【 LLM论文日更|检索增强:大型语言模型是强大的零样本检索器 】
- 论文:https://aclanthology.org/2024.findings-acl.943.pdf
- 代码:GitHub - taoshen58/LameR
- 机构:悉尼科技大学 & 微软 & 阿姆斯特丹大学 & 马里兰大学
- 领域:retrieval & llm
- 发表:ACL2024

研究背景
- 研究问题:这篇文章要解决的问题是如何在零样本场景下利用大型语言模型(LLM)进行大规模检索。具体来说,作者提出了一种简单的方法,称为“大型语言模型作为检索器”(LameR),通过将查询与其潜在答案候选结合,提升零样本检索的性能。
- 研究难点:该问题的研究难点包括:自监督检索器的性能较弱,导致整个流程瓶颈;直接将LLM与自监督检索器结合会产生大量无关或域外的答案,降低查询增强的效果。
- 相关工作:该问题的研究相关工作有:Yu等人提出的生成-读取管道;Dai等人提出的少样本密集检索方法;Dua等人提出的领域适应数据增强方法;Gao等人提出的基于假设文档嵌入(HyDE)的零样本密集检索方法;Jeronymo等人利用微调排序器过滤LLM生成数据的少样本方法;Saad-Falcon等人设计的两阶段LLM管道;Wang等人利用少样本查询-文档示例生成新查询的方法。
研究方法
这篇论文提出了“大型语言模型作为检索器”(LameR)用于解决零样本大规模检索问题。具体来说,
- 非参数词典检索:首先,作者采用BM25方法进行大规模检索。BM25的核心思想是根据查询词和文档之间的词汇频率和逆文档频率对文档进行排序。其相关性评分公式如下:

- 其中,t表示查询词中的词典词,TF(t,d)表示t在文档d中的词频,IDF(t)表示词t的逆文档频率,N是集合中的文档总数,n(t)是包含词t的文档数,len(d)是文档d的长度,avgdl是集合中文档的平均长度。
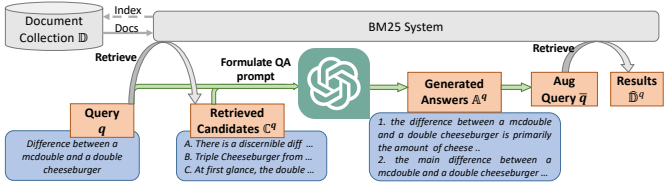
- 候选答案生成:其次,作者提出了一种新的提示模式,称为候选答案生成,用于大规模检索中的查询增强。具体步骤如下:
-
通过检索器获取查询q的前M个候选答案Cq。
-
将这些候选答案与查询q结合,构成提示p(t,q,Cq),然后调用LLM生成答案Aq
-

-
-
- 生成多个答案以防止“词汇不匹配”问题。

- 答案增强的大规模检索:最后,作者使用生成的答案AqAq来增强查询qq,生成新的查询qˉ,并进行大规模检索。具体步骤如下:
-
将每个生成的答案aqaq与原查询qq连接,形成增强查询qˉqˉ。
-
公式如下:
-

实验设计
- 数据集和指标:作者使用了MS-MARCO和TREC深度学习2019/2020测试集(分别记为DL19和DL20)以及BEIR基准中的六个低资源任务数据集。评估指标包括MAP、nDCG@10和Recall@1000(R@1k)。
- 实验设置:默认使用gpt-3.5-turbo作为LLM进行答案生成,候选答案数量M设为10,生成的答案数量N设为5。查询和文档被截断为128个令牌。
- 基线和竞争者:主要基线包括不使用标注查询-文档对的检索方法(即零样本设置),如BM25和Contriever。竞争者包括HyDE和少样本相关判断的Q2DBM25方法。此外,还包括一些全监督检索模型,如DPR和ANCE。
结果与分析
-
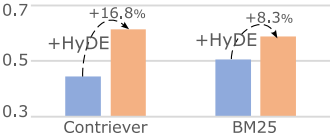
DL19和DL20测试集:在TREC深度学习2019和2020测试集中,LameR在零样本设置下显著优于其强竞争者HyDE。与少样本相关判断方法和全监督检索模型相比,LameR在大多数检索评估指标上也表现最佳。


-
BEIR基准:在BEIR基准的六个低资源任务数据集中,LameR在四个数据集上表现最佳。特别是在TREC-COVID和TREC-NEWS两个TREC检索数据集上,验证了LameR在网络信息检索任务中的优越性。

