NFS-Ganesha 核心架构解读
NFSv4 简要概述
NFS 这个协议( NFSv2 )最初由 Sun Microsystems 在 1984 年设计提出,由于存在一些不足,因此在随后由几家公司联合推出了 NFSv3。到了 NFSv4 时,开发完全由 IETF 主导,设计目标是:
-
提高互联下的 NFS 访问和性能
-
提供安全性
-
更强的跨平台操作
-
方便后期扩展
我们可以看到 NFSv4 在缓存能力、扩展性、高可用性方面取得了很大的突破,放弃了之前版本的无状态性,采用了强状态机制,客户端和服务端采用了复杂的方式交互,由此保证了服务器端的负载均衡,减少了客户端或服务端的 RTO。
在安全性方面,NFSv4 采用了面向连接的协议,强制使用 RPCSEC_GSS 并且提供基于 RPC 的安全机制。放弃了之前版本中采用的 UDP,采用了 TCP。NFSv4 支持通过次要版本进行扩展,我们可以看到在 NFSv4.1 支持了 RDMA、pNFS 范式以及目录委派等功能。
NFS-Ganesha 的四大优势
2007 年左右,CEA 的大型计算机中心每天都会产生 10TB 左右的新数据,CEA 将这些数据放在由 HSM 组成的 HPSS 中,而这些 HSM 本身提供了 NFS 接口。但是开发者在生产环境中发现 HSM 和 NFS 的桥接仍旧有不少问题,因此开发者决心写一个新的 NFS Daemon 来让 NFS 接口更好的配合 HPSS。
这个项目需要解决以上的问题之外,开发团队还指定了其他目标:
-
可以管理百万级别的数据缓存,从而来避免底层文件系统阻塞
-
除了可以对接 HPSS 以外,还可以对接其他文件系统
-
支持 NFSv4,实现易适配( adaptability ),易扩展,安全等特性
-
从根本上解决软件所带来的性能瓶颈
-
开源
-
支持 Unix 系统
由此 NFS-Ganesha 应运而生,它并不是用来替代内核版本的 NFSv4,相反,NFS Ganesha 是一个全新的程序,可能对比 kernel 版本的 NFSv4,Ganesha 的性能有所欠缺,但是基于 user-space 的方法会带来更多有意思的功能。
灵活的内存分配
首先,user-space 的程序可以分配大量的内存让程序使用,这些内存可以用来建立软件内部缓存,经过测试,我们只需要 4GB 就可以实现百万级别的数据缓存。在一些 x86_64 平台的机器上,我们甚至可以分配更大的内存(16 32GB),来实现千万级别的数据缓存。
更强的可移植性
如果 NFS Ganesha 是 kernel-space 的话,那样 NFS Ganesha 的内部结构只能适应一款特定的 OS,而很难移植到别的 OS 上。另外考虑的是代码本身:在不同的平台上编译和运行的产品比在一个单一平台上开发的产品更安全。 我们开发人员的经验表明,只在单一平台上开发会让开发后期困难重重;它通常会显示在 Linux 上不会轻易检测到的错误,因为资源不一样。
当然可移植性不单单指让 NFS Ganesha 可以运行在不同的 OS 上,能够适配不同的文件系统也是考量之一。在 NFSv2 和 NFSv3 中,由于语义设计上偏向 Unix 类的文件系统,因此基本不可能适配非 Unix 类的文件系统。这一情况在 NFSv4 中大有改观,NFSv4 的语义设计出发点是让 NFS 能尽可能多地适配不同的文件系统,因此加强了文件/目录属性参数的抽象。
Ganesha 设计初衷是成为一个 NFSv4 通用服务器,可以实现 NFSv4 的所有功能,因此也需要适配各种文件系统。在内核中实现这一功能是不容易的(内核编程会有很多限制),然而在 user-space 中实现这一点会便捷一些。
更便捷的访问机制
内核中的 NFSv4 访问用户空间中的服务不是那么方便,因此其引入了 rpc_pipefs 机制, 用于解决用户空间服务的桥梁,并且使用 kerberos5 管理安全性或 idmapd 守护程序来进行用户名转换。然而 Ganesha 不需要这些,它使用常规 API 来对外提供服务。
