AttriPrompter:基于属性语义的自动提示,用于通过视觉-语言预训练模型实现零样本细胞核检测|文献速递-基于深度学习的病灶分割与数据超分辨率
Title
题目
AttriPrompter: Auto-Prompting with AttributeSemantics for Zero-shot Nuclei Detection viaVisual-Language Pre-trained Models.
AttriPrompter:基于属性语义的自动提示,用于通过视觉-语言预训练模型实现零样本细胞核检测。
01
文献速递介绍
在医学图像处理领域,检测苏木精和伊红(H&E)染色图像中的细胞核具有重要意义。它在多种疾病的诊断中起着关键作用,并为后续的多项分析奠定了基础,包括预后评估和治疗方案制定。为了解决上述任务,研究人员提出了多种完全监督的方法。然而,与大多数自然物体相比,H&E图像中的细胞核密度较高,即它们在空间上彼此靠近。细胞核通常呈聚集状态,难以在不遗漏的情况下定位所有目标细胞核。因此,检测的标注过程需要专业知识,耗时费力,成本高且容易出错。
为应对上述挑战,研究人员将焦点转向无监督学习。然而,当前的无监督方法往往具有强烈的经验特征,这意味着用户需要根据主观经验设置某些参数,或是这些方法本质上依赖于主观经验。例如,基于阈值的方法,需要根据经验设置阈值。自监督方法如SSNS主观地假设对放大倍数的分类有助于识别细胞核的大小和纹理。一些基于领域适应的方法在源域与目标域对齐时包含了经验设计条件,如PDAM[10]和DARCNN。这些方法不可避免地在模型设计过程中引入主观偏差。
目前,大规模视觉-语言预训练模型(VLPMs)通过从大量网络来源的文本-图像对中学习对齐的文本和图像特征,获得了语义丰富、多功能且可迁移的视觉特征,从而催生了新的无监督学习方法。VLPMs已成功应用于图像处理、描述生成、视图合成和零样本目标检测等多种任务中。值得注意的是,基于语言-图像对齐的预训练模型GLIP在零样本目标检测和短语定位中展示了令人印象深刻的能力。近期研究逐渐关注VLPMs在医学影像领域的应用。基于以上讨论,本文旨在建立一个基于VLPMs的无监督零样本细胞核检测系统。
Aastract
摘要
Large-scale visual-language pre-trained models (VLPMs) have demonstrated exceptional performancein downstream object detection through text prompts fornatural scenes. However, their application to zero-shotnuclei detection on histopathology images remains relatively unexplored, mainly due to the significant gap between the characteristics of medical images and the weboriginated text-image pairs used for pre-training. This paperaims to investigate the potential of the object-level VLPM,Grounded Language-Image Pre-training (GLIP), for zeroshot nuclei detection. Specifically, we propose an innovative auto-prompting pipeline, named AttriPrompter, comprising attribute generation, attribute augmentation, andrelevance sorting, to avoid subjective manual prompt design. AttriPrompter utilizes VLPMs’ text-to-image alignmentto create semantically rich text prompts, which are then fedinto GLIP for initial zero-shot nuclei detection. Additionally,we propose a self-trained knowledge distillation framework,where GLIP serves as the teacher with its initial predictionsused as pseudo labels, to address the challenges posedby high nuclei density, including missed detections, falsepositives, and overlapping instances. Our method exhibitsremarkable performance in label-free nuclei detection, outperforming all existing unsupervised methods and demonstrating excellent generality. Notably, this work highlightsthe astonishing potential of VLPMs pre-trained on naturalimage-text pairs for downstream tasks in the medical fieldas well.