-
开源LLMs:将开源LLMs(如LLaMA-2-chat-7B和-13B)集成到LameR框架中,LameR在DL19数据集上的表现优于HyDE配置和传统方法,展示了LameR与各种LLM骨干的适应性和效率。
-
更强LLM的探索:进一步验证了更强LLM(如GPT-4)对LameR的提升效果,GPT-4在DL20数据集上的表现显著优于其他竞争者,甚至在全相关判断下也表现最佳。
总体结论
本文提出了一种基于LLM和简单BM25算法的检索方法,无需依赖可学习的检索模型。通过将查询与其潜在答案候选结合,LameR在零样本大规模检索中表现出色,显著优于现有的零样本检索方法。未来的工作将探索使用较小的LLM进行查询增强,以进一步提高效率。
论文评价
优点与创新
- 零样本检索方法:提出了一种简单的方法,将大型语言模型(LLM)应用于零样本场景下的大规模检索,称为“大型语言模型作为检索器”(LameR)。
- 候选答案注入提示:在提示LLM生成答案时,将查询的候选答案注入到提示中,使LLM能够区分和模仿这些候选答案,并通过内部知识总结或重写新的答案。
- 非参数词典检索:利用非参数词典方法(如BM25)作为检索模块,捕捉查询-文档重叠,使检索过程对LLM透明,规避了自监督检索器的性能瓶颈。
- 基准数据集上的优异表现:在多个基准数据集上进行了评估,结果表明LameR在大多数数据集上实现了最佳的检索质量,甚至超过了基于上下文标签演示的LLM检索器和在全量数据集上微调的基线检索器。
- 开源LLM的适应性:展示了将开源LLMs(如LLaMA-2-7B和-13B)集成到LameR框架中的有效性,证明了LameR与各种LLM骨干的适应性和效率。
- 更强大的LLM的优势:进一步验证了使用更强大的LLM(如GPT-4)可以带来更多的改进,显著提高了检索方法的性能。
不足与反思
- 指令敏感性:与其他基于提示的LLM应用一样,LameR对不同LLM的指令也很敏感,这可能需要大量的人工努力来编写提示。
- 计算开销:尽管LameR的两阶段检索过程非常快,依赖于LLM生成答案的计算开销仍然存在。未来的工作将探索专门针对较小LLM进行查询增强,以减少计算开销。
关键问题及回答
问题1:LameR方法如何在零样本场景下利用大型语言模型(LLM)进行大规模检索?
LameR方法通过将查询与其潜在答案候选结合,提升零样本检索的性能。具体步骤如下:
- 非参数词典检索:首先,使用BM25方法进行大规模检索,而不是训练深度神经网络。BM25根据查询和文档之间的词频和逆文档频率对文档进行排序。
- 候选答案生成:在提示LLM时,将查询的候选答案也加入提示中。这些候选答案是通过对查询进行普通检索得到的。然后,构造提示并使用LLM生成答案。
- 答案增强的大规模检索:使用生成的答案增强原始查询,并进行大规模检索。最终使用增强后的查询进行检索。
这种方法避免了直接将LLM与自监督检索器结合产生的问题,提升了检索质量和性能。
问题2:LameR方法在实验中如何验证其有效性?
LameR方法在多个数据集和评价指标上进行了验证,具体包括:
- DL19和DL20测试集:在TREC深度学习2019和2020测试集中,LameR在零样本设置下表现最佳,显著优于其强竞争者HyDE。与少样本相关判断方法和全监督相关判断方法相比,LameR在大多数检索评估指标上也表现最佳。
- BEIR基准:在BEIR基准的六个低资源任务数据集中,LameR在四个数据集上表现最佳。特别地,在两个TREC检索数据集(TREC-COVID和TREC-NEWS)上,LameR表现出色,验证了其在Web信息检索任务中的有效性。
- 开源LLMs:将开源LLMs(如LLaMA-2-chat-7B和-13B)集成到LameR框架中,LameR在DL19数据集上的表现优于HyDE配置和传统的DPR和Contriever-FT方法,展示了LameR与各种LLM骨干的适应性和效率。
- 更强LLM的探索:进一步验证了更强的LLM(如GPT-4)是否会带来更大的改进。在DL20数据集上应用GPT-4后,LameR的性能显著提高,甚至在全相关判断下也击败了所有竞争者。
问题3:LameR方法在实验中有哪些发现和改进空间?
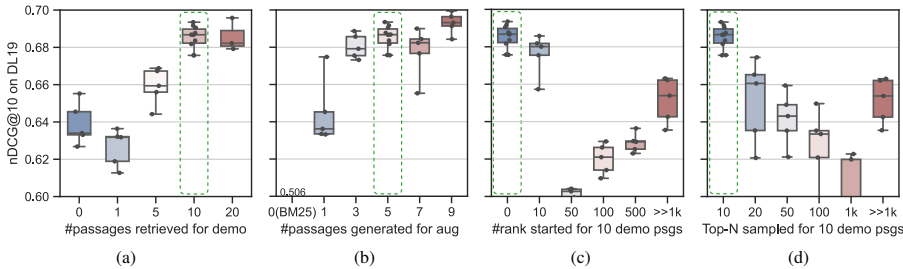
- 候选答案数量的影响:实验发现,增加检索到的候选答案数量(M)会一致提高答案增强大规模检索的性能,但当M超过10时,提升变得边际。因此,选择M=10以平衡性能和效率。
- 生成的答案数量的影响:生成的答案数量(N)越多,检索性能越好,但当N>5时,性能波动并趋于饱和。因此,选择N=5作为默认值。
- 检索方法的比较:LameR在使用BM25进行检索时,表现出高效的检索性能和较低的延迟,优于使用密集检索器(如Contriever)的方法。
- 未来改进方向:未来的工作将探索使用较小的LLM进行查询增强,以进一步提高效率,并解决提示敏感性问题,减少人工编写提示的工作量。