使用PEFT在多个AMD GPU上进行StarCoder的指令微调
Instruction fine-tuning of StarCoder with PEFT on multiple AMD GPUs — ROCm Blogs

2024年4月16日,由 Douglas Jia撰写。
在这篇博客中,我们将向您展示如何使用指令-答案对数据集在AMD GPU上微调StarCoder基础模型,以便它能够根据指令生成代码并回答问题。我们还将向您展示如何使用参数高效微调(PEFT)来最小化微调过程中的计算成本。
您可以在GitHub 仓库中找到这篇博客中提到的所有文件/脚本。
背景
StarCoder 是一种语言模型(LM),其在多种源代码和自然语言文本上进行了训练,涵盖了超过80种编程语言。其广泛的训练数据集包括从GitHub问题、提交和笔记本中提取的文本。由于专门在GitHub代码上进行了训练,StarCoder 拥有无缝生成代码的独特能力。从完成函数实现到推断代码行中的下一个字符,StarCoder 可以帮助开发者提高代码生成任务的效率和准确性。我们下面的代码示例基于 15.5B 的 StarCoder 模型,但你也可以使用最新发布的 StarCoder V2 模型(3B, 7B 和 15B)。
指令微调是一种用于自然语言处理(NLP)领域的技术,通过在训练过程中提供明确的指令或提示来微调预训练的语言模型(LM)。与传统的仅依赖标记数据的微调方法不同,指令微调允许开发者提供与任务相关的特定指令或提示来引导模型的学习过程。这种方法能够让模型更好地理解并适应目标任务的细微差别,从而提高性能和泛化能力。指令微调的一个关键应用是在语言模型中生成定制化的响应或输出。通过提供任务特定的指令或提示,开发者可以训练模型生成在上下文上相关且符合期望任务目标的响应。
参数高效微调(PEFT)是一种在深度学习领域,特别是在Transformer微调中的新颖技术。与传统微调方法需要重新训练大量参数的整个模型不同,PEFT 主要关注于选择性地微调模型的部分参数。通过识别和更新与目标任务最相关的参数,PEFT 大大减少了微调大规模模型所需的计算成本和内存需求。此外,PEFT 还被证明可以减轻过拟合的风险,因为它避免了对不相关参数的不必要更新,从而保持预训练模型的泛化能力。在流行的 PEFT 技术(如 LoRA,Low-Rank Adaptation)中,适配层是紧凑的神经网络模块,集成到预训练的语言模型(LLM)中,以便针对特定任务进行微调。在 LoRA 中,这些适配层用于细化 LLM,而不显著修改基础模型的参数。
在接下来的部分中,我们将展示如何利用 LoRA 使用 Stack Exchange 指令数据集中的问答对数据在多台 AMD GPU 上微调 StarCoder 模型。你可以在这里访问数据集。
环境设置
我们在Ubuntu系统上使用包含8个AMD GPU的PyTorch ROCm 6.0 Docker容器进行模型的微调(有关AMD支持的操作系统和硬件列表,请点击此处)。通过以下代码在Linux shell中拉取并运行Docker容器:
docker run -it --ipc=host --network=host --device=/dev/kfd --device=/dev/dri \
--group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--name=starcoder rocm/pytorch:rocm6.0.2_ubuntu22.04_py3.10_pytorch_2.1.2 /bin/bash
你可以通过在Python控制台中运行以下两行代码,检查PyTorch框架检测到的GPU数量。对于我来说,它显示我有8个GPU。
import torch torch.cuda.device_count()
实现
在本节中,我们将向你展示如何实现StarCoder模型的LoRA微调。
软件包安装
为了提高微调的效率,除了采用 LoRA 技术外,我们还将引入 bitsandbytes 包,通过量化优化内存使用——这是一种通过降低大语言模型中权重的精度来进行压缩的技术。请使用下面的代码从 ROCmSoftwarePlatform GitHub 仓库安装它:
git clone --recurse https://github.com/ROCm/bitsandbytes cd bitsandbytes git checkout rocm_enabled pip install -r requirements-dev.txt cmake -DCOMPUTE_BACKEND=hip -S . #Use -DBNB_ROCM_ARCH="gfx90a;gfx942" to target specific gpu arch make pip install . cd ..