对接 FUSE
由于 NFS Ganesha 是一个运行在用户空间的程序,因此它还提供了对一些用户空间文件系统( FUSE )的支持,可以让我们直接把 FUSE 挂载在 NFS 上而不需要内核的帮助。
NFS-Ganesha 框架浅析
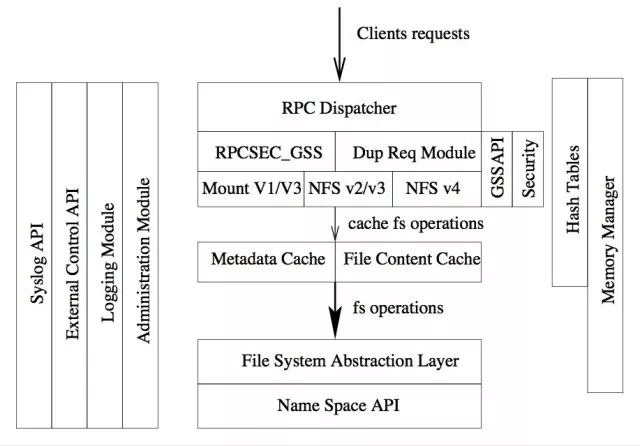
Figure 1 – NFS Ganesha 分层架构图
由上图我们可以看到,Ganesha 是一个基于模块的程序,每个模块都负责各自的任务和目标。开发团队在写代码之前就对每个模块进行了精心的设计,保证了后期扩展的便捷性。比如缓存管理模块只负责管理缓存,任何在缓存管理模块上做出的更改不能影响其他模块。这么做大大减少了每个模块间的耦合,虽然开发初期显得困难重重,但在中后期就方便了很多,每个模块可以独立交给不同开发人员来进行开发、验证和测试。
Ganesha 的核心模块
-
Memory Manager: 负责 Ganesha 的内存管理。
-
RPCSEC_GSS:负责使用 RPCSEC_GSS 的数据传输,通常使用 krb5, SPKM3 或 LIPKEY 来管理安全。
-
NFS 协议模块:负责 NFS 消息结构的管理
-
Metadata(Inode) Cache: 负责元数据缓存管理
-
File Content Cache:负责数据缓存管理
-
File System Abstraction Layer( FSAL ): 非常重要的模块,通过一个接口来完成对命名空间的访问。所访问的对象随后会放置在 inode cache 和 file content cache 中。
-
Hash Tables:提供了基于红黑树的哈希表,这个模块在 Ganesha 里用到很多。
内存管理
内存管理是开发 Ganesha 时比较大的问题,因为大多数 Ganesha 架构中的所有模块都必须执行动态内存分配。 例如,管理 NFS 请求的线程可能需要分配用于存储所请求结果的缓冲器。 如果使用常规的 LibC malloc / free 调用,则存在内存碎片的风险,因为某些模块将分配大的缓冲区,而其他模块将使用较小的缓冲区。 这可能导致程序使用的部分内存被交换到磁盘,性能会迅速下降的情况。
因此 Ganesha 有一个自己的内存管理器,来给各个线程分配需要的内存。内存管理器使用了 Buddy Malloc algorithm,和内核使用的内存分配是一样的。内存分配器中调用了 madvise 来管束 Linux 内存管理器不要移动相关页。其会向 Linux 申请一大块内存来保持高性能表现。
线程管理
管理 CPU 相比较内存会简单一些。Ganesha 使用了大量的线程,可能在同一时间会有几十个线程在并行工作。开发团队在这里用到了很多 POSIX 调用来管理线程,让 Linux 调度进程单独处理每一个线程,使得负载可以覆盖到所有的 CPU。
开发团队也考虑了死锁情况,虽然引入互斥锁可以用来防止资源访问冲突,但是如果大量线程因此陷入死锁状态,会大大降低性能。因此开发团队采用了读写锁,但是由于读写锁可能因系统而异,因此又开发了一个库来完成读写锁的转换。
当一个线程池中同时存在太多线程时,这个线程池会成为性能瓶颈。为了解决这个问题, Ganesha 给每一个线程分配了单独的资源,这样也要求每个线程自己处理垃圾回收,并且定期重新组合它的资源。同时 ”dispatcher thread” 提供了一些机制来防止太多线程在同一时间执行垃圾回收;在缓存层中垃圾回收被分成好几个步骤,每个步骤由单独代理处理。经过生产环境实测,这种设计时得当的。
哈希表
关联寻找功能在 Ganesha 被大量使用,比如我们想通过对象的父节点和名称来寻找对象元数据等类似行为是很经常的,因此为了保证 Ganesha 整体的高性能,关联寻找功能必须非常高效。
