MyBatis——#{} 和 ${} 的区别和动态 SQL
1. #{} 和 ${} 的区别
为了方便,接下来使用注解方式来演示:
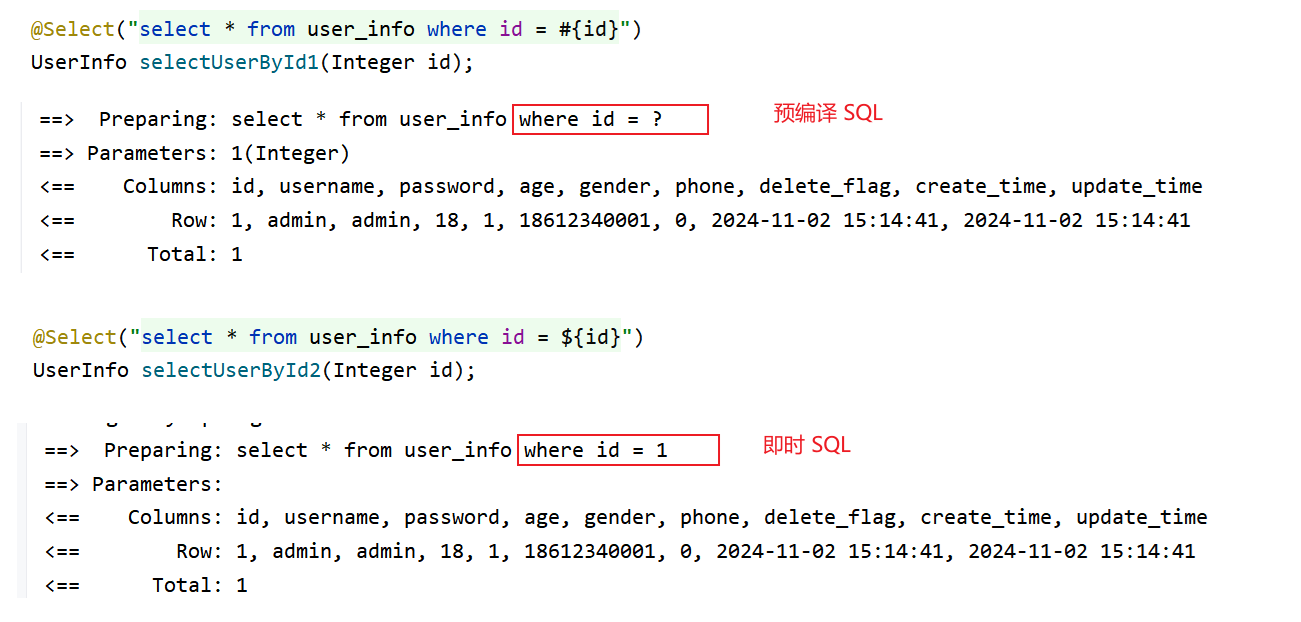
#{} 的 SQL 语句中的参数是用过 ? 来起到类似于占位符的作用,而 ${} 是直接进行参数替换,这种直接替换的即时 SQL 就可能会出现一个问题

当传入一个字符串时,就会发现 SQL 语句出错了:


这里的 zhangsan并不是作为一个字符串使用的,应该是加上引号的
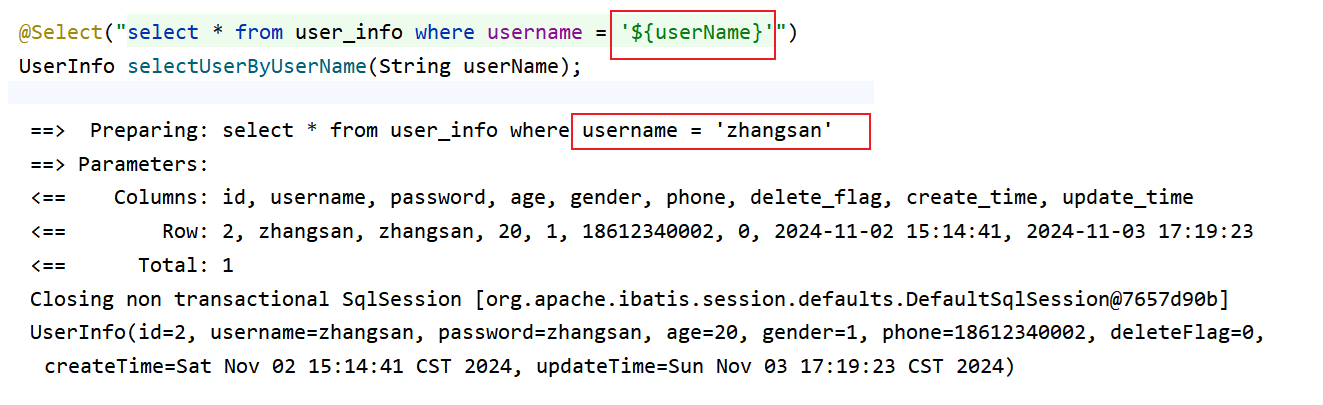
加上之后就可以正常查询了
这就可能会出现 SQL 注入的问题
来看一下 SQL 注入的例子,假如传入的参数是' or 1='1
@Select("select username, `password`, age, gender, phone from user_info where username= '${name}' ")
