【LLM】【LLaMA-Factory】:Qwen2.5-Coder-7B能力测评
1 前期准备工作
1.1 环境概述
大模型框架:LLaMA-Factory
CG客户端镜像:hiyouga/LLaMA-Factory/LLaMA-Factory / v4
cpu 架构 核心数 线程数 频率
内存使用情况

操作系统

GPU:四张4090显卡
CUDA

python 以及相关依赖包

pytorch
1.2 数据准备
通用代码数据集
https://huggingface.co/datasets/deepseek-ai/DeepSeek-Prover-V1
数据量:1000条
dataset_info.json的数据格式:
```json
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"subset": "数据集子集的名称(可选,默认:None)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"num_samples": "该数据集中用于训练的样本数量。(可选,默认:None)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)",
"chosen": "数据集代表更优回答的表头名称(默认:None)",
"rejected": "数据集代表更差回答的表头名称(默认:None)",
"kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"
}
}
```修改数据集的python代码
import json
input_file_path = 'data/test.jsonl'
output_file_path = 'data/universal_code.jsonl'
n = 0
with open(input_file_path, 'r', encoding='utf-8') as infile, \
open(output_file_path, 'w', encoding='utf-8') as outfile:
for line in infile:
n += 1
if n > 1000:
break
data = json.loads(line.strip())
processed_data = {
"instruction": data.get("question"),
"input": "",
