DataWorks快速入门
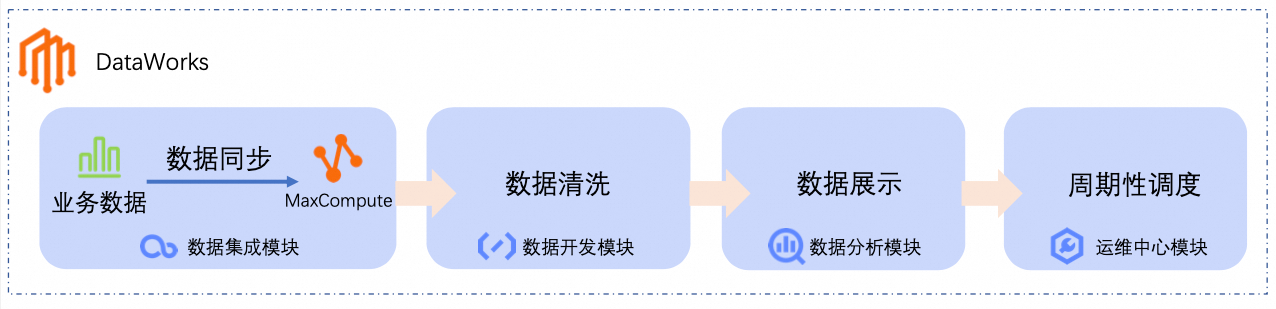
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。本文以DataWorks的部分核心功能为例,指导您使用DataWorks接入数据并进行业务处理、周期调度以及数据可视化。
入门简介
通过本快速入门,您可以快速完成以下操作。
-
数据同步:通过DataWorks的数据集成模块,创建离线同步任务,将业务数据同步至大数据计算平台(如MaxCompute数仓)。
-
数据清洗:在DataWorks的数据开发模块中,对业务数据进行处理、分析和挖掘。
-
数据展示:在DataWorks的数据分析模块中,将分析结果转化为图表,便于业务人员理解。
-
周期性调度:为数据同步和数据清洗流程配置周期性调度,使其定时执行。
前提条件
为确保本教程可以顺利进行,推荐使用阿里云主账号或具备AliyunDataWorksFullAccess权限的RAM用户。具体操作,请参见准备阿里云账号(主账号)或准备RAM用户(子账号)。
说明
DataWorks提供了完善的权限管控机制,支持在产品级与模块级对权限进行管控,如果您需要更精细的权限控制,请参见DataWorks权限体系功能概述。
准备工作
-
创建工作空间并绑定资源组。
本教程以华东2(上海)地域为例,介绍DataWorks快速入门,您需要登录DataWorks管理控制台,切换至华东2(上海)地域,查看该地域是否开通DataWorks。
说明
本教程以华东2(上海)为例,在实际使用中,请根据实际业务数据所在位置确定开通地域:
-
如果您的业务数据位于阿里云的其他云服务,请选择与其相同的地域。
-
如果您的业务在本地,需要通过公网访问,请选择与您实际地理位置较近的地域,以降低访问延迟。
-
如果未开通,单击0元组合购买,通过组合购买,一站式完成DataWorks开通、默认空间创建以及资源组绑定。
新开通DataWorks步骤
-
如果已开通,则需要手动创建本次教程使用的工作空间、资源组及资源组绑定操作。
手动创建工作空间、资源组及资源组绑定操作
-
-
为资源组绑定的VPC配置EIP。
本教程使用的电商平台公开测试业务数据需要通过公网获取,而上一步创建的通用型资源组默认不具备公网访问能力,需要为资源组绑定的VPC配置公网NAT网关,添加EIP,使其与公开数据网络打通,从而获取数据。
配置步骤
操作步骤
本文以如下场景为例,指导您快速体验DataWorks的相关功能:
假设某一电商平台将商品信息、订单信息存储在MySQL数据库中,需要定期对订单数据进行分析,通过可视化的方式查看每日最畅销商品类目排名表。
步骤一:数据同步
-
创建数据源。
DataWorks通过创建数据源的方式,接入数据来源和数据去向,因此,本步骤需要分别创建MySQL和MaxCompute两个数据源。
-
MySQL数据源,用于连接数据来源(存储业务数据的MySQL数据库),为本教程提供原始业务数据。
说明
您无需准备本教程使用的原始业务数据,为方便测试和学习,DataWorks为您提供测试数据集,相关表数据已存储在公网MySQL数据库中,您只需创建MySQL数据源接入即可。
创建MySQL数据源步骤
-
MaxCompute数据源,用于连接数据去向(MaxCompute数仓),将MaxCompute数据源绑定至数据开发后,能够为本教程提供数据存储和计算能力。
-
如果您的项目空间中存在已添加的MaxCompute数据源,则无需进行此步骤。
-
如果您的项目空间中没有添加MaxCompute数据源,在参考如下步骤创建。
创建MaxCompute数据源步骤
-
-
-
数据开发绑定MaxCompute数据源。
需要先将MaxCompute数据源绑定至数据开发,后续才能在数据开发模块中对MaxCompute的数据进行处理。
-
在左上角单击