List<UserInfo> queryByName(String name);按道理说是没有这个用户的,但是却把所有用户的信息都查出来了
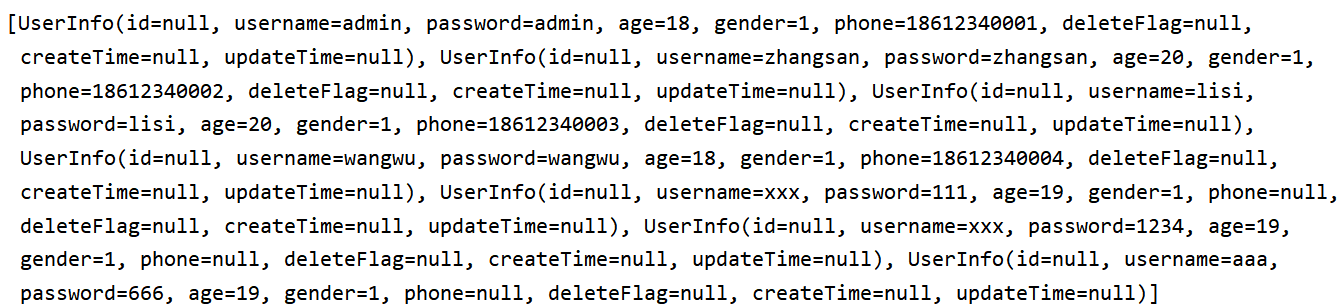
如果在某些登录的界面输入 SQL 注入代码' or 1='1就可能登录成功
使用 #{} 就没有这个问题
除了以上的区别外,二者还有性能方面的区别
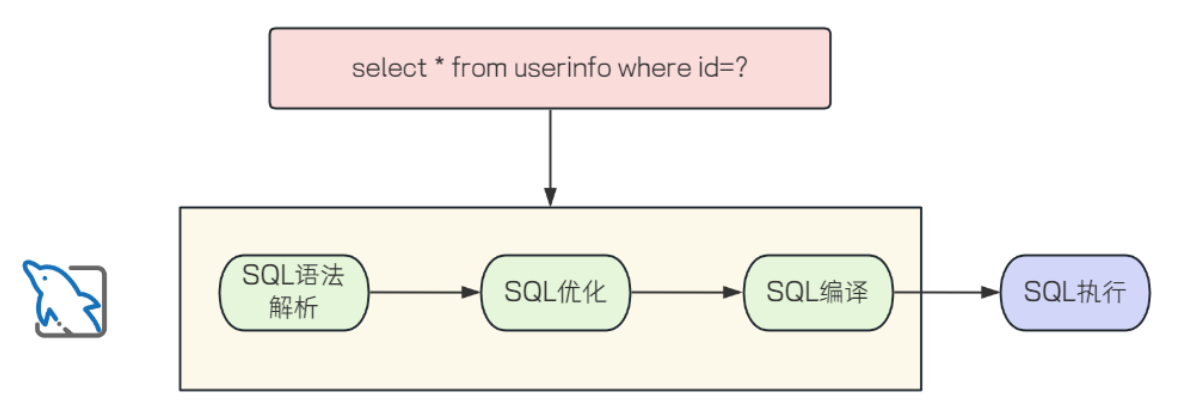
在上面提到过,#{} 是预编译 SQL,${} 是即时 SQL ,预编译SQL编译一次之后会将编译后的 SQL 语句缓存起来,后面再执行这条语句时,不会再次编译,省去了解析优化等过程,以此来提高效率,所以当需要频繁地使用 SQL 语句时,预编译的性能优化就体现出来了,而对于即时 SQL ,如果只是在启动时或者很少变化的场景下使用${}来配置一些数据库对象名称等,它可以避免预编译的过程,执行起来相对直接
2. 排序
在上面看来,#{} 无论是在安全性还是效率上,都占据了优势,那么都是用 #{}可以吗?