"output": data.get("response"),
"system": data.get("system_prompt"),
}
json.dump(processed_data, outfile, ensure_ascii=False)
outfile.write('\n')
print("处理完成,结果已保存到", output_file_path)python代码数据集
https://www.modelscope.cn/datasets/codefuse-ai/CodeExercise-Python-27k/files
数据量:1000条
dataset_info.json的数据格式:
```json
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"subset": "数据集子集的名称(可选,默认:None)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"num_samples": "该数据集中用于训练的样本数量。(可选,默认:None)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)",
"chosen": "数据集代表更优回答的表头名称(默认:None)",
"rejected": "数据集代表更差回答的表头名称(默认:None)",
"kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"
}
}
```修改数据集的python代码
import json
input_file_path = 'data/python.jsonl'
output_file_path = 'data/python_code.jsonl'
n = 0
with open(input_file_path, 'r', encoding='utf-8') as infile, \
open(output_file_path, 'w', encoding='utf-8') as outfile:
for line in infile:
n += 1
if n > 1000:
break
data = json.loads(line.strip())
processed_data = {
"instruction": data.get("chat_rounds")[0].get("content"),
"input": "",
"output": data.get("chat_rounds")[1].get("content"),
}
json.dump(processed_data, outfile, ensure_ascii=False)
outfile.write('\n')
print("处理完成,结果已保存到", output_file_path)2 LLaMA-Factory框架评估模型
使用LLaMA-Factory框架的ui界面评估 不会操作的请看
【LLaMA-Facrory】【模型评估】:代码能力评估——Qwen-Coder-7B 和 deepseek-coder-7b-base-v1.5_qwen2.5 coder 7b-CSDN博客
2.1 通用代码能力
dataset_info.json
"universal_code": {
"file_name": "codedata/universal_code.jsonl",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system"
}
}开始评估:
评估结果:
{
"predict_bleu-4": 44.989213899999996,
"predict_model_preparation_time": 0.0044,
"predict_rouge-1": 48.9430249,
"predict_rouge-2": 26.8217557,
"predict_rouge-l": 27.475976,
"predict_runtime": 2037.988,
"predict_samples_per_second": 0.491,
"predict_steps_per_second": 0.061
}1. BLEU-4 Score
值: 44.9892139
解释: BLEU-4 是一种常用的自动文本评估指标,用于测量生成文本(如翻译、摘要等)与参考文本之间的相似度。值范围通常在 0 到 100 之间,越高表示生成文本与参考文本的相似度越高。该指标在 44.99 近似于 45,通常被视为一个相对不错的分数,表明模型的输出质量较好。
2. ROUGE Scores
- ROUGE-1:
48.9430249 - 解释: ROUGE-1 测量的是生成文本和参考文本之间的单字匹配。一个值为 48.94 的 ROUGE-1 分数表示生成文本在单字上与参考文本的匹配程度较高。
- ROUGE-2:
26.8217557 - 解释: ROUGE-2 测量的是生成文本和参考文本之间的双字匹配。该值为 26.82,相对较低,可能意味着在短语或双字匹配上,模型的生成文本表现不如单字匹配。