大规模视觉-语言预训练模型(VLPMs)在通过文本提示进行自然场景的下游目标检测中表现出色。然而,它们在组织病理学图像上的零样本细胞核检测应用仍然相对未被探索,主要原因是医学图像特征与预训练中使用的网络来源的文本-图像对之间存在显著差异。本文旨在探讨目标级VLPM“基于语言-图像对的预训练”(GLIP)在零样本细胞核检测中的潜力。具体来说,我们提出了一种创新的自动提示生成流程,名为AttriPrompter,包括属性生成、属性增强和相关性排序,旨在避免主观的手动提示设计。AttriPrompter利用VLPM的文本-图像对齐功能,生成语义丰富的文本提示,随后将其输入到GLIP中用于初始零样本细胞核检测。此外,我们提出了一个自训练的知识蒸馏框架,GLIP作为教师模型,利用其初始预测作为伪标签,以应对高密度细胞核检测带来的挑战,包括漏检、误检和实例重叠问题。我们的方法在无标注的细胞核检测中表现出色,优于所有现有的无监督方法,并展现出良好的通用性。值得注意的是,本研究还突显了预训练于自然图像-文本对的VLPMs在医学领域下游任务中的巨大潜力。
Figure
图
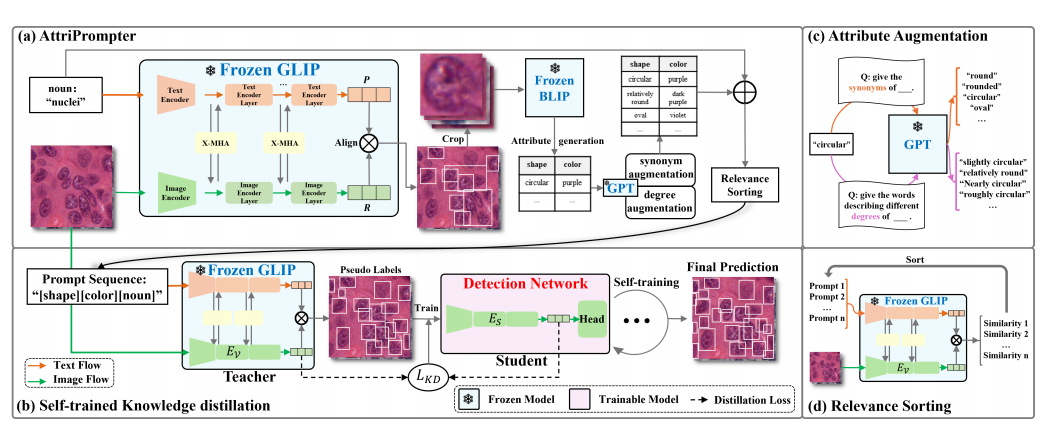
Fig. 1. Method illustration. (a) AttriPrompter: utilizing GLIP [16] and BLIP [14] for attribute generation; exploiting GPT model [22] for attributeaugmentation; ending with relevance sorting of prompts composed of attribute words and medical nouns. (b) Iterative optimization through selftrained knowledge distillation. Panels (c) and (d) detail the attribute augmentation and relevance sorting processes.
图 1. 方法示意图。(a) AttriPrompter:利用GLIP [16] 和 BLIP [14] 进行属性生成;使用GPT模型 [22] 进行属性增强;最后通过将属性词与医学名词组合的提示词进行相关性排序。(b) 通过自训练知识蒸馏进行迭代优化。面板 (c) 和 (d) 详细展示了属性增强和相关性排序过程。
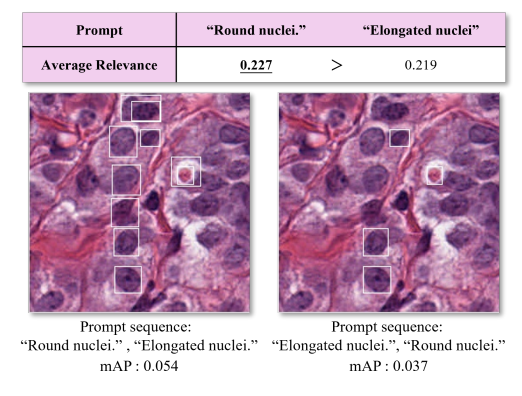
Fig. 2. Positioning higher relevance prompts earlier in the sequencepositively influences GLIP, enhancing prediction accuracy. The boxesare shown in white. The values of mAP are calculated across the entireMoNuSeg testing set.
图 2.将相关性较高的提示放在序列前面,能够积极影响GLIP,提高预测准确性。框的颜色为白色。mAP值是根据整个MoNuSeg测试集计算得出的。
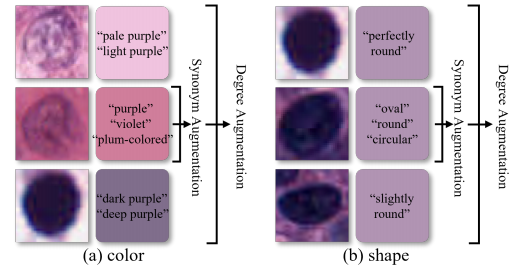
Fig. 3. Semantic coverage of nuclei with diverse appearances afterattribute augmentation. (a) Augmentation for color “purple”. (b) Augmentation for shape “round”. Adjectives within the same frame aresynonyms, while those in different frames represent varying degrees ofthe attribute
图 3. 属性增强后,具有不同外观的细胞核的语义覆盖。(a) 针对颜色“紫色”的增强。(b) 针对形状“圆形”的增强。同一框内的形容词是同义词,而不同框中的形容词表示属性的不同程度。

Fig. 4. Comparison output visualizations. The 1 st ∼ 4 th rows: MoNuSeg, the 5 th ∼ 8 th row: CoNSeP. Column: (a) WSPointA; (b) WSPPointA;(c) WSMixedA; (d) WNSeg; (e) SSNS; (f) PDAM; (g) DARCNN; (h) Freesolo; (i) SOP; (j) PSM; (k) CutLER; (l) VL-PLM; (m) VLDet; (n) MIU-VL; (o)VLPM-NuD; (p) ours; (q) fully-supervised YOLOX. Green, red, and yellow boxes denote true positives, false positives, and false negatives.