来看使用 #{}来实现排序功能:
@Select("select * from user_info order by id #{order}")
List<UserInfo> selectUserByOrder(String order);这里把排序的方式作为参数,给用户选择是升序还是降序排序,测试方法中传入一个字符串表示降序
@Test
void selectUserByOrder() {
userInfoMapper.selectUserByOrder("desc");
}
然后就会发现报错了,可以看到 "desc" 确实是当做字符串传进去了,#{} 的方式会把字符串类型加上单引号,然后 SQL 语句就会变成这样:
select * from user_info order by id 'order'
这样肯定是不对的,那么这个时候就需要用到 ${} 了,直接进行参数替换,但是使用 ${} 肯定就需要考虑 SQL 注入的问题,由于排序方式只有 asc 和 desc 两种方式,可以采用枚举类来进行校验,也可以通过判断条件来实现校验

3. 模糊查询
通过模糊查询来查找名字中含有“zhang”的信息
@Select("select * from user_info where username like '%#{name}%'")
List<UserInfo> selectUserByLike(String name);@Test
void selectUserByLike() {
System.out.println(userInfoMapper.selectUserByLike("zhang"));
}
然后发现又报错了,因为使用的是 #{} ,所以就会替换为 '%'zhang'%',这样是肯定不能运行的,所以还是需要使用 ${} 进行直接替换,但是这时怎么去解决 SQL 注入的问题呢,这样就不能简单的通过枚举或者判断来约束传入的参数了,这时就可以通过使用拼接的方式
通过 CONCAT 函数来对 SQL 语句进行拼接,这样就可以使用 #{},
@Select("select * from user_info where username like CONCAT('%',#{name},'%')")
List<UserInfo> selectUserByLike(String name);4. 数据库连接池
在传统的数据库访问模式中,每当应用程序需要与数据库进行交互时,它会创建一个新的数据库连接,使用完毕后关闭连接,这样频繁地创建和销毁数据库连接会消耗大量的系统资源