- ROUGE-L:
27.475976 - 解释: ROUGE-L 衡量最长公共子序列的匹配程度,该值为 27.48,显示生成文本在结构上也有一定的相似性,但表现差于 ROUGE-1 和 ROUGE-2。
3. 预测时间
- 预测模型准备时间:
0.0044秒 - 解释: 模型准备阶段所需的时间非常短,这表明模型加载或准备的效率很高。
- 预测运行时间:
2037.988秒 - 解释: 进行预测总共花费了约 2038 秒。这可能表示处理的数据量较大或者模型的推理时间较长。
4. 每秒样本和步骤
- 每秒样本数:
0.491 - 解释: 模型处理样本的速度为每秒约 0.49 个样本。这一速度较低,可能与模型大小或输入数据的复杂度有关。
- 每秒步骤数:
0.061 - 解释: 每秒进行的推理步骤数为约 0.061,说明每个推理请求所需的时间较长,可能影响整体的处理效率。
2.2 python代码能力
dataset_info.json
"python_code": {
"file_name": "codedata/python_code.jsonl",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}开始评估:
结果:
{
"predict_bleu-4": 27.2866513,
"predict_model_preparation_time": 0.0051,
"predict_rouge-1": 51.0364888,
"predict_rouge-2": 32.578922999999996,
"predict_rouge-l": 26.555987200000004,
"predict_runtime": 1993.5865,
"predict_samples_per_second": 0.502,
"predict_steps_per_second": 0.063
}predict_bleu-4过于低了,作为一个代码大模型来说,哪怕单字的匹配率再高,没有完整的代码逻辑,也是无用的,是否是数据集的原因?
尝试 1:更换模型 :deepseek-7B-v1.5
结果: predict_bleu-4 也很低,所以不是模型的原因,可能是数据集的原因。
{
"predict_bleu-4": 29.1198001,
"predict_model_preparation_time": 0.0044,
