PdServer:调用MidjourneyAPI完成静夜思图文生成
欢迎沟通讨论,WX: cdszsz。公号:AIGC中文站。
今天我们将使用PdServer,通过Qwen大模型完成古诗的解析与prompt的生成,然后调用MidjourneyAPI完成图片的生成。有了文案和图片,我们就可以将其生成为一个古诗讲读视频。从生成图片上看,效果还是不错的,那就让我们开始吧!

项目地址:
https://github.com/deanChang2021/PdServer_llm.git
目录
PdServer的一些升级
准备QWEN2.5环境
准备MidjourneyAPI环境
下载代码
prompt优化
请求Midjourney
运行
总结
-
PdServer的一些优化
这不是本文的重点,只是介绍PdServer最近的优化,你可以跳过。
1)实现了peewee的快捷ORM,并在初始化过程中,写入了admin用户,当我们在登陆时,可以使用admin/admin123进行登陆操作,相关代码在PdBaseKit包中。

2)对结构进行了调整,并且允许将不同的类型的路由写入不同的文件中,然后进行注册即可。
def register_blueprints(_app):from server.apps import sys_appfrom server.apps import document_app"""你可以对不同的路由类型写入不同的文件,但一定要在此完成注册"""_app.include_router(sys_app.router, prefix="/v1/api/trigger")_app.include_router(document_app.router, prefix="/v1/api/trigger")
将service放到了db包中
service将会使用我们的orm中的表。
-
QWEN2.5环境准备
我们在这一篇文章中已经介绍过Ollama与QWEN的安装,大家可以参考,这里就不再赘述。
【五天入门RAG】第二天:使用langchain完成一个最简单的代码任务
-
MidjourneyAPI环境准备
由于众所周知的原因,我们无法直接访问midjourney接口,因此我们将使用aigc中文站的midjourney接口。官网链接如下:
https://cnaigc.net
(aigc中文站首页)
在本步骤中,我们主要获取midjourneyAPI以及token,以及了解对应的生成请求流程。
获取token
1)点击右上角,微信扫码登陆;

2)f12打开浏览器调器,然后点击“前往midjourney中文站”;
3)如下图所示,在右侧找到“picture?pageNum”接口后点击。然后点击标头;找到“Authorization”字段,复制右侧的token。
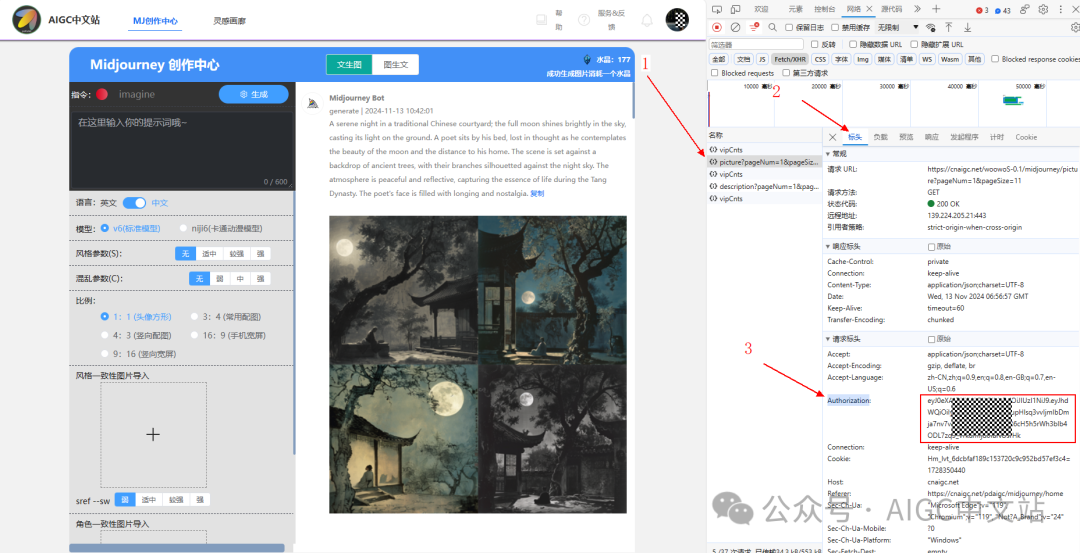
到这里,我们已经获取了token。
生成API
POST https://cnaigc.net/woowoS-0.1/midjourney/imagine##request##请注意保持语言的正确性。{"lang": "en","params": " --ar 4:3 --v 6.0 ","picurl": "","prompt": prompt}##response{"code": 200,"msg": "操作成功","data": {"code": 200,"waitLen": 0,"msg": "success","type": "generate","picUrl": null,"businessId": "6020333778","opertion": null,"params": " --ar 1:1 --v 6.0 ","prompt": "A lonely bed illuminated by the bright moonlight, casting a chill like frost on the ground.","prompt_en": "A lonely bed illuminated by the bright moonlight, casting a chill like frost on the ground.","lang": "en"}}
