NLP论文速读|Describe-then-Reason: 通过视觉理解训练来提升多模态数学的推理
论文速读|Describe-then-Reason: Improving Multimodal Mathematical Reasoning through Visual Compre- hension Training
论文信息:

简介:
该论文试图解决的问题是开源多模态大型语言模型(MLLMs)在复杂多模态数学推理任务中的表现不佳的问题。尽管这些模型在处理涉及文本和视觉输入的任务时表现出了令人印象深刻的推理能力,但它们在解决数学相关的多模态问题时,相较于专有模型(如GPT-4V和Gemini-Pro)仍有较大差距。这种性能差距限制了开源MLLMs在教育内容生成和统计数据分析等领域的应用潜力。本文的动机在于,尽管通过中间步骤(即理由)的微调可以激发MLLMs的一些数学推理能力,但现有模型在视觉理解方面仍然存在不足,导致对数学图形的解释不准确。为了提高MLLMs在多模态数学推理中的表现,研究者们提出了一种新的训练流程,强调视觉理解训练的重要性,以期通过提升视觉理解能力来增强模型的整体推理能力。
论文方法:

本文提出了一个名为VCAR(Visual Comprehension training in Addition to mathematical Reasoning learning)的两步训练流程,旨在提升MLLMs的视觉理解和数学推理能力。具体分为以下两步:
第一步:视觉理解训练。通过图像描述生成任务来增强MLLMs的视觉理解能力。这一步骤类似于MLLMs的预训练阶段,使用图像描述来对视觉特征和语言表示空间进行初步对齐,从而生成高质量的描述,为后续的数学推理能力发展提供支持。
第二步:数学推理训练。在第一步的基础上,训练MLLMs基于描述生成推理步骤。通过图像描述提供的文本形式的上下文,将数学推理训练从视觉理解的需求中分离出来,使得模型能够在理解视觉内容的同时,专注于数学推理能力的提升。
此外,为了获取上述两步训练的监督信号,研究者们利用Gemini-Pro模型收集了描述性内容和理由,分别用于理解图像和推理答案。为了优化每个训练步骤,本文采用了两个低秩适应(LoRA)模块,分别增强视觉理解和数学推理能力,而无需重新优化所有模型参数。
论文实验:
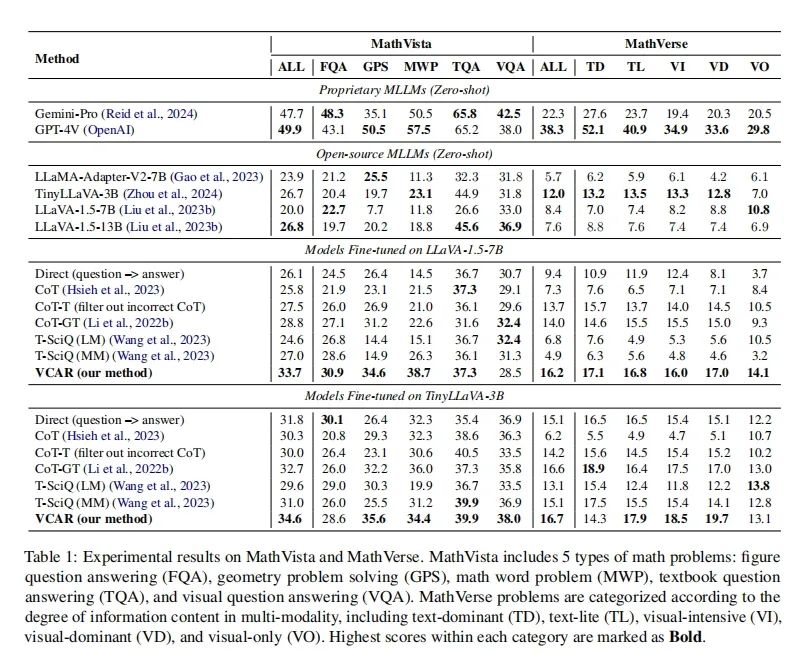
VCAR在MathVista和MathVerse两个基准测试中的表现均优于其他基线方法。这表明VCAR在提升MLLMs的多模态数学推理能力方面是有效的。在MathVista上,VCAR在所有问题类型(FQA、GPS、MWP、TQA、VQA)上的平均准确率比基线方法高出显著。例如,与直接训练(Direct)方法相比,VCAR的平均准确率从26.1%提高到了33.7%。在MathVerse上,VCAR在不同问题类别(TD、TL、VI、VD、VO)上也显示出了一致的性能提升。特别是在视觉需求较高的“visual-only”和“visual-dominant”类别上,VCAR相对基线方法实现了更大的改进。
论文链接:
https://arxiv.org/abs/2404.14604
原文来自:
NLP论文速读|Describe-then-Reason: 通过视觉理解训练来提升多模态数学的推理