为了达到这个目的,开发团队采用了红黑树,它会在 add/update 操作后自动冲平衡。由于单棵红黑树会引发进程调用冲突(多个进程同时 add/update,引发同时重平衡),如果加读写锁在红黑树上,又会引发性能瓶颈。因此开发团队设计了红黑树数组来解决了这个问题,降低了两个线程同时访问一个红黑树的概率,从而避免了访问冲突。
大型多线程守护程序
运行 Ganesha 需要很多线程同时工作,因此设计一个大型的线程守护程序在设计之初尤为重要,线程分为以下不同类型:
-
dispatcher thread: 用于监听和分发传入的 NFS、MOUNT 请求。它会选择处于最空闲的 worker 线程然后将请求添加到这个 worker 线程的待处理列表中。这个线程会保留最近 10 分钟内的请求答复,如果在 10 分钟内收到相同指令(存在哈希表并用 RPC Xid4 值寻址),则会返回以前的请求回复。
-
worker thread: Ganesha 中的核心线程,也是使用最多的线程。worker 线程等待 dispatcher 的调度,收到请求后先对其进行解码,然后通过调用 inode cache API 和 file content API 来完成请求操作。
-
statistics thread: 收集每个 module 中的线程统计信息,并定期用 CSV 格式记录数据,以便于进一步处理。
-
admin gateway: 用于远程管理操作,包括清楚缓存,同步数据到 FSAL 存储端,关闭进程等。ganeshaadmin 这个程序专门用于与 admin gateway 线程交互。
缓存处理
在上文中提到,Ganesha 使用了大片内存用于建立元数据和数据缓存。我们先从元数据缓存开始讲起。metadata cache 存放在 Cache Inode Layer( MDCache Layer )层 。每个实例对应一个命名空间中的实例(文件,符号链接,目录)。这些 Cache Inode Layer 中的实例对应一个 FSAL 中的对象,把从 FSAL 中读取到的对象结构映射在内存中。
Cache Inode Layer 将元数据与对应 FSAL 对象 handle 放入哈希表中,用来关联条目。初版的 Ganesha 采用 ’write through’ 缓存策略来做元数据缓存。实例的属性会在一定的时间(可定义)后过期,过期后该实例将会在内存中删除。每个线程有一个 LRU(Least Recently Used) 列表,每个缓存实例只能存在于 1 个线程的 LRU 中,如果某个线程获得了某个实例,将会要求原线程在 LRU 列表中释放对应条目。
每个线程需要自己负责垃圾回收,当垃圾回收开始时,线程将从 LRU 列表上最旧的条目开始执行。 然后使用特定的垃圾策略来决定是否保存或清除条目。由于元数据缓存应该非常大(高达数百万条目),因此占满分配内存的 90%(高位)之前不会发生垃圾回收。 Ganesha 尽可能多得将 FSAL 对象放入缓存的‘树型拓扑’中,其中节点代表目录,叶子可代表文件和符号链接;叶子的垃圾回收要早于节点,当节点中没有叶子时才会做垃圾回收。
File Content Cache 数据缓存并不是独立于与 Inode Cache,一个对象的元数据缓存和数据缓存会一一对应(数据缓存是元数据缓存的‘子缓存’),从而避免了缓存不统一的情况。文件内容会被缓存至本地文件系统的专用目录中,一个数据缓存实例会对应 2 个文件:索引文件和数据文件。数据文件等同于被缓存的文件。索引文件中包含了元数据信息,其中包含了对重要的 FSAL handle。索引文件主要用于重建数据缓存,当服务器端崩溃后没有干净地清掉缓存时,FSAL handle 会读取索引文件中的信息来重建元数据缓存,并将其指向数据文件,用以重建数据缓存实例。
当缓存不足时,worker thread 会查看 LRU 列表中很久未被打开的实例,然后开始做元数据缓存回收。当元数据缓存回收开始时,数据缓存的垃圾回收也会同时进行:在回收文件缓存实例时,元数据缓存会问询数据缓存是否认识该文件实例,如果不认识则代表该数据缓存已经无效,则元数据回收正常进行,并完成实例缓存回收;如果认识,对应的文件缓存以及数据缓存均会被回收,随后对应的元数据缓存也会被回收。这样保证了一个数据缓存有效的实例不会被回收。