生成结果查询API
GET https://cnaigc.net/woowoS-0.1/midjourney/mjPicture?businessId=123123123##requestbusinessId是我们的任务id,由imagine返回##response{"code": 200,"msg": "操作成功","data": {"id": null,"businessid": "6020333778","prompt": "A lonely bed illuminated by the bright moonlight, casting a chill like frost on the ground.","prompt_en": "A lonely bed illuminated by the bright moonlight, casting a chill like frost on the ground.","params": " --ar 1:1 --v 6.0 ","uploadpicurl": null,"msgid": "1306153890064105482","hashmsg": "9c8ae8e1-be68-483d-88b9-e5d5a301187c","smallpicurl": "https://www.pdaigc.com/midjourneyOSS/previwImage/zdlzyy2024_A_lonely_bed_illuminated_by_the_bright_moonlight_cas_9c8ae8e1-be68-483d-88b9-e5d5a301187c.png","smallfilename": "zdlzyy2024_A_lonely_bed_illuminated_by_the_bright_moonlight_cas_9c8ae8e1-be68-483d-88b9-e5d5a301187c.png","picurl": "https://www.pdaigc.com/midjourneyOSS/image/zdlzyy2024_A_lonely_bed_illuminated_by_the_bright_moonlight_cas_9c8ae8e1-be68-483d-88b9-e5d5a301187c.png","filename": "zdlzyy2024_A_lonely_bed_illuminated_by_the_bright_moonlight_cas_9c8ae8e1-be68-483d-88b9-e5d5a301187c.png","filesize": 7181874.0,"width": 2048,"height": 2048,"createby": "21","createdate": "2024-11-13 15:08:44","type": "generate","tasktype": null,"updatedate": "2024-11-13 15:09:23","state": null,"lang": "en"}}
生成是一个异步过程:首先通过生成 imagine 接口提交生成请求,返回 200 表示请求任务正确,将会执行。我们接下来需要 mjPicture轮询,midjourney生成是一个较慢的过程,因此,请保持至低10秒以上的间隔周期。