图 4. 比较输出可视化。第 1 至 4 行:MoNuSeg,第 5 至 8 行:CoNSeP。列:(a) WSPointA;(b) WSPPointA;(c) WSMixedA;(d) WNSeg;(e) SSNS;(f) PDAM;(g) DARCNN;(h) Freesolo;(i) SOP;(j) PSM;(k) CutLER;(l) VL-PLM;(m) VLDet;(n) MIU-VL;(o) VLPM-NuD;(p) 我们的方法;(q) 完全监督的 YOLOX。绿色、红色和黄色框分别表示真正例、假正例和假负例。
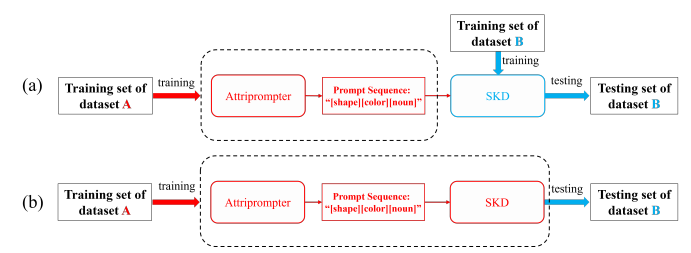
Fig. 5. Two cross-domain experiments: (a) the cross-domain capacity ofAttriprompter, (b) the domain shift study for the whole system. “DatasetA” denotes the source domain, “Dataset B” denotes the target domain.
图 5. 两个跨领域实验:(a) AttriPrompter的跨领域能力,(b) 整个系统的领域转移研究。“数据集A”表示源领域,“数据集B”表示目标领域。
Table
表

TABLE Imean average precision (map) on the monuseg testing set using varied text prompts. the prompt descriptions incrementally increase in detail from top to bottom.
表 I:在MoNuSeg测试集上使用不同文本提示的平均精度(mAP)。从上到下,提示描述的详细程度逐渐增加。
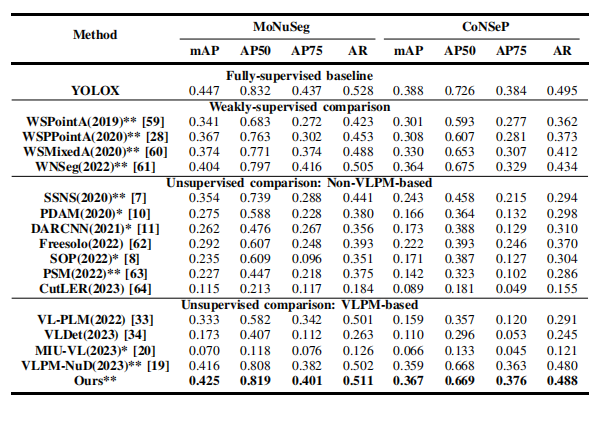
TABLE II comparison results on monuseg [53] and consep .methods with a “*” mark are based on medical images, andthose with a “**” mark are specifically based on h&e images.the rest are originally based on natural images and wereimplemented for nuclei detection.
表 II在 MoNuSeg [53] 和 ConSep 上的比较结果。带有“*”标记的方法基于医学图像,而带有“**”标记的方法专门基于 H&E 图像。其余方法最初基于自然图像,并被应用于细胞核检测。
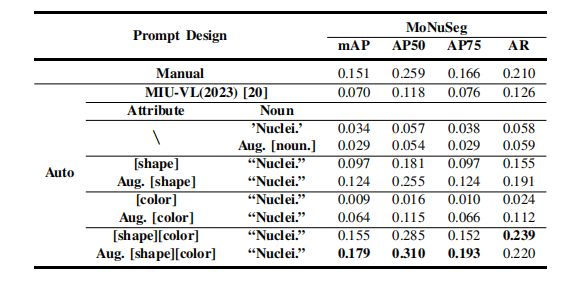
TABLE IIIablation study on automatic versus manual prompt design.this study excludes self-trained knowledge distillation fordirect prompt quality evaluation. the best results aremarked in bold.
表 III关于自动与手动提示设计的消融研究。该研究排除了自训练知识蒸馏,以便直接评估提示质量。最佳结果用粗体标记。

TABLE IV ablation study on attriprompter components. this studyexcludes self-trained knowledge distillation for directprompt quality evaluation. the best results are marked inbold.
