StructuredStreamingKafka中的实时ETL案例及常见问题
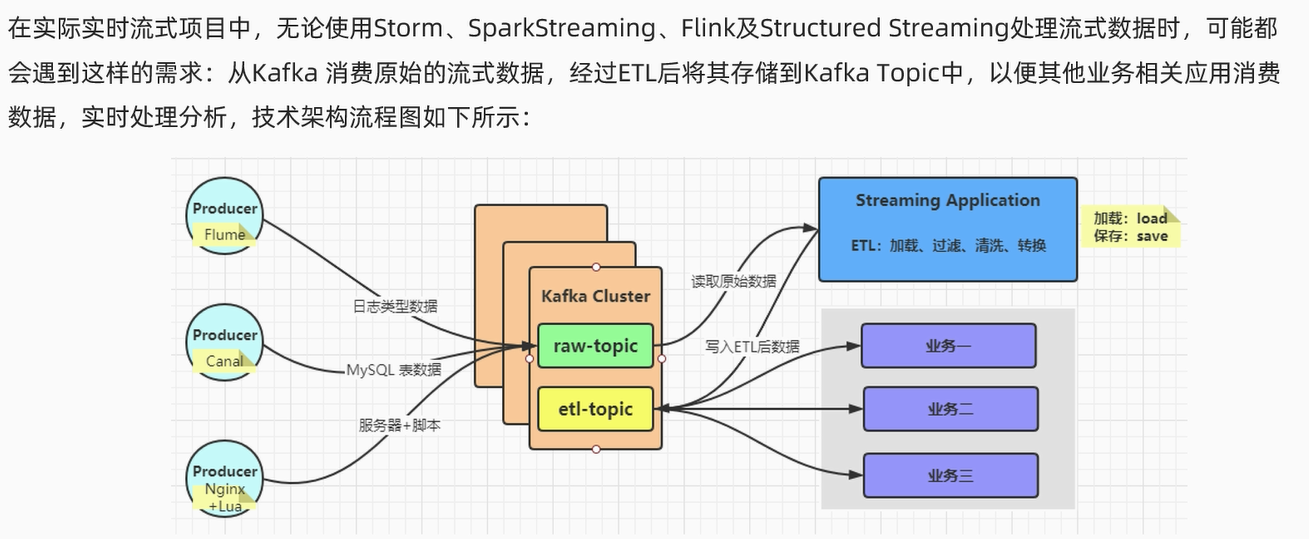
实时ETL
在 java 项目中,导入 jar 包:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.50</version>
</dependency>package com.bigdata.moni;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class StationLog {
private String stationId;
private String callOut;
private String callIn;
private String callStatus;
private long callTime;
private int duration;
}
package com.bigdata.smartedu;
import com.alibaba.fastjson.JSON;
import com.bigdata.moni.StationLog;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.Random;
public class SendStationLogProducer {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
String[] arr = {"fail", "busy", "barring", "success", "success", "success",
"success", "success", "success", "success", "success", "success"};
Random random = new Random();
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
while(true){
String callOut = "1860000"+ String.format("%04d",random.nextInt(10000));
String callIn = "1890000"+ String.format("%04d",random.nextInt(10000));
String callStatus = arr[random.nextInt(arr.length)];
int callDuration = "success".equals(callStatus) ? (1 + random.nextInt(10)) * 1000 : 0;
// 随机产生一条基站日志数据
StationLog stationLog = new StationLog(
"station_" + random.nextInt(10),
callOut,
callIn,
callStatus,
System.currentTimeMillis(),
callDuration
);
// 将一个对象变为json
String jsonString = JSON.toJSONString(stationLog);
System.out.println(jsonString);
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",jsonString);
kafkaProducer.send(producerRecord);
Thread.sleep(2000);
}
//kafkaProducer.close();
}
}也可以 python 发送 kafka 数据(将以上 java 代码替换为 python 代码)
