NLP论文速读(多伦多大学)|利用人类偏好校准来调整机器翻译的元指标
论文速读|MetaMetrics-MT: Tuning Meta-Metrics for Machine Translation via Human Preference Calibration
论文信息:

简介:
本文的背景是机器翻译(MT)任务的评估。在机器翻译领域,由于不同场景和语言对的需求差异,没有单一的评估指标能够普遍适用。现有的评估指标可能在一个任务中表现良好,但在另一个任务中可能就不适用。因此,依赖单一指标往往是不够的,需要将自动评估指标与人类评估对齐,以确保其有效性。此外,现有的多个评估指标之间可能因为模型和训练数据的差异而相关性不强,这影响了它们与人类评估的一致性和跨语言对的可靠性。因此,本文提出了一种新的方法,旨在通过贝叶斯优化和高斯过程(GP)来调整和优化现有的MT评估指标,使其更贴近人类偏好。
论文方法:
本文提出的方法是METAMETRICS-MT,一个创新的评估指标,它通过贝叶斯优化和高斯过程来优化现有MT评估指标的相关性。
具体步骤如下:
多指标融合:METAMETRICS-MT结合了多个不同的评估指标,每个指标都被赋予特定的权重,以优化整体性能。这些指标包括基于词汇和基于语义的指标,它们被整合在一起,以形成一个综合的评估分数。
贝叶斯优化:使用贝叶斯优化来确定最佳的权重集合,这些权重最大化了评估分数与人类评估分数之间的相关性。贝叶斯优化通过构建目标函数的概率模型,平衡了新区域的探索和已知有前景区域的利用。
高斯过程(GP):GP被用作贝叶斯优化中的代理模型,它假设变量的多变量高斯分布,并随着观测数据的增加而变得更加精确,从而帮助算法更有效地识别权重空间中的有前景区域。
论文实验:
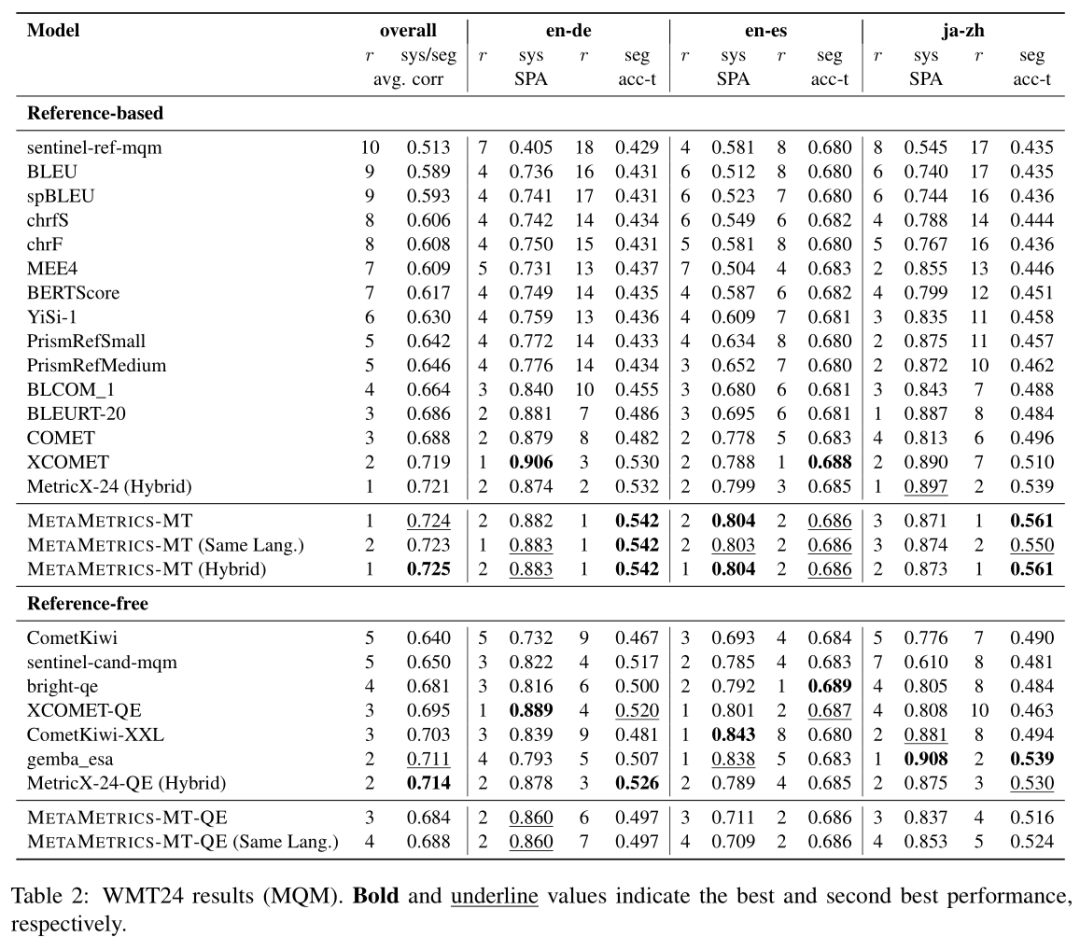
论文中提到了两个版本的METAMETRICS-MT:一个是基于参考的(Reference-based),另一个是无需参考的(Reference-free)。
实验使用了WMT24度量共享任务数据集,并且使用了Kendall’s τ相关性作为评估指标。
在参考基础设置中,使用了包括MetricX-23的不同变体、BERTScore、YISI-1、BLEURT、COMET-22和XCOMET-XL等在内的多个评估指标。
在无参考设置中,使用了包括CometKiwi的不同变体、GEMBA-MQM和MetricX-23-QE等在内的多个评估指标。
Table 2展示了不同评估指标在WMT24共享任务中的表现,包括系统级软成对排名准确率(sys SPA)、段级成对排名准确率(seg acc-t)和系统级、段级平均相关性(avg. corr)。
论文中的METAMETRICS-MT在参考基础设置下的表现超过了所有其他基线,特别是在系统级和段级平均相关性方面,METAMETRICS-MT(Hybrid)变体在所有变体中表现最佳。
论文链接:
https://arxiv.org/abs/2411.00390
原文来自:
NLP论文速读(多伦多大学)|利用人类偏好校准来调整机器翻译的元指标