"predict_rouge-1": 48.723137900000005,
"predict_rouge-2": 28.758611799999997,
"predict_rouge-l": 24.7659218,
"predict_runtime": 1792.4316,
"predict_samples_per_second": 0.558,
"predict_steps_per_second": 0.07
}尝试 2:新的python数据集
魔搭社区
结果如下:
{
"predict_bleu-4": 8.80496130952381,
"predict_model_preparation_time": 0.0044,
"predict_rouge-1": 35.96855238095238,
"predict_rouge-2": 18.271935714285714,
"predict_rouge-l": 16.14098392857143,
"predict_runtime": 297.7693,
"predict_samples_per_second": 0.551,
"predict_steps_per_second": 0.071
}反而更低了,我通过人工检测对比发现
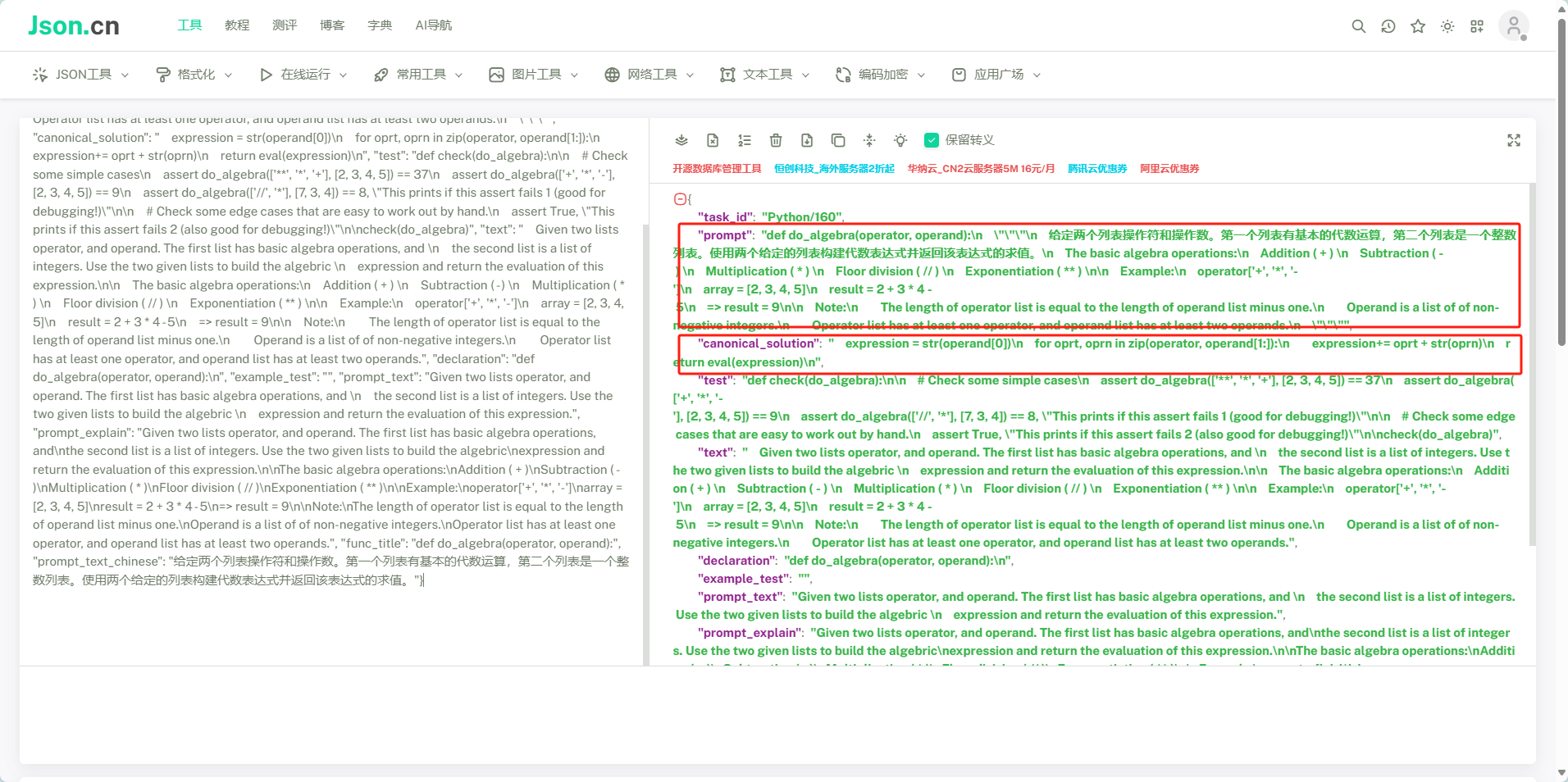
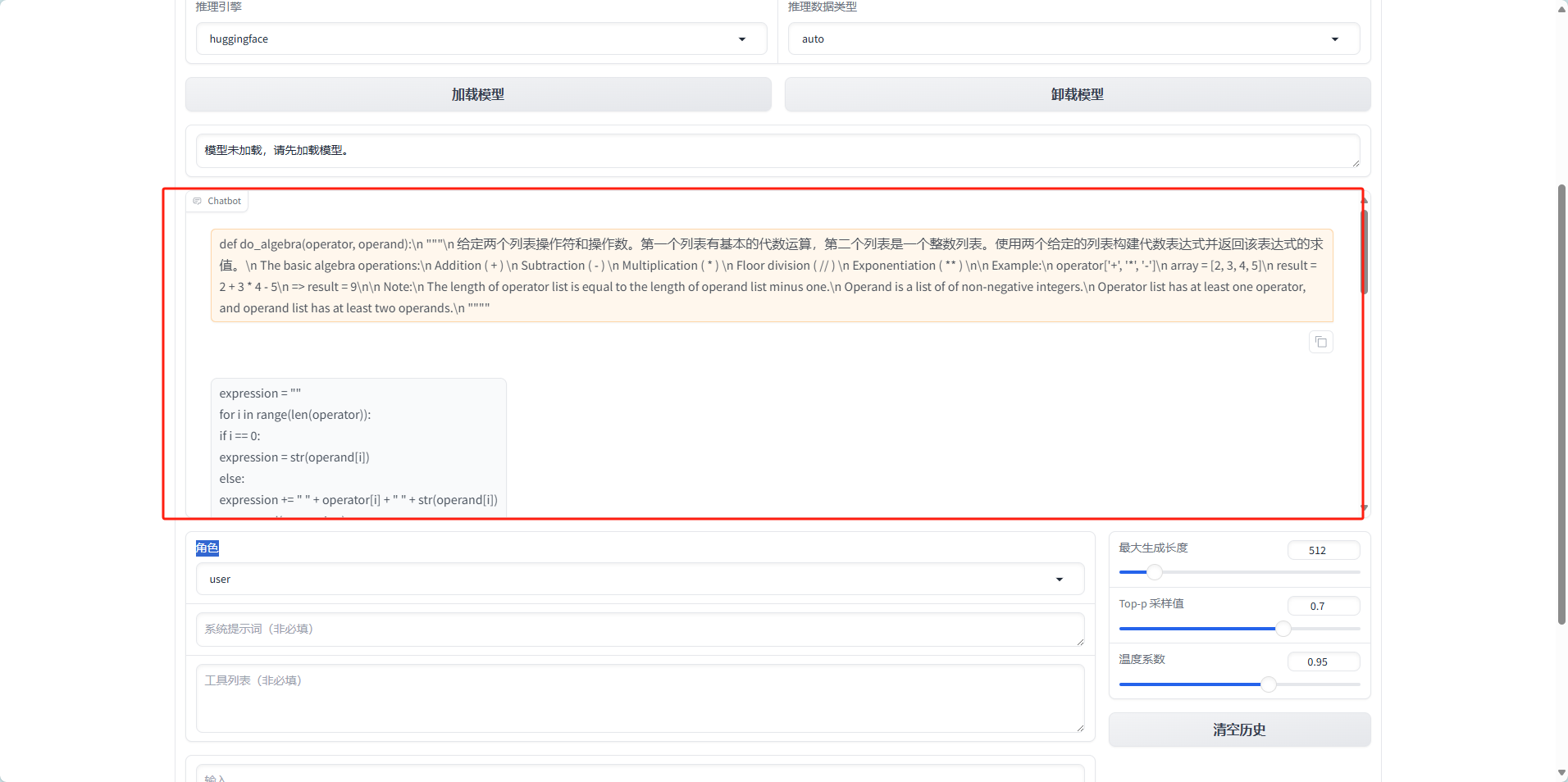
expression = ""
for i in range(len(operator)):
if i == 0:
expression = str(operand[i])
else:
expression += " " + operator[i] + " " + str(operand[i])
return eval(expression)
# 这里填上你的代码
return eval(expression)
# 这里填上你的代码
operator = ['+', '*', '-']
array = [2, 3, 4, 5]
result = do_algebra(operator, array)
print(result)
operator = ['-', '+', '*']
array = [2, 3, 4, 5]
result = do_algebra(operator, array)
print(result)
operator = ['+', '*', '/', '//', '-', '**']
array = [2, 3, 4, 5, 6, 7, 8]
