为 2 。 - 操作员 B 完成了操作,也将版本号(
version=1 )试图向数据库提交数据(balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 1 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须等于当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员 A 的操作结果的可能。
CAS 算法
CAS 的全称是 Compare And Swap(比较与交换) ,用于实现乐观锁,被广泛应用于各大框架中。CAS 的思想很简单,就是用一个预期值和要更新的变量值进行比较,两值相等才会进行更新。
CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
原子操作 即最小不可拆分的操作,也就是说操作一旦开始,就不能被打断,直到操作完成。
CAS 涉及到三个操作数:
- V:要更新的变量值(Var)
- E:预期值(Expected)
- N:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
举一个简单的例子:线程 A 要修改变量 i 的值为 6,i 原值为 1(V = 1,E=1,N=6,假设不存在 ABA 问题)。
- i 与 1 进行比较,如果相等, 则说明没被其他线程修改,可以被设置为 6 。
- i 与 1 进行比较,如果不相等,则说明被其他线程修改,当前线程放弃更新,CAS 操作失败。
当多个线程同时使用 CAS 操作一个变量时,只有一个会胜出,并成功更新,其余均会失败,但失败的线程并不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
Java 语言并没有直接实现 CAS,CAS 相关的实现是通过 C++ 内联汇编的形式实现的(JNI 调用)。因此, CAS 的具体实现和操作系统以及 CPU 都有关系。
sun.misc包下的Unsafe类提供了compareAndSwapObject、compareAndSwapInt、compareAndSwapLong方法来实现的对Object、int、long类型的 CAS 操作
/**
* CAS
* @param o 包含要修改field的对象
* @param offset 对象中某field的偏移量
* @param expected 期望值
* @param update 更新值
* @return true | false
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt(Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long update);关于 Unsafe 类的详细介绍可以看这篇文章:Java 魔法类 Unsafe 详解 - JavaGuide - 2022 。
Java 中 CAS 是如何实现的?
在 Java 中,实现 CAS(Compare-And-Swap, 比较并交换)操作的一个关键类是Unsafe。
Unsafe类位于sun.misc包下,是一个提供低级别、不安全操作的类。由于其强大的功能和潜在的危险性,它通常用于 JVM 内部或一些需要极高性能和底层访问的库中,而不推荐普通开发者在应用程序中使用。关于 Unsafe类的详细介绍,可以阅读这篇文章:📌Java 魔法类 Unsafe 详解。
sun.misc包下的Unsafe类提供了compareAndSwapObject、compareAndSwapInt、compareAndSwapLong方法来实现的对Object、int、long类型的 CAS 操作:
/**
* 以原子方式更新对象字段的值。
*
* @param o 要操作的对象
* @param offset 对象字段的内存偏移量
* @param expected 期望的旧值
* @param x 要设置的新值
* @return 如果值被成功更新,则返回 true;否则返回 false
*/
boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
/**
* 以原子方式更新 int 类型的对象字段的值。
*/
boolean compareAndSwapInt(Object o, long offset, int expected, int x);
/**
* 以原子方式更新 long 类型的对象字段的值。
*/
boolean compareAndSwapLong(Object o, long offset, long expected, long x);Unsafe类中的 CAS 方法是native方法。native关键字表明这些方法是用本地代码(通常是 C 或 C++)实现的,而不是用 Java 实现的。这些方法直接调用底层的硬件指令来实现原子操作。也就是说,Java 语言并没有直接用 Java 实现 CAS,而是通过 C++ 内联汇编的形式实现的(通过 JNI 调用)。因此,CAS 的具体实现与操作系统以及 CPU 密切相关。
java.util.concurrent.atomic 包提供了一些用于原子操作的类。这些类利用底层的原子指令,确保在多线程环境下的操作是线程安全的。
关于这些 Atomic 原子类的介绍和使用,可以阅读这篇文章:Atomic 原子类总结。
AtomicInteger是 Java 的原子类之一,主要用于对 int 类型的变量进行原子操作,它利用Unsafe类提供的低级别原子操作方法实现无锁的线程安全性。
下面,我们通过解读AtomicInteger的核心源码(JDK1.8),来说明 Java 如何使用Unsafe类的方法来实现原子操作。
AtomicInteger核心源码如下:

Unsafe#getAndAddInt源码:
// 原子地获取并增加整数值
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
// 以 volatile 方式获取对象 o 在内存偏移量 offset 处的整数值
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
// 返回旧值
return v;
}可以看到,getAndAddInt 使用了 do-while 循环:在compareAndSwapInt操作失败时,会不断重试直到成功。也就是说,getAndAddInt方法会通过 compareAndSwapInt 方法来尝试更新 value 的值,如果更新失败(当前值在此期间被其他线程修改),它会重新获取当前值并再次尝试更新,直到操作成功。
由于 CAS 操作可能会因为并发冲突而失败,因此通常会与while循环搭配使用,在失败后不断重试,直到操作成功。这就是 自旋锁机制 。
CAS 算法存在哪些问题?
ABA 问题是 CAS 算法最常见的问题。
ABA 问题
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 "ABA"问题。
ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。JDK 1.5 以后的 AtomicStampedReference 类就是用来解决 ABA 问题的,其中的 compareAndSet() 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}循环时间长开销大
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
如果 JVM 能够支持处理器提供的pause指令,那么自旋操作的效率将有所提升。pause指令有两个重要作用:
- 延迟流水线执行指令:
pause指令可以延迟指令的执行,从而减少 CPU 的资源消耗。具体的延迟时间取决于处理器的实现版本,在某些处理器上,延迟时间可能为零。 - 避免内存顺序冲突:在退出循环时,
pause指令可以避免由于内存顺序冲突而导致的 CPU 流水线被清空,从而提高 CPU 的执行效率。
只能保证一个共享变量的原子操作
CAS 操作仅能对单个共享变量有效。当需要操作多个共享变量时,CAS 就显得无能为力。不过,从 JDK 1.5 开始,Java 提供了AtomicReference类,这使得我们能够保证引用对象之间的原子性。通过将多个变量封装在一个对象中,我们可以使用AtomicReference来执行 CAS 操作。
除了 AtomicReference 这种方式之外,还可以利用加锁来保证。