我们还需要安装其他所需的软件包。
pip install --upgrade pip pip install transformers==4.38.2 pip install peft==0.10.0 pip install deepspeed==0.13.1 pip install accelerate==0.27.2 pip install --upgrade huggingface_hub pip install wandb==0.16.3 pip install fsspec==2023.10.0 pip install requests==2.28.2 pip install datasets==2.17.1 pip install pandas==2.2.1 pip install numpy==1.22.4 pip install numba==0.59.1
微调
在本节中,我们将使用一个指令-回答数据集微调 StarCoder 模型。我们将使用来源于 Stack Exchange 网络的 ArmelR/stack-exchange-instruction 数据集,该数据集包括从各种主题中抓取的问答对,从而增强语言模型的问答能力。
要访问 StarCoder 模型,必须首先在 此链接 接受模型许可协议。然后,在你的 Linux 终端中运行 huggingface-cli login 进行身份验证。之后你将被提示输入你的 Hugging Face 访问令牌,可以在 Hugging Face 的 Settings -> Access Tokens -> User Access Tokens 中找到。
如果你希望使用 Weights & Biases 监控微调进程,请通过运行 wandb login 进行身份验证。请注意,你需要注册一个 Weights & Biases 账户以使用此功能。如果你不想使用它,可以将 finetune.py 文件第 289 行的 report_to 参数从 "wandb" 改为 "none"。我们将在后面进一步讨论 finetune.py 文件。
tarCoder 的 GitHub 仓库包含 Instruct-StarCoder 的微调脚本,可以使用下面提供的代码块获取这些脚本。然而,在我们的测试中,发现脚本中存在一些错误,导致其运行不顺畅且易出现内存错误。为了解决这些问题,我们修改了原始微调脚本并集成了 DeepSpeed 优化,使其运行顺畅且高效。要实现这些更改,请从 我们的仓库 的 src 文件夹下载 finetune.py、`merge_peft_adapters.py` 和 ds_config.json 文件,并将它们放到下载的 StarCoder 仓库的 finetune 文件夹中,以替换原始文件。
git clone https://github.com/bigcode-project/starcoder.git cd starcoder
现在,你可以使用下面提供的命令开始微调过程。请将 --nproc_per_node 标志中的 8 替换为设备上实际可用的 GPU 数量。此外,根据遇到的错误信息,可能需要调整命令中的其他设置或 finetune.py 文件中的设置,因为微调配置高度依赖于硬件规格。具体来说,你可能需要将 --max_steps 标志设置为更大的值,以获得高性能的指令模型。
python -m torch.distributed.run \ --nproc_per_node 8 finetune/finetune.py \ --model_path="bigcode/starcoder"\ --dataset_name="ArmelR/stack-exchange-instruction"\ --subset="data/finetune"\ --split="train"\ --size_valid_set 2000\ --seq_length 1024\ --max_steps 1000\ --batch_size 2\ --streaming\ --input_column_name="question"\ --output_column_name="response"\ --gradient_accumulation_steps 8\ --learning_rate 1e-4\ --lr_scheduler_type="cosine"\ --num_warmup_steps 100\ --weight_decay 0.05\ --lora_r 16\ --output_dir="./checkpoints"
当训练开始时,你应该看到输出如下所示:
trainable params: 35553280 || all params: 15553009664 || trainable%: 0.22859421274773536 Starting main loop Training...