数据库连接池的出现就是为了解决这些问题。它在应用程序启动时预先创建一定数量的数据库连接,将这些连接存储在一个 “池” 中。当应用程序需要访问数据库时,从池中获取一个可用的连接,使用完毕后将连接归还给池,而不是直接关闭连接,从而避免了频繁创建和销毁连接所带来的性能开销,这一点和线程池是类似的
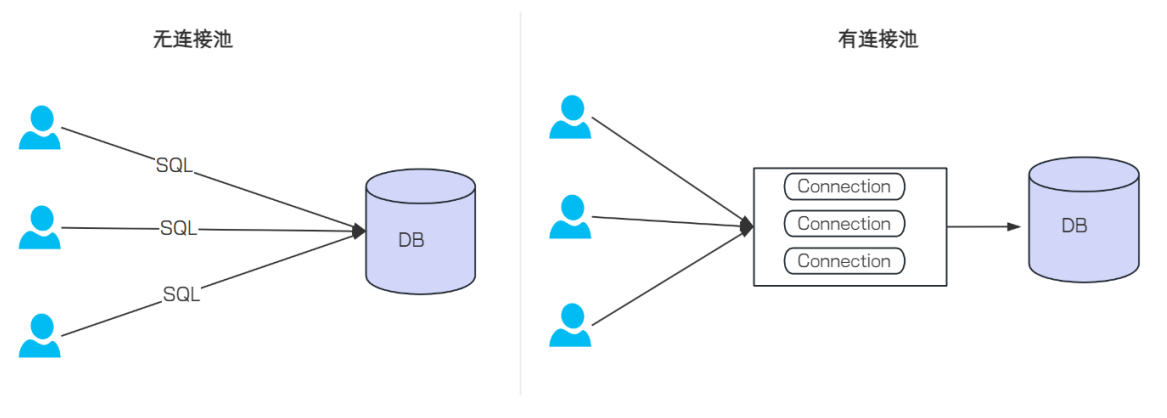
常见的数据库连接池有:C3P0 , DBCP , Druid , Hikari
Spring Boot 默认使用的是 Hikari

如果想更换为 Druid 的话,导入相关的依赖即可
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-3-starter</artifactId>
<version>1.2.21</version>
</dependency>然后再启动程序之后就更换为了 Druid

也可以去 官方文档 进行查看
5. 动态 SQL
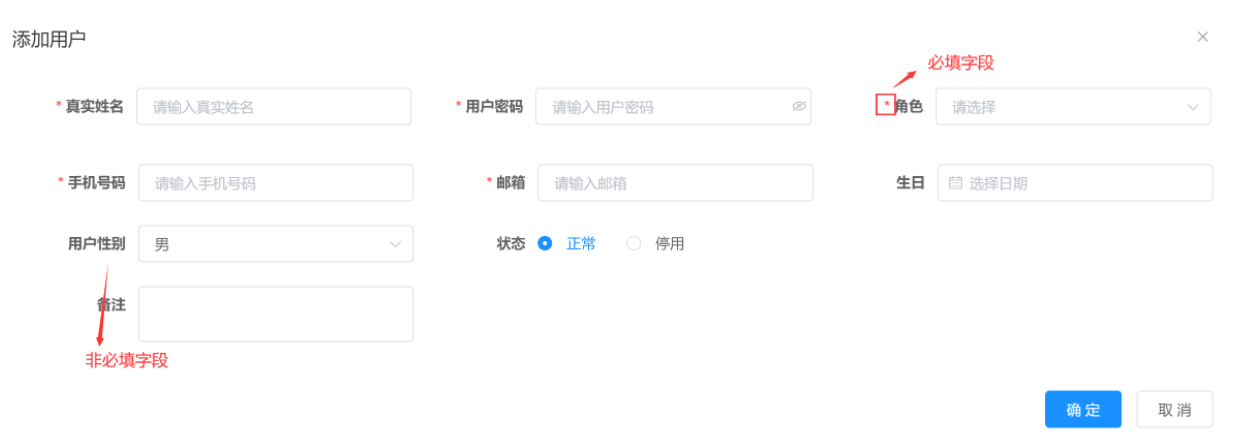
我们在填一些表单的时候应该会见到下面这种,有的是必填项,有的是选填项,对于选填项来说,如果没有填,肯定是需要赋一个默认值的,比如 null,那么就需要动态 SQL 来实现这样的功能
5.1. <if>
可以通过 if 标签来实现一下:
@Mapper
public interface UserInfoXmlMapper {
Integer insertUserByCondition(UserInfo userInfo);
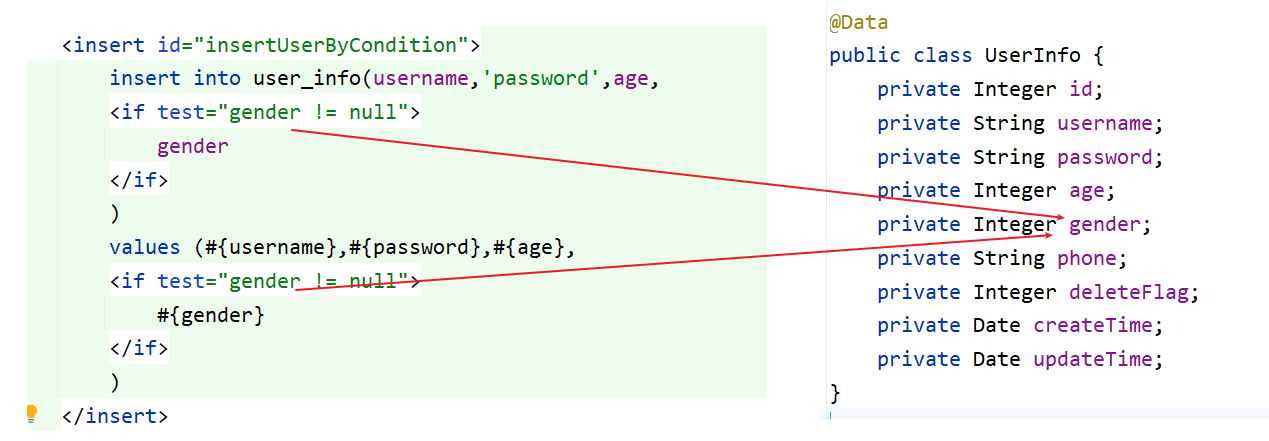
}再来看 XML 中的 SQL 语句
<insert id="insertUserByCondition">
insert into user_info(username,'password',age,
<if test="gender != null">
gender
</if>
)
values (#{username},#{password},#{age},
<if test="gender != null">
#{gender}
</if>
)
</insert>if 标签中的参数和 java 对象中的属性参数是对应的
@Test
void insertUserByCondition() {
UserInfo userInfo = new UserInfo();