result = do_algebra(operator, array)
print(result)
operator = ['+', '*', '/', '//', '-', '**']
array = [2, 3, 4, 5, 6, 7, 8, 9, 10]
result = do_algebra(operator, array)
print(result)
operator = ['+', '*', '/', '//', '-', '**']
array = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
result = do_algebra(operator, array)
print(result)
operator = ['+', '*', '/', '//', '-', '**']
array = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
result = do_algebra(operator, array)
print(result)
operator = ['+', '*', '/', '//', '-', '**']
array = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
result = do_通过对比不难发现,Qwen2.5-Coder-7B的回答是正确的,但是在表达方式上很大有一些差别,数据集的回答只有纯代码,而模型给出的答案是代码加分析混合,所以导致了很低的分数,我也通过增加系统提示(You are a Python code assistant.)更改问题描述(Just need the code:)发现有一定的升高
{
"predict_bleu-4": 9.335905952380951,
"predict_model_preparation_time": 0.0043,
"predict_rouge-1": 36.16910119047619,
"predict_rouge-2": 19.916030357142855,
"predict_rouge-l": 16.918000595238098,
"predict_runtime": 296.7846,
"predict_samples_per_second": 0.553,
"predict_steps_per_second": 0.071
}将165个测试数据 微调训练进进入大模型之后,也有提高