首先安装 kafka 环境:
pip install kafka-python接着编写代码:
from kafka import KafkaProducer
from kafka.errors import KafkaError
import json
import random
import time
class StationLog:
def __init__(self, station_id, call_out, call_in, call_status, timestamp, call_duration):
self.station_id = station_id
self.call_out = call_out
self.call_in = call_in
self.call_status = call_status
self.timestamp = timestamp
self.call_duration = call_duration
def to_string(self):
return json.dumps(self.__dict__)
def main():
# 设置连接kafka集群的ip和端口
producer = KafkaProducer(bootstrap_servers='bigdata01:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
arr = ["fail", "busy", "barring", "success", "success", "success", "success", "success", "success", "success", "success", "success"]
while True:
call_out = "1860000" + str(random.randint(0, 9999)).zfill(4)
call_in = "1890000" + str(random.randint(0, 9999)).zfill(4)
call_status = random.choice(arr)
call_duration = 1000 * (10 + random.randint(0, 9)) if call_status == "success" else 0
# 随机产生一条基站日志数据
station_log = StationLog(
"station_" + str(random.randint(0, 9)),
call_out,
call_in,
call_status,
int(time.time() * 1000), # 当前时间戳
call_duration
)
print(station_log.to_string())
time.sleep(0.1 + random.randint(0, 99) / 100)
try:
# 发送数据到Kafka
producer.send('topicA', station_log.to_string())
except KafkaError as e:
print(f"Failed to send message: {e}")
# 确保所有异步消息都被发送
producer.flush()
if __name__ == "__main__":
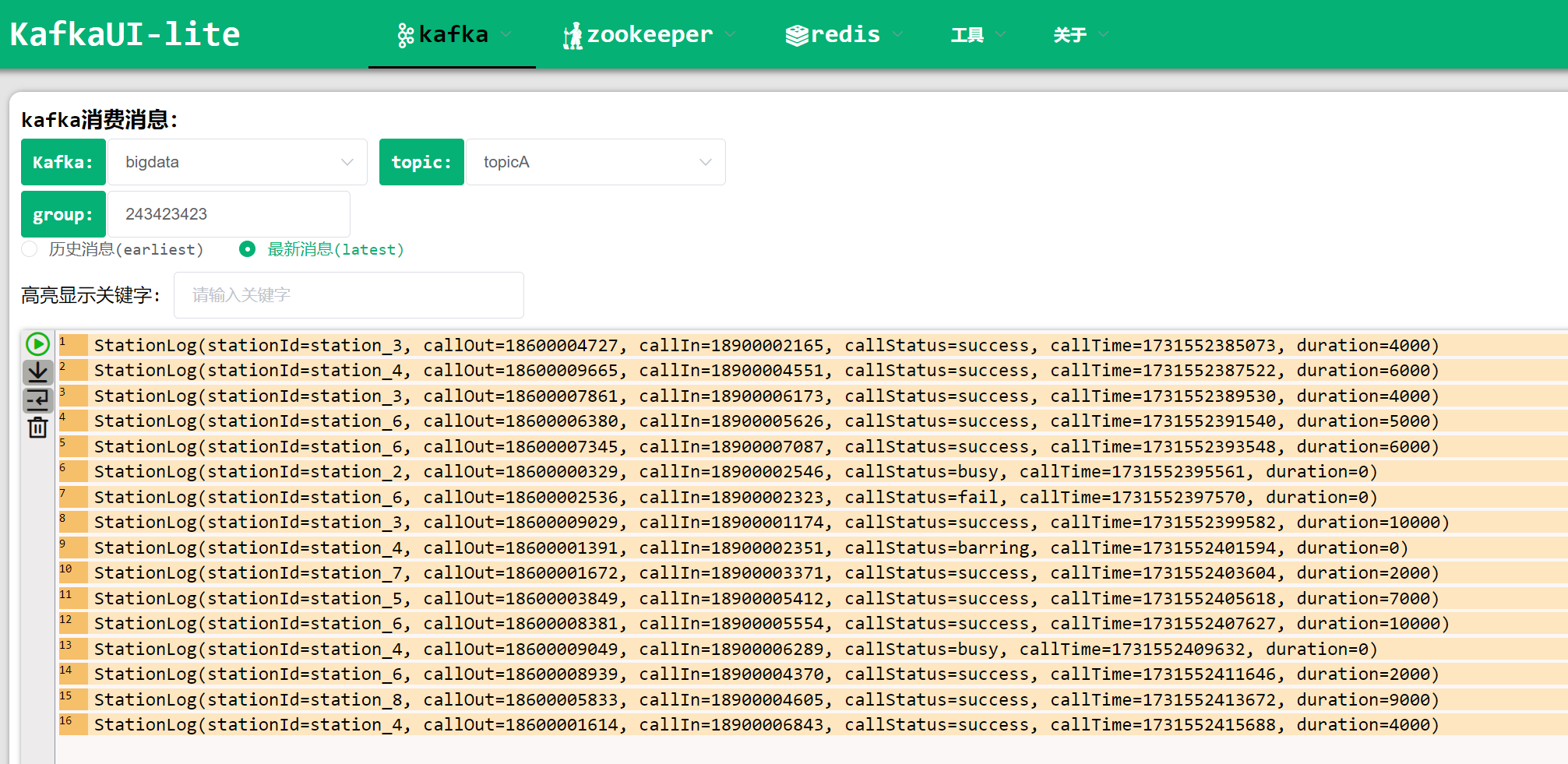
main()可以使用本地的 kafka-ui 的工具进行消费,查看是否可以正常发送和接收消息:
解压kafka-ui安装包,双击打开bin目录下的kafkaUI.bat(注意:一直保持打开的状态,不要关掉)
通过端口http://localhost:8889/#/进入ui界面