userInfo.setUsername("java");
userInfo.setPassword("java");
userInfo.setAge(19);
//userInfo.setGender(1);
Integer integer = userInfoXmlMapper.insertUserByCondition(userInfo);
}如果不传入性别的话来看一下结果:

由于性别没有传入,所以说 SQL 语句中是只有前三个参数的,所以第三个参数那里就多了一个逗号,导致最终的 SQL 的语法错误
那么就可以想一个办法,如果把逗号直接加前面,是不是就可以解决了
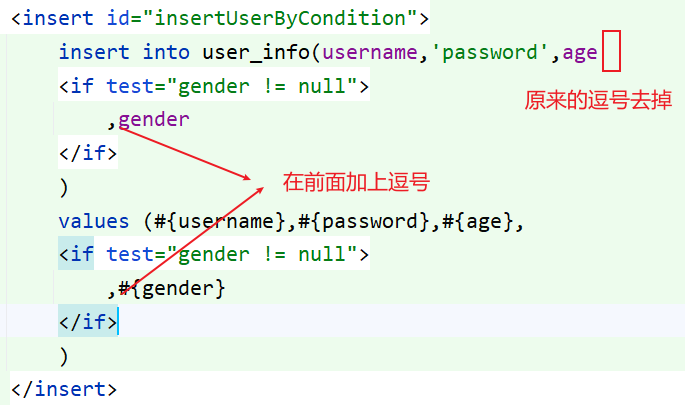
这样看似是可以解决的,但是如果说 username, age 都设为了非必填的,例如 username 没有传入参数,但是 age 传入了参数,这样前面就多了一个逗号,这时 SQL 语句就又会出错了,把逗号都加到右边,也是会出现问题的
这时就需要用到下面的标签了
5.2. <trim>
主要用于去除 SQL 语句中多余的关键字或者字符,同时也可以添加自定义的前缀和后缀
・prefix:用于为包含在trim标签内部的 SQL 语句块添加一个前缀
・suffix:表示整个语句块,以 suffix 的值作为后缀.
・prefixOverrides:为trim标签内的 SQL 语句块添加一个后缀.
・suffixOverrides:表示整个语句块要去除掉的后缀.
<insert id="insertUserByCondition">
insert into user_info
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="username!=null">
username ,
</if>
<if test="password!=null">
`password`,
</if>
<if test="age!=null">
age,
</if>
<if test="gender!=null">
gender
</if>
</trim>
values
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="username!=null">
#{username},
</if>
<if test="password!=null">
#{password},
