Oracle手工创建数据库和多环境变量下如何连接指定的数据库
Oracle手工创建数据库(hefeidb)
Oracle创建数据库的方法有三种:dbca、静默方式、手工建库三种方法,这里演示手工建库的方式,适用在不能运行dbca的环境下面创建库:
1设置环境变量(新增一个)
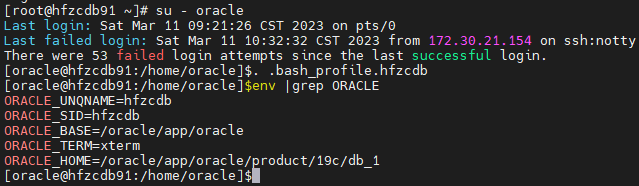
su - oracle
cd /home/oracle
cp .bash_profile .bash_profile.fgzcdb
vi .bash_profile
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
PATH=$PATH:$HOME/bin
export PATH
export ORACLE_BASE=/oracle/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/19c/db_1
export PATH=$ORACLE_HOME/bin:$PATH
export ORACLE_UNQNAME=hefeidb
export ORACLE_SID=hefeidb
source .bash_profile
env |grep ORACLE
创建pfile文件audit_file_dest审计目录
cd $ORACLE_HOME/dbs
复制模板文件 init.ora
vi inithefeidb.ora
db_name='hefeidb'
sga_max_size=2G
processes = 2000
audit_file_dest='/oracle/app/oracle/admin/hefeidb/adump'
audit_trail ='db'
db_block_size=8192
db_domain=''
db_recovery_file_dest='/oracle/app/oracle/fast_recovery_area'
db_recovery_file_dest_size=2G
diagnostic_dest='/oracle/app/oracle'
dispatchers='(PROTOCOL=TCP) (SERVICE=FGEDUDBXDB)'
open_cursors=2000
remote_login_passwordfile='EXCLUSIVE'
undo_tablespace='UNDOTBS1'
# You may want to ensure that control files are created on separate physical
# devices
control_files = (/oradata/hefeidb/control01.ctl, /oradata/hefeidb/control02.ctl)
compatible ='11.2.0'
根据上面的pfile创建目录
mkdir -p /oracle/app/oracle/admin/hefeidb/adump
mkdir -p /oradata/hefeidb
mkdir -p /oracle/app/oracle/fast_recovery_area
orapwd创建密码文件
cd $ORACLE_HOME/dbs
orapwd file=orapwhefeidb password=hefei-2024
创建pfile并启动到nomount
cd $ORACLE_HOME/dbs
sqlplus "/as sysdba"
create spfile from pfile;
startup nomount;
#报错:ORA-27125:unable to create shared memory segment
##解决:vi /etc/sysctl.conf,增加shmmax和shmall两个参数的大小,使用sysctl -p 生效。
执行建库脚本
#vi createdb.sql
CREATE DATABASE hefeidb
USER SYS IDENTIFIED BY oracle
USER SYSTEM IDENTIFIED BY oracle
LOGFILE GROUP 1 ('/oradata/hefeidb/redo01a.log') SIZE 50M BLOCKSIZE 512,
GROUP 2 ('/oradata/hefeidb/redo02a.log') SIZE 50M BLOCKSIZE 512,