生成成功的判断标志,就是picurl字段不为空。同时,有一个smallpicurl字段是压缩后的图片链接。这里生成的图片都是midjourney风格,四张为一组。

你可以在picurl(不是smallpicurl)字段后加上-1/-2/-3/-4查看切割后的单图,如下图所示,我在png前加上了-3,即可查看第3图。
pdaigc.com/midjourneyOSS/image/zdlzyy2024_A_tranquil_night_a_bed_under_the_pale_moonlight_the__1c0b3065-4858-4b3c-8b5f-4f1f5a53e258-3.png

如果你对midjourney的参数还不够了解,可以通过这里学习:
第一篇:正确使用MJ,并生成一张图
第二篇:/imagine命令使用,及提示词结构初探
第三篇:MJ的其它命令
同时,https://cnaigc.net还支持vary,zoom,scale等操作,你都可以通过f12查看对应的接口。
-
下载代码
如果你还不太会PdServer,建议你看一下这一篇:
PdServer[一]:快速开始
你可以从项目地址中下载项目:
https://github.com/deanChang2021/PdServer_llm.git
在pyCharm中,可以在启动时,选择从版本库下载代码。
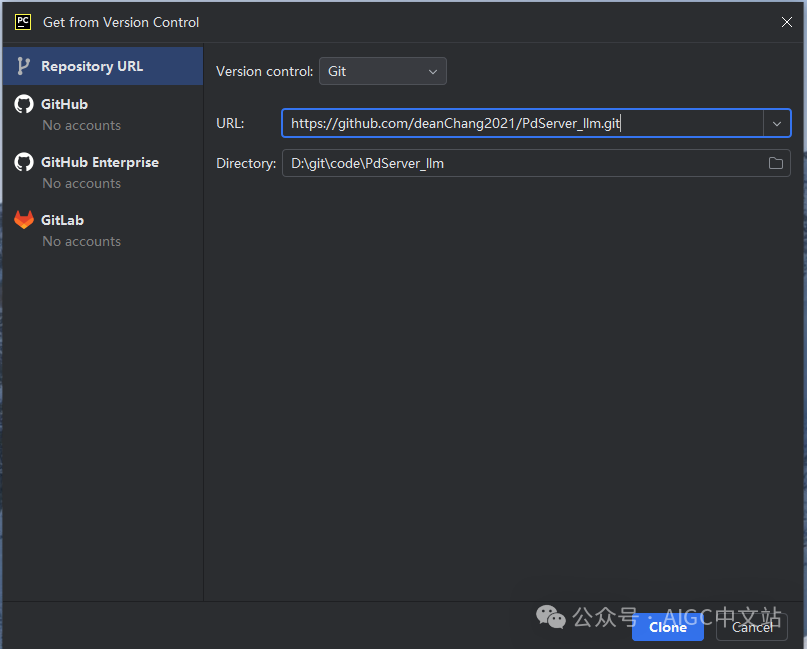
然后确认安装3.10的环境。
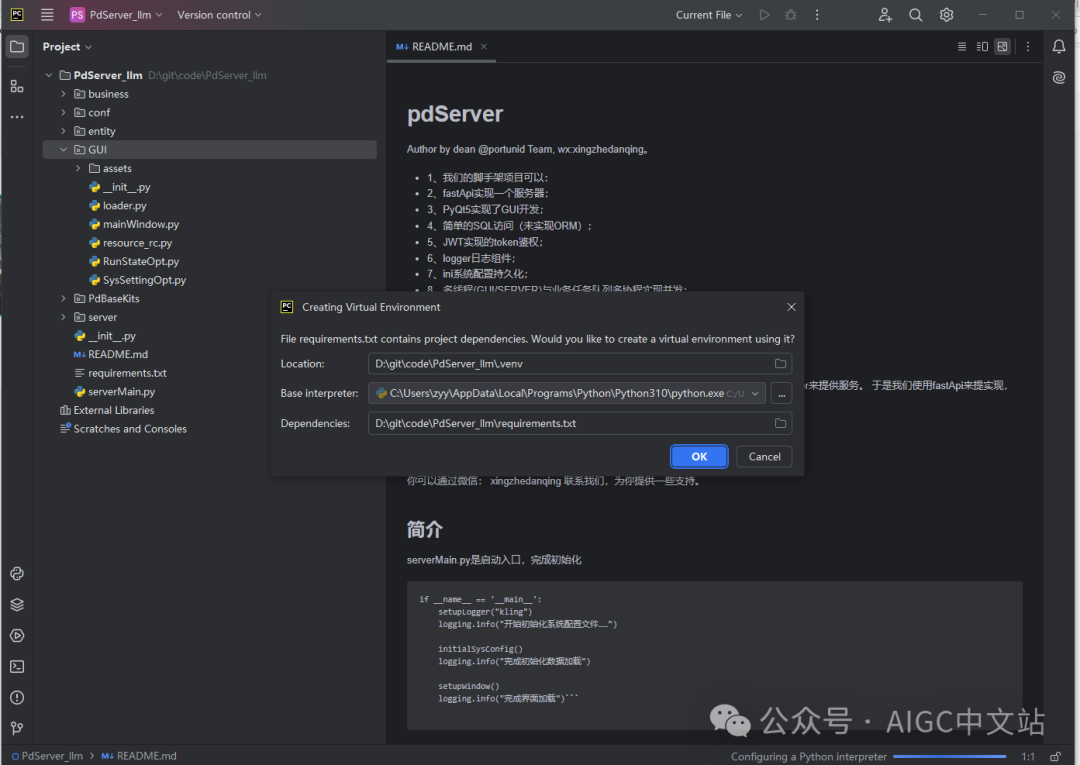
下载后,pip install -r requirements.txt 完成依赖的安装。
将serverMain.py配置为运行项,run,即可打开界面。
业务流程介绍:
1)上传一张图片,这可以是你在小朋友语文课文中拍的《静夜思》;
2)通过uploader接口上传图片;
3)OCR识别图片中的古诗;
4)通过QWEN2.5解读古诗,并编写用于midjourney生成图片的Prompt;
5)调用MidjourneyAPI将Prompt生成图片。
A. 在document_app.py接口层中,实现了uploader。我们在apifox中选择了一张图片进行上传。
返回了200表示上传成功,并返回了一个随机名,这个名字我们后面会使用。
{"code": 200,"filename": "9221773084.PNG"}
B. 在document_app.py接口层中,实现了ocrPoem。我们在apifox中使用刚才返回的图片名。
运行后将生成prompt与图片,我将prompt与midjourney生成的图片保存到了d:/test目录下。
在documentService.py中,是实现代码,从中我们看到首先进行了ocr识别。然后通过chatPoem方法进行解析,得到了prompt。最后,通过requestMidjourneyImg()方法,请求cnaigc.net生成图片。在接下来的内容中,我们会对chatPoem与requestMidjourneyImg进行详细解读。
def parsePoemTask(self, fileName) -> tuple[str, PoemInfo]:filePath = getSaveUploadFilePath() + fileNamelogging.info("filePath:" + filePath)"""ocr对图片进行识别"""poem:str = OCR().ocr(filePath, "chi_sim")"""QWEN对古诗解析并生成prompt"""ret = LLM().chatPoem(poem)redisUtil.incrKey(RedisCntType.POEM_PARSE_TOTALS)promptList:[] = ret.promptfor