</if>
<if test="age!=null">
#{age},
</if>
<if test="gender!=null">
#{gender}
</if>
</trim>
</insert>这就表示在 SQL 语句前面加上一个 '(' ,后面加上 ')' ,如果最后是以逗号结尾的就把逗号删了,以此来实现 SQL 语句拼接的效果
5.3. <where>
来看一下条件查询
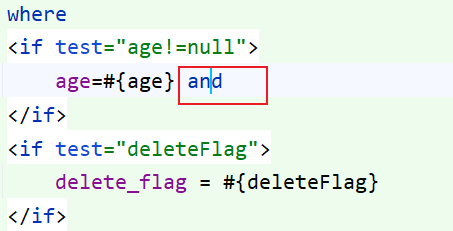
这里的 and 和上面的逗号是一样的性质,放在右边或者左边都不合适,还是可以使用 trim 标签来解决
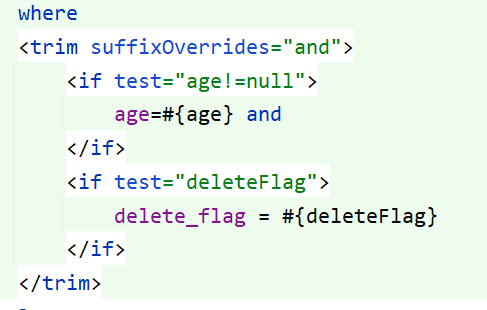
但是这时其实还有一个问题,如果说 age 和 deleteFlag 都没有传入的话,最后的 SQL 语句 where 后面就没有了,这时又会报错了
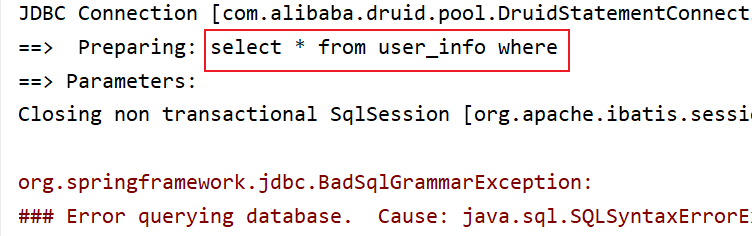
这种情况 trim 就解决不了了,其中一种解决方式是在 where 后面加上 1=1,那么 and 就需要加在前面了:
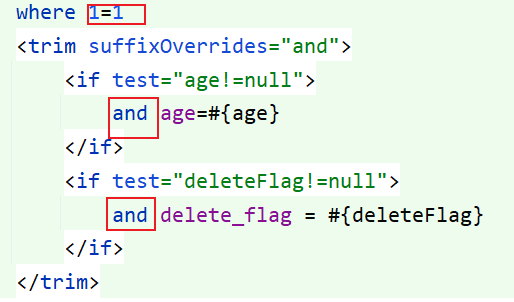
比较推荐的写法就是使用 <where> 标签
<select id="selectUserByCondition" resultType="com.example.mybatisdemo.model.UserInfo">
select * from user_info
<where>
<if test="age!=null">
and age=#{age}
</if>
<if test="deleteFlag!=null">
and delete_flag = #{deleteFlag}
</if>
</where>
</select><where> 标签如果后面都没有值的话,SQL 语句中的 where 也不会添加,并且如果只有一个值的话,前面的 and 也会被去掉,也不用 trim 标签了,不过去掉的是前面的 and,写后面是不会去掉的
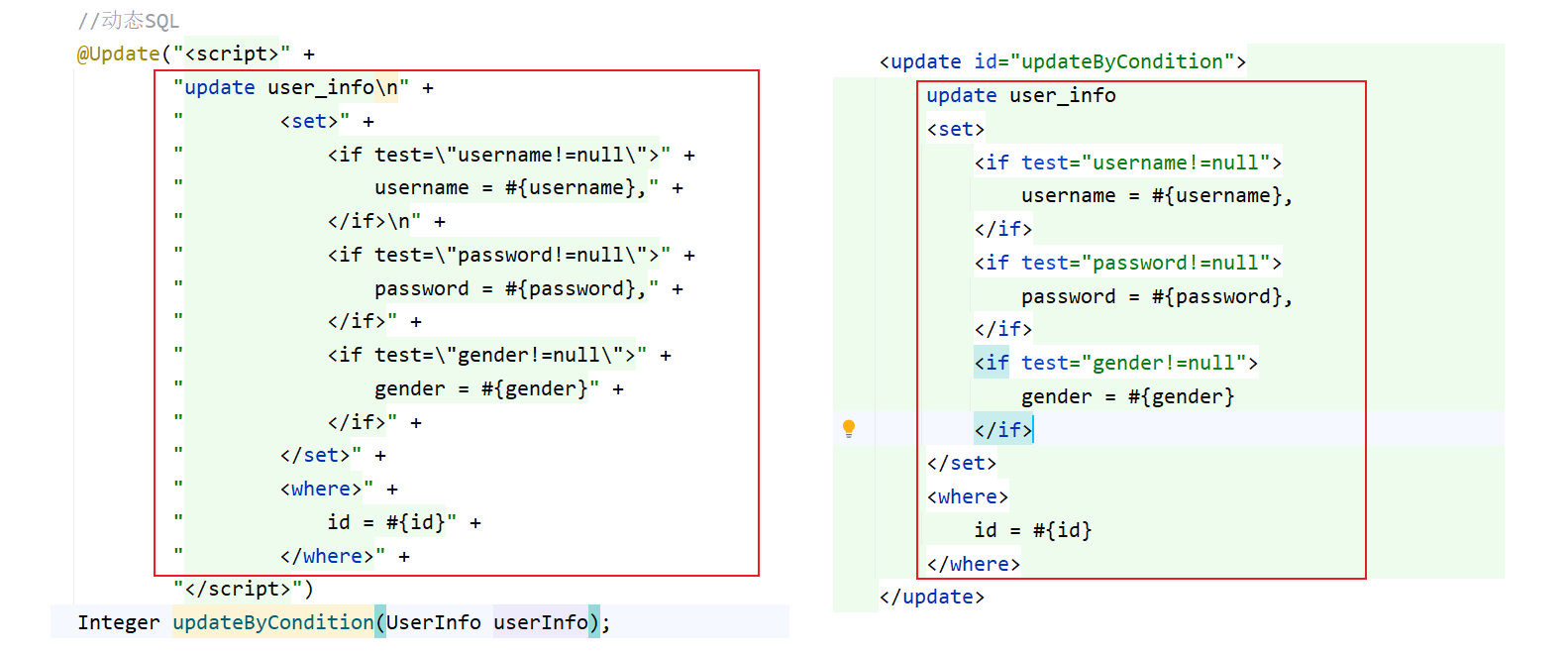
5.4. <set>
动态更新操作也是,当后面有值的时候就更新,没有值的时候就不更新,<set> 标签的作用和 where 类似,也是后面有值的话就生成 set 关键字并且去除右边的逗号,但是后面设置的内容也不能全部是空,此时就算没有生成 set 标签,但是前面还有一个 update 关键字,最后的 SQL 语句还是有问题