这种方式很符合 Ganesha 的架构设计:worker 线程可以同时管理元数据缓存和数据缓存,两者一直保持一致。Ganesha 在小文件的数据缓存上采用 ’write back’ 策略,如果文件很大的话则会直接读取,而不经过缓存;可以改进的地方是可以把大文件分割成部分放入缓存中,提高读写效率。
FSAL(File System Abstraction Layer)
FSAL 是相当重要的模块。FSAL 本身给 Inode Cache 和 File Content Cache 提供了通用接口,收到请求后会调用具体的 FSAL(FSAL_SNMP, FSAL_RGW 等)。FSAL 中的对象对应一个 FSAL handle。由于 FSAL 的语义设计与 NFSv4 很相似,因此开发和可以自己编写新的 FSAL API 来适配 Ganesha。Ganehsa 软件包还提供了 FSAL 源代码模板。
NFS Ganesha 对接 Ceph RGW 实例
介绍了许多 NFS Ganesha 的内部构造,这边通过一个 NFS Ganesha 对接 Ceph RGW 的例子来阐述一下代码 IO:
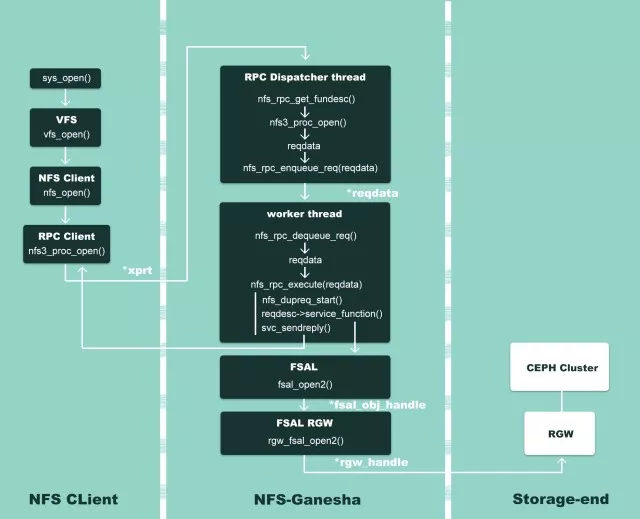
Figure 2 – NFS Ganesha workflow
以 open( ) 为例来,如上图所示。首先用户或者应用程序开始调用文件操作,经过系统调用 sys_open( ),到达虚拟文件系统层 vfs_open( ),然后交给 NFS 文件系统 nfs_open( )来处理。NFS 文件系统无法操作存储介质,它调用 NFS 客户端函数 nfs3_proc_open( ) 进行通信,把文件操作转发到 NFS Ganesha 服务器。
Ganesha 中监听客户端请求的是 Dispatcher 这个进程:其中的 nfs_rpc_get_funcdesc( ) 函数通过调用 svc_getargs( )来读取 xprt(rpc 通信句柄)中的数据,从而得到用户的具体请求,然后将这些信息注入到 reqdata 这个变量中。随后 Dispatcher 这个线程会把用户请求- reqdata 插入到请求队列中,等待处理。
Ganesha 会选择一个最空闲的 worker thread 来处理请求:通过调用 nfs_rpc_dequeue_req( )将一个请求从等待队列中取出,随后调用 nfs_rpc_execute( ) 函数处理请求。Ganesha 内部自建了一个请求/回复缓存,nfs_dupreq_start( ) 函数会在哈希表中寻找是否有一样的请求,如果找到,则寻找到对应回复,然后调用 svc_sendreply( ) 将回复发送给客户端,从而完成一个请求的处理。
如果 Ganesha 没有在哈希表中找到一样的请求,nfs_dupreq_start( ) 这个函数会在缓存中新建一个请求,随后调用 service_function( ),也就是 nfs_open( )。FSAL (filesystem abstract layer) 收到 nfs_open( ) 调用请求后,会调用 fsal_open2( ) 函数。
由于我们已经在初始化阶段,在 ganesha.conf 指定了 FSAL 为 RGW,并且在 FSAL/FSAL_RGW/handle.c 文件下我们已经重定向了 FSAL 的操作函数,因此 fsal_open2( ) 实际会调用 rgw_fsal_open2( ),通过使用 librgw 来进行具体操作。请求完成后,回复会插入到对应哈希表中,与请求建立映射,随后回复通过 svc_sendreply( ) 发送给客户端。由此完成了 sys_open( ) 这个函数的调用。