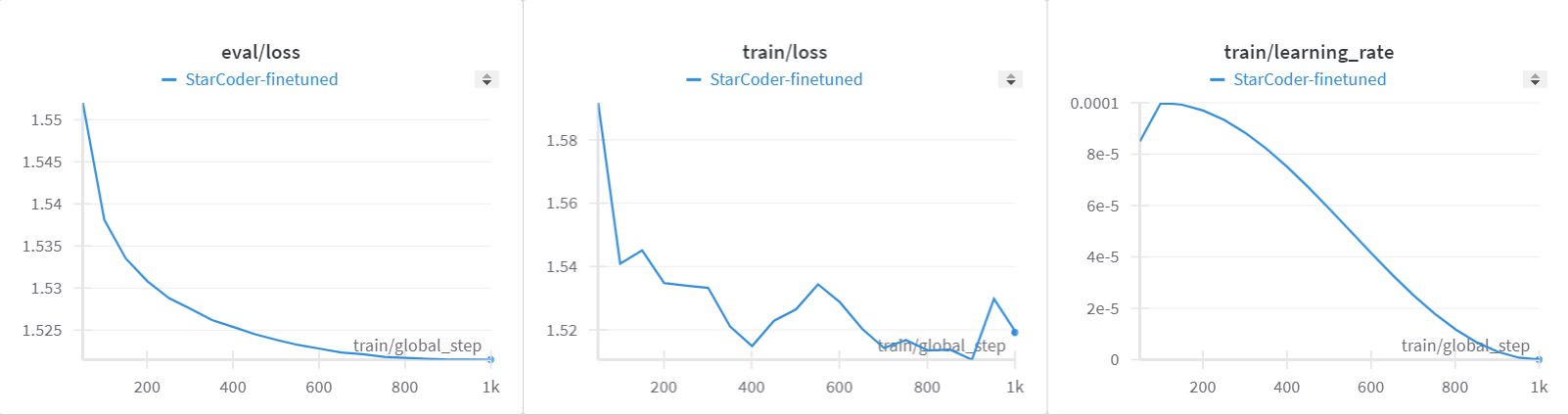
如果你启用了 wandb 进行报告,你将能够查看记录培训进展的图表,如下所示:
微调模型的后处理
适配层是添加到预训练语言模型中的小型神经网络模块,用于微调特定任务。在LoRA中,这些适配器用于微调LLM,而不会显著改变基础模型的参数。将LoRA适配层合并回基础模型,可以在推理时消除延迟。这是通过使用 merge_and_unload() 函数将适配器权重合并到基础模型中来实现的,使模型无需单独加载适配器即可独立运行,从而提高推理速度和效率。
由于我们已经用LoRA训练了模型,因此需要将适配层与基础模型合并,因为我们将在下一部分进行推理。要继续,请执行下面的命令。如果不想将模型上传到Hugging Face,请移除 --push_to_hub 标志。
python finetune/merge_peft_adapters.py --base_model_name_or_path bigcode/starcoder --peft_model_path checkpoints/checkpoint-900 --push_to_hub
StarCoder基础模型和指令模型的推理
在本节中,我们将向您展示如何使用StarCoder基础模型和我们微调的Instruct模型进行代码生成推断。要进行推断,我们需要将两个模型分别加载到 Hugging Face 的 transformers pipelines 中。
import torch
from transformers import pipeline
# 使用device=0表示使用第一个可用的GPU(GPU 0)进行计算。
pipe = pipeline('text-generation', model="bigcode/starcoder", torch_dtype=torch.float16, device=0)
# 你需要在以下命令中将模型名称替换为你在 Hugging Face 上上传的模型名称,以使用你上传的微调后的模型。
# 如果你还没有将模型上传到 Hugging Face,请将模型名称更改为本地路径。
pipe1 = pipeline('text-generation', model="<your_HF_username>/starcoder-checkpoint-900-merged", torch_dtype=torch.float16, device=0)
prompt = "How to calculate the n-th Fibonacci numbers in python?"
generation_config = {'max_length':512, 'truncation':True, 'do_sample':True, 'top_k':40, 'top_p':0.95}
# 基础模型的推断结果 text = pipe(prompt, **generation_config) print(text[0]['generated_text'])
设置`pad_token_id`为`eos_token_id`:0 以便进行开放式生成。
如何在python中计算第n个斐波那契数?"""
def fib(n):
if n <= 1:
return n
else:
return fib(n - 1) + fib(n - 2)
def fibonacci(n):
fibs = [1]
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
fibs.append(a)
return fibs
def fibonacci_yield(n):
a, b = 0, 1
while n > 0:
yield a
a, b = b, a + b
n -= 1
if __name__ == "__main__":
for i in fibonacci_yield(12):
print(i)
# 微调 instruct 模型的推断结果 text = pipe1(prompt, **generation_config) print(text[0]['generated_text'])
设置`pad_token_id`为`eos_token_id`:0 以便进行开放式生成。
如何在python中计算第n个斐波那契数?
我能够使用递归来计算,我发现以下代码非常有用。
我会做一些修改,以便计算第n个数字。
from __future__ import print_function
def fib():
i,j=0,1
while True:
yield i
i,j=j,i+j
fib=fib()
for i in range(30):
print (fib.next())
答案:我发现以下代码非常有用。
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
n = 10
if __name__ == '__main__':
for i in range(n):
print (fib(i), end = " ")
此代码使用递归计算从 `0..n` 的斐波那契数,但比我上面发布的代码稍快一点。
您可以通过尝试不同的提示,比较基础模型和instruct模型的响应,从而真正体验指令微调的效果。