<update id="updateByCondition">
update user_info
<set>
<if test="username!=null">
username = #{username},
</if>
<if test="password!=null">
password = #{password},
</if>
<if test="gender!=null">
gender = #{gender}
</if>
</set>
<where>
id = #{id}
</where>
</update>5.5. <foreach>
foreach 用于在 SQL 语句中遍历集合,动态地构建包含多个参数的 SQL 语句,比如IN子句、批量插入语句等
- collection:绑定方法参数中的集合,如 List,Set,Map 或数组对象。
- item:遍历时的每一个对象。
- open:语句块开头的字符串。
- close:语句块结束的字符串。
- separator:每次遍历之间间隔的字符串。
<delete id="batchDelete">
delete from user_info where id in
<foreach collection="ids" separator="," item="id" open="(" close=")">
#{id}
</foreach>
</delete>
5.6. <include>
<include>标签主要用于代码复用。它可以将一个 SQL 片段(通常是在<sql>标签中定义的)包含到另一个 SQL 语句中,使得 SQL 语句的编写更加模块化,减少重复代码
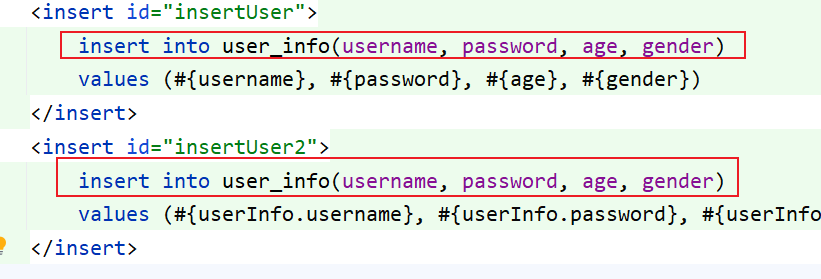
例如上面的重复语句就可以提取出来
<sql id="insertCol">
insert into user_info(username, password, age, gender)
</sql>然后就可以通过 include 标签来引用了
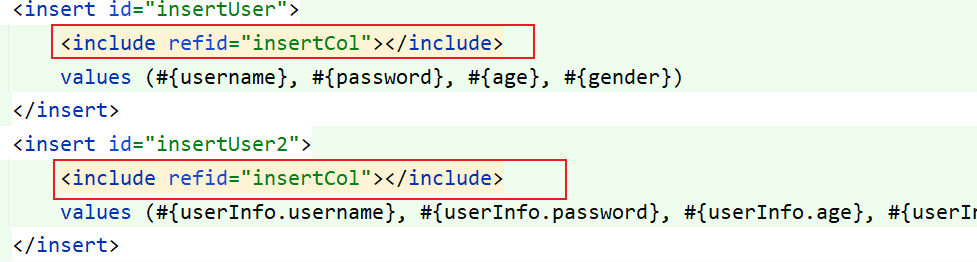
6. 注解方式的动态 SQL
注解方式就是把原来 XML 中的 SQL 语句部分写到注解的 <script> 标签下,可以看出,由于注解中是字符串拼接的方式,这种方法是非常容易出错的,而且排查错误也是有些困难的
主页