接着编写 pyspark 中的 StructStreaming 代码:
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
spark = SparkSession.builder.master("local[2]").appName("streamingkafka").config(
"spark.sql.shuffle.partitions", 2).getOrCreate()
readDf = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "bigdata01:9092") \
.option("subscribe", "topicA") \
.load()
#etlDf = readDf.selectExpr("CAST(value AS STRING)").filter(F.col("value").contains("success"))
readDf.createOrReplaceTempView("temp_donghu")
etlDf = spark.sql("""
select cast(value as string) from temp_donghu where cast(value as string) like '%success%'
""")
etlDf.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "bigdata01:9092") \
.option("topic", "etlTopic") \
.option("checkpointLocation", "./ckp") \
.start().awaitTermination()
spark.stop()
cast 函数可以将一个 byte[] 结构的字符串变为一个普通的字符串。
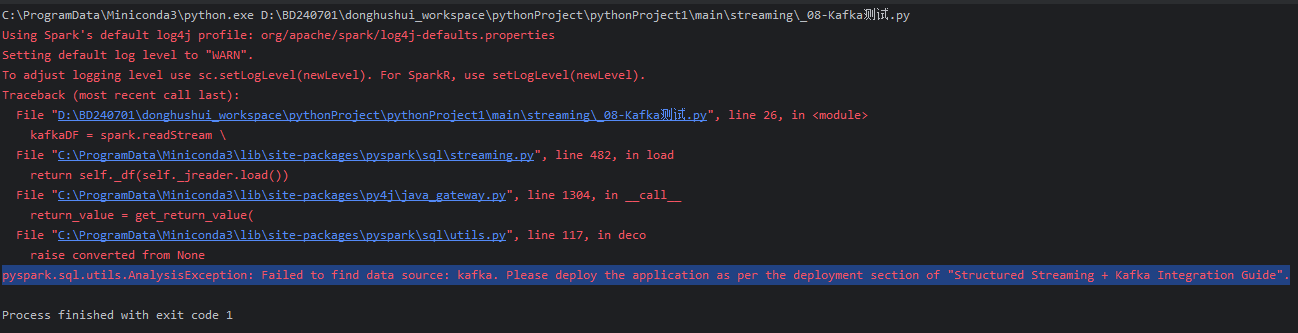
报错 : org.apache.spark.sql.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;
解决:这个是因为缺少了Kafka和Spark的集成包,前往https://mvnrepository.com/artifact/org.apache.spark
下载对应的jar包即可,比如我是SparkSql写入的Kafka,那么我就需要下载Spark-Sql-Kafka.x.x.x.jar


接着运行又报错:
Caused by: java.lang.ClassNotFoundException: org.apache.kafka.common.serialization.ByteArraySerializer
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 21 more原因是缺少 kafka-clients.jar 包:

遇到如下错误:
Caused by: java.lang.ClassNotFoundException: org.apache.spark.kafka010.KafkaConfigUpdater
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 44 more在Spark 3.0.0环境下运行StructuredStreaming程序时遇到版本不兼容错误,需要额外添加commons-pools2和spark-token-provider-kafka jar包
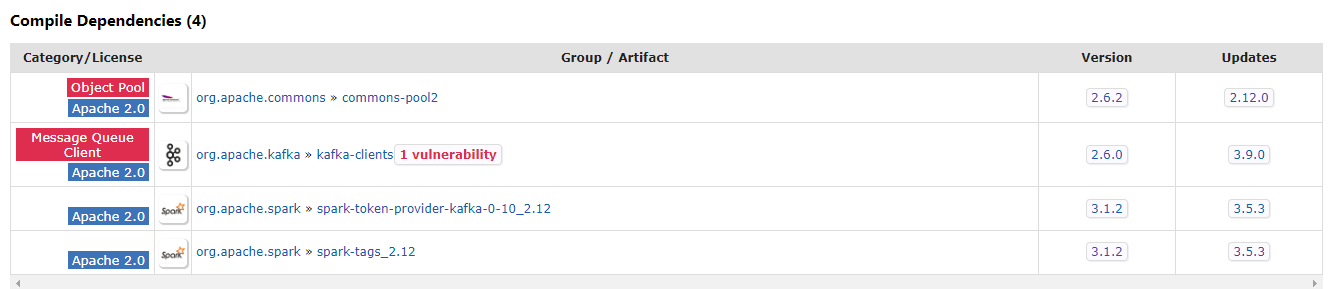
将这些 jar 包都下载下来,放入 pyspark 中的 jars 目录下,代码即可运行
情况解决!!!