prompt in promptList:"""midjourney基于prompt生成图片"""with open('d:/test/prompt.txt', mode='a', encoding='utf-8') as f:f.write(prompt)f.write("\n")self.requestMidjourneyImg(prompt)logging.info("--- end chat ----")return poem, ret
-
Prompt优化
我们将使用chatPoem方法调用QWEN2.5,方法实现如下,较为简单,在这里我们使用Pydantic将LLM的输出转换成了我们需要的格式PoemInfo。重点是我们给QWEN2.5的prompt编写。
def chatPoem(self, poem : str) -> Union[PoemInfo, None]:outputParser = PydanticOutputParser(pydantic_object=PoemInfo)prompt = ChatPromptTemplate.from_messages([("system", "{parser_instructions} 你输出的结果请使用中文。"),("human","你好,请你作为一个语文老师。我将会给你一篇文章,文章会被三个#符号包围,请你认真阅读理解文章,并完成如下三个任务:任务1:提取作者、作者年代、创作时间。任务2:文章的详细解读,解读至少需要有200字。任务3:请你根据文章的大意,将诗词分为至少8个画面镜头,并为每个画面镜头编写英文prompt,每一个prompt需要包含画面背景描述、画面时代描述、画面的风格描述、画面主体描述,画面的风格需要符合文章的时代背景与风格,每一个prompt用英语描述,我需要使用这些prompt用于midjourney生成图片,每一个prompt不能少于50个汉字。\n###{book_introduction}###")])book_introduction = poem #" 静夜思 床前明月光,疑是地上霜,举头望明月,低头思故乡。"model = Ollama(model=CHAT_MODEL)chain = prompt | model | outputParserret : PoemInfo = chain.invoke({"book_introduction": book_introduction,"parser_instructions": outputParser.get_format_instructions()})if ret:return retelse:return Noneclass PoemInfo(BaseModel):bookName: str = Field(description="作者")authorName: str = Field(description="作者年代")publishDate: str = Field(description="创作时间")parse: str = Field(description="解读")prompt: List[str] = Field(description="画面描述")
我的提示词如下:
”你好,请你作为一个语文老师。我将会给你一篇文章,文章会被三个#符号包围,请你认真阅读理解文章,并完成如下三个任务:
任务1:提取作者、作者年代、创作时间。
任务2:文章的详细解读,解读至少需要有200字。
任务3:请你根据文章的大意,将诗词分为至少8个画面镜头,并为每个画面镜头编写英文prompt,每一个prompt需要包含画面背景描述、画面时代描述、画面的风格描述、画面主体描述,画面的风格需要符合文章的时代背景与风格,每一个prompt用英语描述,我需要使用这些prompt用于midjourney生成图片,每一个prompt不能少于50个汉字。
