Excel365和WPS中提取字符串的五种方法
一、问题的提出
如何在WPS或者Excel365中提取A列指定的字符串,从"面"开始一直到".pdf"?
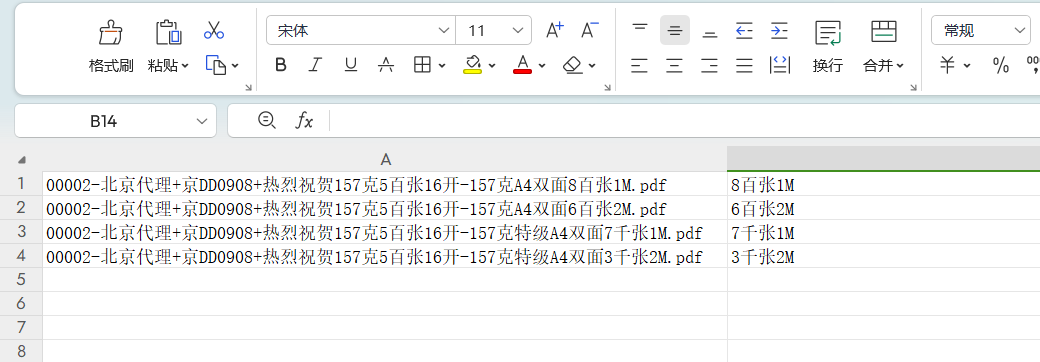
问题的提出
二、问题的分析
我们可以采用多种方法解决这个问题,由于A列到B列的提取是非常有规律的,因此我们可以采用如下几种方法。
1. ctrl+E最简单的方法
把B1中先填写上“8百张1M”,然后选中B1:B4,按下ctrl+E可以智能填充。
2. WPS中智能分列
选中要处理的数据,在顶部菜单选择【数据】——【分列】——【智能分列】,点击【手动设置分列】,然后输入分隔符号,这里输入【双面,.pdf】并用逗号隔开。
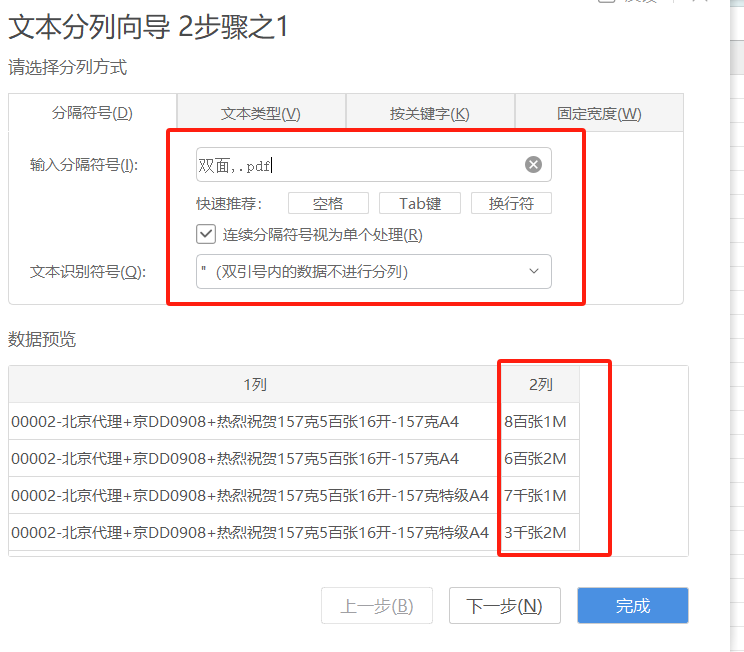
智能分列
接着再选择一下结果显示的位置,点完成即可。
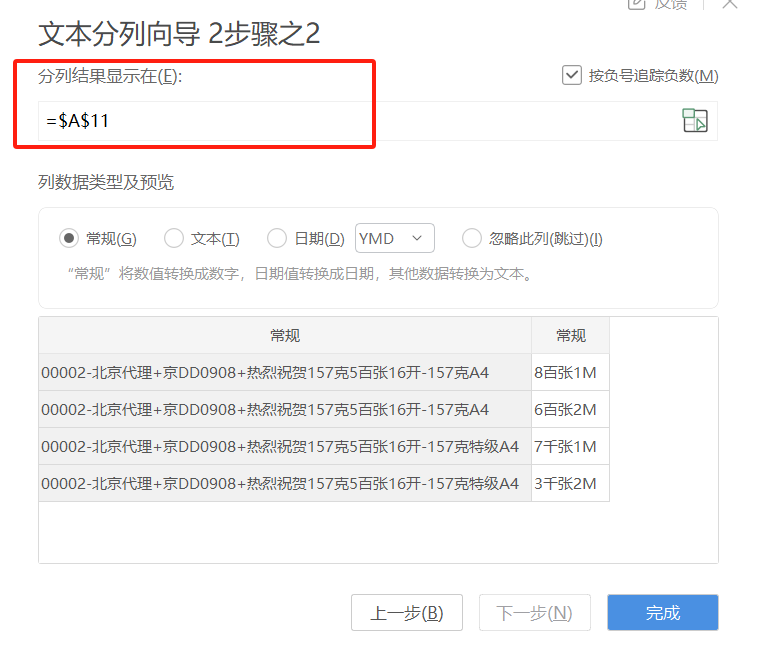
设置显示的位置
3. 正则函数提取字符
也可以使用regexp正则提取想要的字符串。在B1中输入下面的正则表达式,其中\K 会重置匹配的开始位置,确保之前的匹配内容不会被包括在最终的匹配结果中。【?=pattern】表示的是正向先行断言,表示匹配位置后面必须紧跟着满足 pattern 的字符串,但不包括这个字符串在匹配结果中。\.表示的是转义.,相当于把替代任意字符的点转义为标点符号。
=REGEXP(A1,"面\K.+(?=\.pdf)")与上面的公式类似的还有下面的公式,在这个公式里,没有用\K,而是用了(?<=pattern):即正向后行断言,表示匹配位置前面必须是满足 pattern 的字符串,但不包括这个字符串在匹配结果中。
=REGEXP(A4,"(?<=面)(.+)(?=\.pdf)")另外一种方法则是:
=REGEXP(A1,"面\K\S+(?=\.)")4. 正则函数替换字符
除了我们可以把要提取的内容分组捕获外,我们还可以使用regexp的替换功能,使用下面的正则。这里(.+)代表任意一个或多个字符。数字2表示执行替换功能,\1是替换的内容为捕获的第一个分组,即前面(.+)的内容。
=REGEXP(A1,".+面(.+).pdf",2,"\1")5. 使用textbefore和textafter
故名思义,这两个函数是截取指定关键词前或后的内容。
于是我们就有了下面的公式,先把【.pdf】去掉,然后再去【双面】后面的内容。
=TEXTAFTER(TEXTBEFORE(A11,".pdf"),"双面")三、学后总结
1. 自从wps有了正则函数后,很多字符串的提取太方便了。这里的正则函数支持分组、捕获分组、断行、替换等功能,十分强大,大家可以多试试。
2. 有人说正则表达式不容易记住,但是如果克服畏惧心理,经常使用和操练,记住一些常用的字符意义应该不是难事。