表 IV关于AttriPrompter组件的消融研究。该研究排除了自训练知识蒸馏,以便直接评估提示质量。最佳结果用粗体标记。
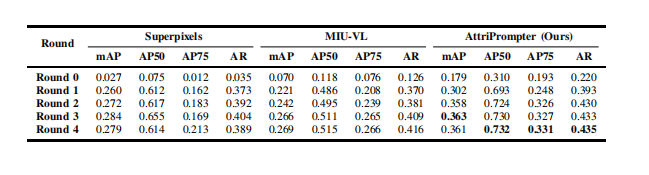
TABLE Vresults of adopting different pseudo label generationmethods for self-training. the results labeled "ours" didnot incorporate knowledge distillation for fair comparison.the best results are marked in bold.
表 V采用不同伪标签生成方法进行自训练的结果。标记为“OURS”的结果未使用知识蒸馏,以确保公平比较。最佳结果用粗体标记。
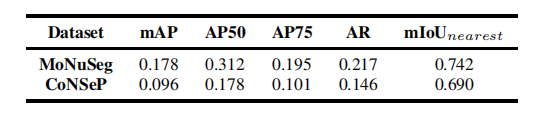
TABLE VI table vipseudo labels quality: direct comparison with real labels.
表 VI伪标签质量:与真实标签的直接比较。

TABLE VII pseudo labels quality: comparison between using pseudolabels generated by attriprompter and using differentproportions of real labels in the skd framework. the bestand second-best values are highlighted in bold andunderlined, respectively.
表 VII伪标签质量:对比使用 AttriPrompter 生成的伪标签和在 SKD 框架中使用不同比例的真实标签。最佳值和次佳值分别用 粗体 和 下划线 标出。
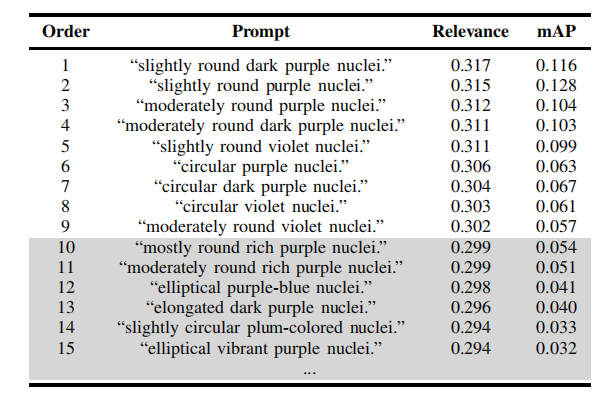
TABLE VIIIquantitative analysis of the optimal prompts on themonuseg dataset. the top n=9 prompts are selected aftercross-validation. the remaining prompts are discarded andmarked with a gray background.
表 VIII在 MoNuSeg 数据集上对最优提示的定量分析。经过交叉验证后选择排名前 N=9 的提示,其余提示被丢弃并标记为灰色背景。

TABLE IXablation study on the knowledge distillation loss lkd. notusing lkd implies reliance solely on ldet forself-training. the best results are marked in bold.
表 IX关于知识蒸馏损失 LKD 的消融研究。不使用 LKD 意味着仅依赖 LDet 进行自训练。最佳结果用 粗体 标记
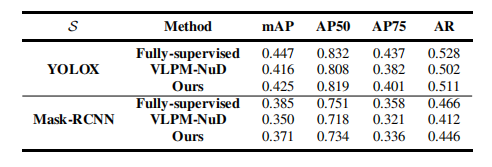
TABLE X ablation study on the architecture of s.
表 X关于S架构的消融研究。
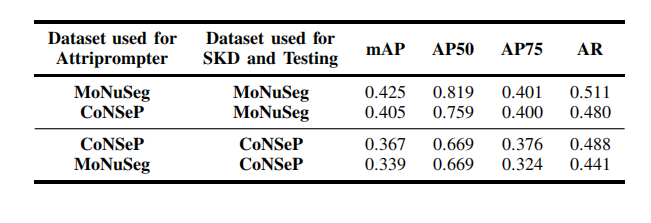
TABLE XI validation of the cross-domain capacity of attriprompter.
表 XIAttriPrompter跨领域能力的验证。

TABLE XII domain shift study on the proposed framework. "→"indicates the direction from the source domain to the targetdomain. standard zero-shot strategies do not undergo anycross-domain process and are marked with a graybackground. the best results are marked in bold.
表 xii所提出框架的领域转移研究。“→”表示从源领域到目标领域的方向。标准零样本策略未经过任何跨领域处理,并用灰色背景标出。最佳结果用粗体标记。