\n###{book_introduction}###"
你也可以根据自己的理解,来编写更有效的提示词。
-
请求Midjourney
在前文已经提示生成图片是一个异步过程,因此,在我们的实现中,通过while来轮询,直到picurl字段有返回值。
def requestMidjourneyImg(self, prompt):param ={"lang": "en","params": " --ar 4:3 --v 6.0 ","picurl": "","prompt": prompt}res = POST(param, MIDJOURNEY_IMG_URL, MIDJOURNEY_IMG_TOKEN)if(type(res) != type({})):logging.info("not a dict")jsonRes = json.loads(res)logging.info(jsonRes["data"]["businessId"])logging.info("收到请求的businessId["+jsonRes["data"]["businessId"]+"]")while(True):params = {"businessId":jsonRes["data"]["businessId"]}res = GET(GET_MIDJOURNEY_IMG_URL, params, MIDJOURNEY_IMG_TOKEN)if (type(res) != type({})):logging.info("not a dict")jsonPicRes = json.loads(res)logging.info(jsonPicRes)logging.info(jsonPicRes["data"]["picurl"])if jsonPicRes["data"]["picurl"]:logging.info("ok:"+ jsonPicRes["data"]["picurl"])writeImg2Local(jsonPicRes["data"]["picurl"], "d:/test",jsonPicRes["data"]["picurl"].split("/")[-1])breakelse:logging.info("sleep")time.sleep(6)logging.info("收到图片:"+jsonPicRes["data"]["picurl"])
MIDJOURNEY_IMG_URL 是我们的请求URL,我已经配置到了config.ini中。MIDJOURNEY_IMG_TOKEN是我们的请求token,需要按前述的步骤获取,并写入到config.ini中。POST/GET方法是我改写后的方法,已经将我们的token整合了进去。
writeImg2Local()方法会将我们的图片url 写入到本地,在这里我写入到了d:/test目录中。
OK,到这里,我们已经完成了编辑工作,让我们来运行吧。
-
运行
ocrPoem接口运行非常慢需要近10分钟,因为我们的图片生成过程很慢,我们需要不断的轮询。最后生成了了如下的prompt与图片。
看了一下,生成的图片还不错,如果我们将比例调整为 --ar 4:3,再将风格化调整为 --s 750效果会更好。



-
总结
我在这里只是一个演示代码,此过程是同步的,在实际的生产环境中不可能这样做,需要将接口设计为异步。
同时,使用QWEN生成Midjourney的prompt也可以再优化提升,并生成更多的画面,可以让效果更好。
好的,今天的内容就到这里,感谢大家。
项目地址:
https://github.com/deanChang2021/PdServer_llm.git