模型解释新方向!浙大揭秘LLM隐层之间的知识流动!

作者:bhn
论文:https://arxiv.org/pdf/2405.17969 - NIPS2024
代码:https://github.com/zjunlp/KnowledgeCircuits
本文中:
knowledge editing=知识编辑;
machine unlearning=遗忘学习;
detoxification=祛毒;
knowledge circuits=知识回路;
背景
大量的参数赋予了大模型强大的能力的同时也带来了一些缺陷,如幻觉,不安全的行为。由于模型复杂的知识存储机制,这些问题的解决变得十分复杂。
目前的工作进行两个方向的尝试,一种是认为事实以键值对的形式存储在mlp中,在这个基础上人们使用知识编辑,遗忘学习,祛毒等方法对模型的mlp层修改,以缓解修复模型的缺陷。
另一种思路认为,知识不是单独的存储在某一区域的,而是由不同的组件共同构成的,本文中称为知识回路。
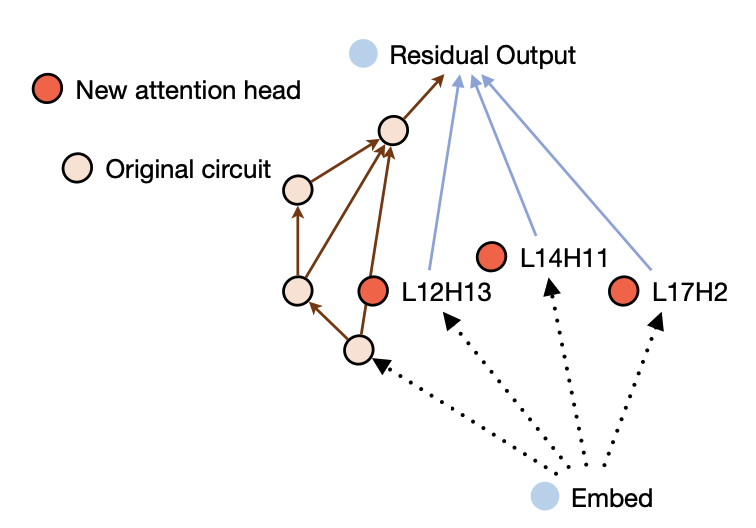
这篇论文的工作分为四部分发现Transformer架构中的知识回路:解释知识回路的概念和知识回路是如何发现的。
知识回路揭示隐式神经知识表征:通过一个简单的案例分析知识回路是如何解释知识表征的。
知识回路阐明知识编辑的内部机制:通过知识回路解释对ROME和FT这两种知识编辑方法进行解释。
知识回路促进解释语言模型行为:通过知识回路解释模型的幻觉和上下文学习背后的原因。
本文的工作和结果分析
发现Transformer架构中的知识回路
知识回路:相对于知识编辑关注知识的存储区域,知识回路更关注信息的流动。将语言模型看作一个由组件(input,output,attention_head,mlp)为节点,连接组件的边(残差流),共同组成的一个计算图,信息在这些组件中流动。
下图为模型回答“The official language of France is ”这个问题时,所经过回路,具体的回路发现在下面介绍。
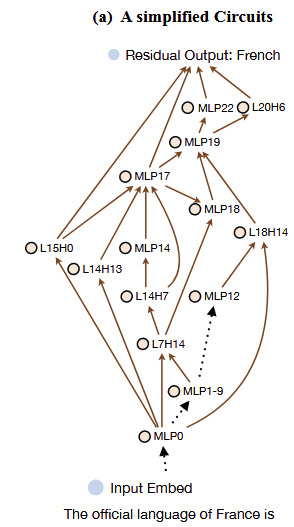
图3: 在回路中,MLP14类似的点代表着第14层的MLP层;L18H14代表着第18层的第14个注意力头,点之间的褐色连线代表这他们之间的信息流动。
回路发现:简单的来讲,回路的发现通过消融节点之间的边(即参数置为0),判断这个边对于知识是否为关键边。对于上图的回路来说,一个事实三元组“(Franch, official language, French)” ,让模型补全”The official language of France is “这句话,预测客体French,在这个过程中,消融组件之间的边,判断边对于这个事实的重要性,保留重要的边,从而构造出了关于这个事实的回路。(具体实现请查看代码)
知识回路揭示隐式神经知识表征