GROUP 3 ('/oradata/hefeidb/redo03a.log') SIZE 50M BLOCKSIZE 512
MAXLOGHISTORY 1
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 8192
CHARACTER SET ZHS16GBK
NATIONAL CHARACTER SET AL16UTF16
EXTENT MANAGEMENT LOCAL
DATAFILE '/oradata/hefeidb/system01.dbf'
SIZE 700M REUSE AUTOEXTEND ON NEXT 10240K MAXSIZE UNLIMITED
SYSAUX DATAFILE '/oradata/hefeidb/sysaux01.dbf'
SIZE 550M REUSE AUTOEXTEND ON NEXT 10240K MAXSIZE UNLIMITED
DEFAULT TABLESPACE users
DATAFILE '/oradata/hefeidb/users01.dbf'
SIZE 100M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED
DEFAULT TEMPORARY TABLESPACE temp
TEMPFILE '/oradata/hefeidb/temp01.dbf'
SIZE 20M REUSE AUTOEXTEND ON NEXT 640K MAXSIZE UNLIMITED
UNDO TABLESPACE undotbs1
DATAFILE '/oradata/hefeidb/undotbs01.dbf'
SIZE 200M REUSE AUTOEXTEND ON NEXT 5120K MAXSIZE UNLIMITED;
@createdb.sql
#执行CREATE DATABASE语句时,Oracle数据库至少执行以下操作:
#为数据库创建数据文件为数据库创建控制文件
#为数据库创建在线重做日志并建立ARCHIVELOG模式
#创建SYSTEM表空间创建SYSAUX表空间
#创建数据字典I设置在数据库中存储数据的字符集
#设置数据库时区
#默认时区文件是ORACLE_HOME/oracore/zoneinfo/timezlrg_11.dat SELECT * FROM V$TIMEZONE_NAMES;
#挂载并打开数据库以供使用
生成数据字典信息的脚本并执行
vi run.sql
@?/rdbms/admin/catalog.sql
@?/rdbms/admin/catproc.sql
@?/rdbms/admin/utlrp.sql
@?/sqlplus/admin/pupbld.sql
@run.sql
#下表包含这些脚本的说明:
#catalog.sql创建数据字典表的视图、励态性能视图和许多视图的公共同义词。授予PUBLIC对同义词的访问权限。
#catproc.sql运行PL/SQL 所需或与PL/SQL一起使用的所有脚本。
#utlrp.sql重新编译所有处于无效状态的PL/SQL模块,包括包、过程和类型。
#pupbld.sql SQL*Plus 需要,启用SQL*Plus以禁用用户命令。
#也可以用catctl.pl使用脚本运行catpcat.sql代替catalog.sql与catproc.sql
#catpcat.sql构建数据字典。
#该脚本使用catctl.pl程序运行(而不是使用SQL*Plus)并在内部运行脚本catalog.sql和catproc.sql并行进程,从而提高建数据字典的性能。
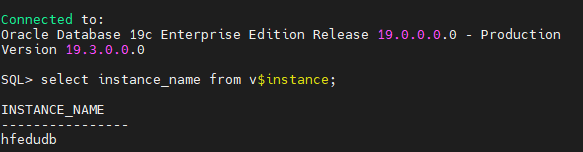
怎么连接到另外一个数据库
方式一:使用exoprt定义一个
[oracle@hfzcdb91:/oracle/app/oracle/product/19c/db_1/dbs]$**export ORACLE_SID=hfzcdb**
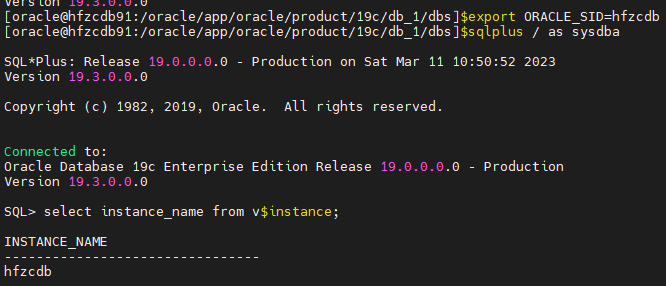
方式二:修改环境变量
[oracle@hfzcdb91:/home/oracle]$vi .bash_profile
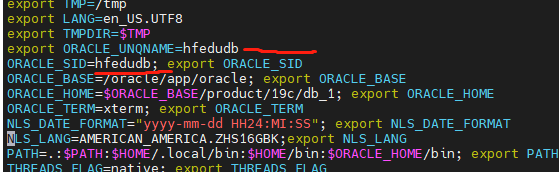
方式三:多个配置环境变量
[oracle@hfzcdb91:/home/oracle]$**. .bash_profile.hfzcdb**