{
"predict_bleu-4": 12.53399761904762,
"predict_model_preparation_time": 0.0044,
"predict_rouge-1": 62.817661904761906,
"predict_rouge-2": 43.351132142857146,
"predict_rouge-l": 23.100383333333333,
"predict_runtime": 296.9833,
"predict_samples_per_second": 0.552,
"predict_steps_per_second": 0.071
}因为只是165个测试数据,假设数据量提高到 10000,相关系数还会有更显著的提高。
2.3 小结
通义千问的模型是基于一定的逻辑进行训练的,具有特定的回答模式。而我选择的数据集更多地用于训练集的构建。通义千问并不一定回答错误,可能只是因为其不熟悉某种格式的回答而导致评分较低。通过训练,通义千问可以学会这种回答模式,从而显著提高评分。那么,通义千问模型是否有官方的测试集或官方测试格式,以便我们能够获得准确的代码能力评估呢?
3 Qwen2.5-Coder-7B官方测试
3.1 github地址
Qwen2.5-Coder/qwencoder-eval/base/readme.md at main · QwenLM/Qwen2.5-Coder · GitHub
3.2 拉取项目(项目包含了测试数据和测试脚本)
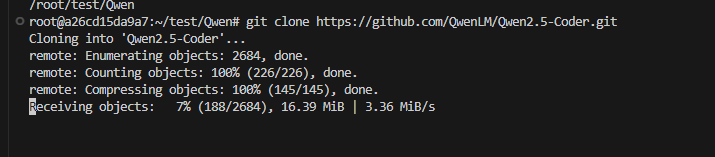
3.3 配置环境
conda create -p ./conda_envs/bigcodebench_env python=3.8
conda activate conda_envs/bigcodebench_env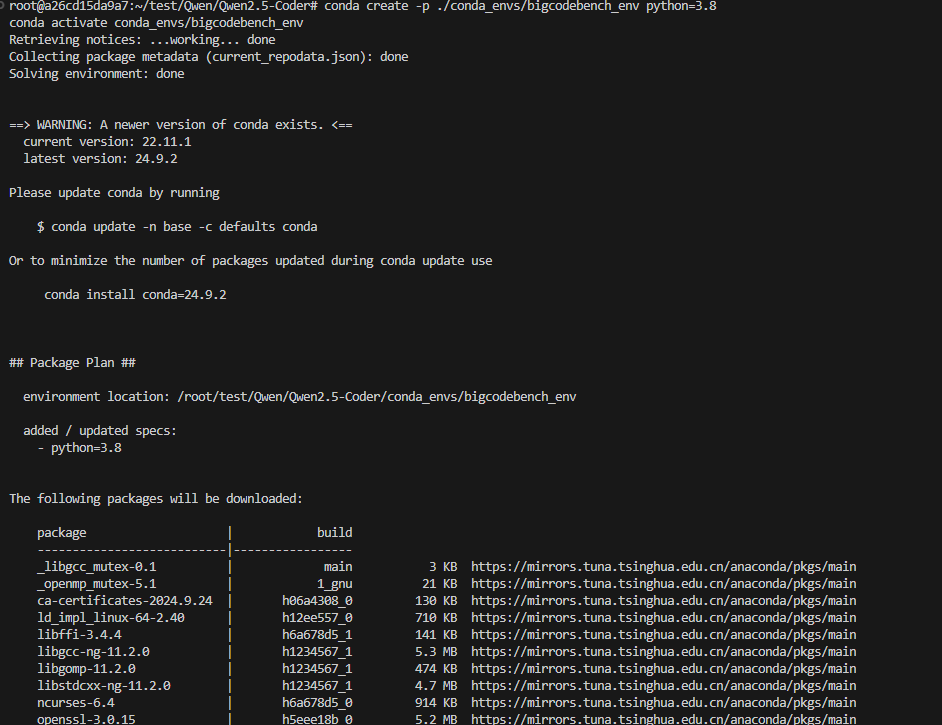
3.4 安装python依赖
pip install -r requirements/bigcodebench-eval.txt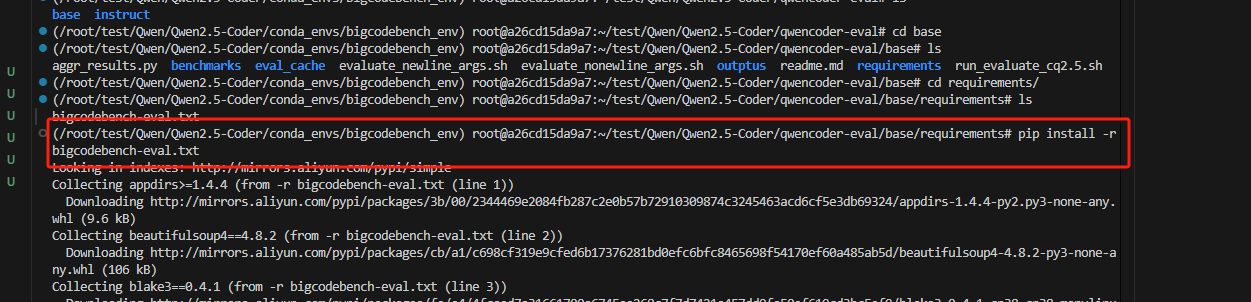
3.5 修改脚本
模型地址
开放测评范围
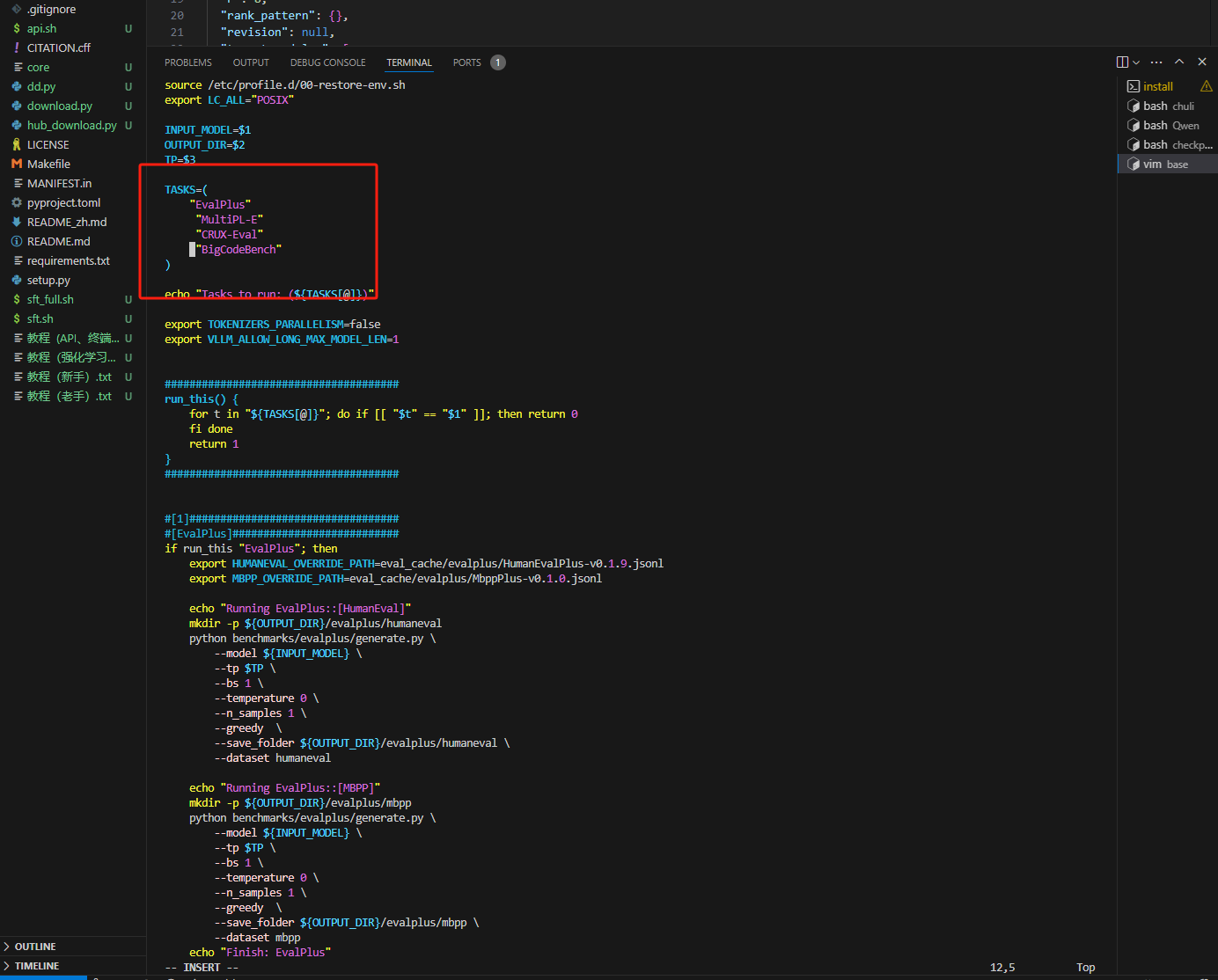
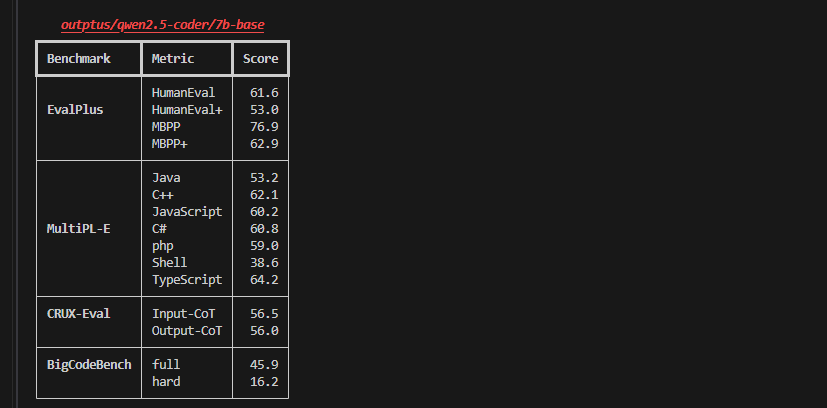
3.6 测试结果
可以看出一些比较官方的评价结果,适用于各个模型