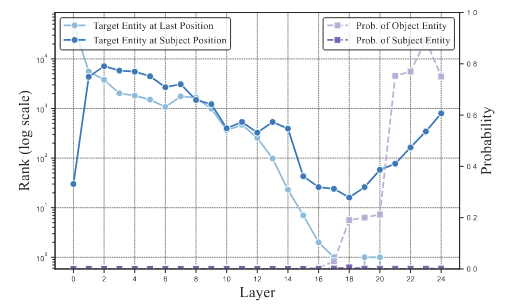
图5:Target Entity at Last Position表示”French“这个词在”is“位置时输出logits的rank。Target Entity at Subject Position表示“French”这个词在“France”位置时输出logits的rank—越低rank越高。Prob. of Entity表示实体的可能性—越高可能性越大。
从图5可以看出,在MLP17层以后可以的看到Object Entity的可能性开始渐渐上升。让我们注意到图四a,连接MLP17的节点由L14H13、L14H7等。在图四b中可以发现,L14H13的输出logits更加关注“Language”这类关系型token,L14H7则是将信息从主体“France”流动到最后一个位置。
从这个简单的例子,该论文猜想,不同的注意力头起不同的作用,L14H13这类头更加关注关系信息,而L14H7则是在主体位置提取关系信息。而MLP层则是结合之前组件提供的信息,提高目标token的最高rank。
知识回路阐明知识编辑的内部机制

对于同一个问题“Platform Controller Hub is created by Microsoft.”,原始模型在L15H3更加聚焦于一些firmware这类词,并且正确答案“Intel”的可能性一直为0。而对于ROME编辑过的模型从15层开始“Intel”的可能性渐渐上升。而对于FT编辑方法,“Intel”从第0层就开始上升。
从ROME图中Subject Position的曲线总是在Last Position上面,并且他们在一起下降,并且在15层开始慢慢上升(L15H3已经开始获取了真确的答案)。可以得出ROME方法会将正确的信息添加到主体token位置,并且由注意力头进行信息提取。
FT图中,Last Position的rank一开始就降到了最低,Object Entity的可能性在MLP0就开始上升,可以推断出,FT编辑方法会直接将知识写入组件中去。
从“Windows Server 2003 is created by Intel.”问题可以看出知识编辑这类方法会带来一些副作用,会影响到不相关的知识。
知识回路促进解释语言模型行为
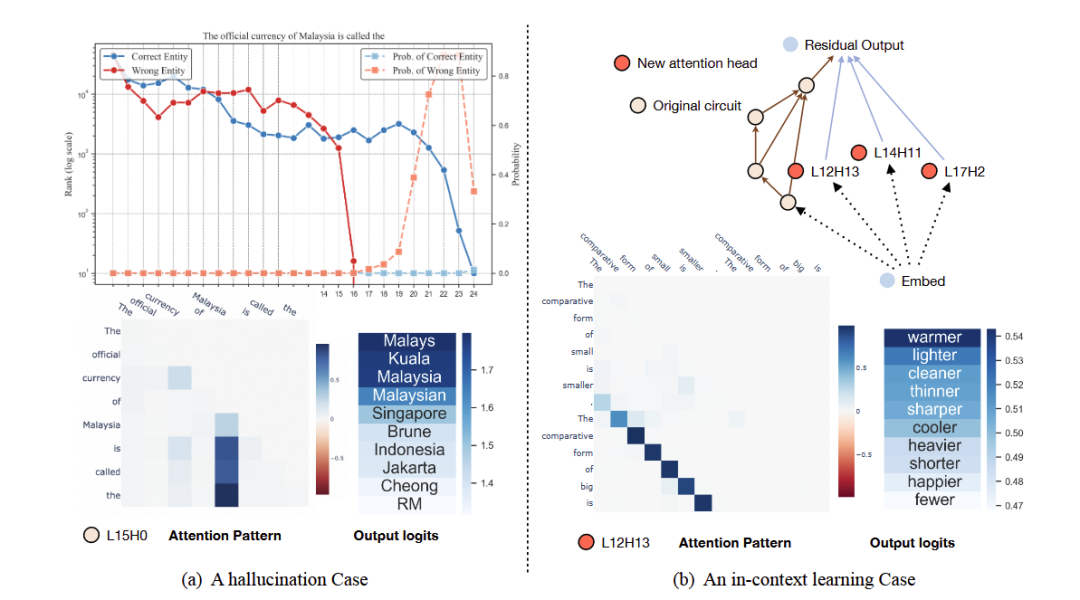
图7a可以看出当幻觉发生时,模型没有在早些层将正确的知识传递到最后的token,在15层L15H10这个注意力头选中了错误的信息,尽管在20-22层,正确实体的rank也快速的上升。
图7b中,ICL为回路添加了额外的注意力头,并且可以注意到,L12H13更加注意示例文本:“The comparative form of small is smaller”。
局限性
目前通过回路对知识编辑的解释还不够完善,并不能阐明知识编辑造成副作用的原因。
目前回路偏向于解释,可操作性比较低。
注:由于论文工作内容很深入,如感兴趣,推荐亲自阅读。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