> 全部产品 > 数据开发与运维 > DataStudio(数据开发)。
-
在左侧导航栏单击数据源(

),找到已创建的MaxCompute数据源,单击绑定。
说明
如果您的数据开发模块已绑定了MaxCompute数据源,则无需进行此步骤。

-
-
创建虚拟节点,用于统筹管理整个电商平台销售数据分析的业务流程。该节点为空跑任务,无须编辑代码。
在左侧导航栏单击数据开发,找到业务流程 > Workflow,然后右键Workflow,选择新建节点 > 通用 > 虚拟节点,自定义节点名称,本教程以
Workshop为例。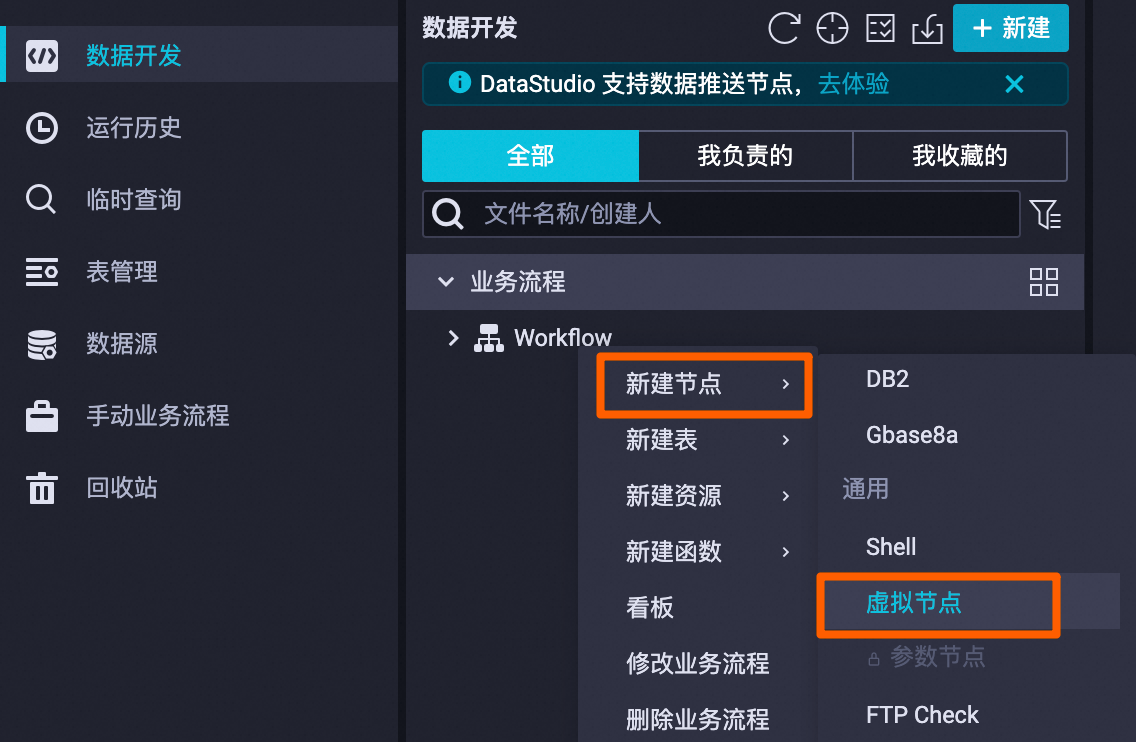
-
创建离线同步任务。
本教程使用的测试数据涉及两张表(商品信息源表
item_info和订单信息源表trade_order),这两张表存储于MySQL数据源关联的MySQL数据库中,本步骤需要分别创建两个离线同步节点(节点名称以ods_item_info和ods_trade_order为例),用于将item_info表和trade_order表同步至MaxCompute数据源关联的MaxCompute数仓中,然后再进行后续数据开发。-
创建ods_item_info离线同步节点
-
创建ods_trade_order离线同步节点
-
步骤二:数据清洗
数据已从MySQL同步至MaxCompute后,获得两张数据表(商品信息表ods_item_info和订单信息表ods_trade_order),您可以在DataWorks的数据开发模块对表中数据进行清洗、处理和分析,从而获取每日最畅销商品类目排名表。
说明
-
运行ODPS节点时,会展示费用预估,由于每一个ODPS节点配置的SQL中同时包括CREATE和INSERT语句,INSERT时,表还未创建,因此可能提示预估费用失败,请忽略此报错,直接运行即可。
-
DataWorks提供调度参数,可实现代码动态入参,您可在SQL代码中通过
${变量名}的方式定义代码中的变量,并在调度配置 > 调度参数处,为该变量赋值。调度参数支持的格式,详情请参见调度参数支持的格式。本示例SQL中使用了调度参数${bizdate},表示业务日期为前一天。
-
创建
dim_item_info节点。基于
ods_item_info表,处理商品维度数据,产出商品基础信息维度表dim_item_info。操作步骤
-
创建
dwd_trade_order节点。基于
ods_trade_order表,对订单的详细交易数据进行初步清洗、转换和业务逻辑处理,产出交易下单明细事实表dwd_trade_order。操作步骤
-
创建
dws_daily_category_sales节点。基于
dwd_trade_order表和dim_item_info表,对DWD层经过清洗和标准化的明细数据进行汇总,产出每日商品类目销售汇总表dws_daily_category_sales。操作步骤
-
创建
ads_top_selling_categories节点。基于
dws_daily_category_sales表,产出每日最畅销商品类目排名表ads_top_selling_categories。操作步骤
步骤三:数据展示
您已经将从MySQL中获取的原始测试数据,经过数据开发处理,汇总于表ads_top_selling_categories中,现在可查询表数据,查看数据分析后的结果。
-
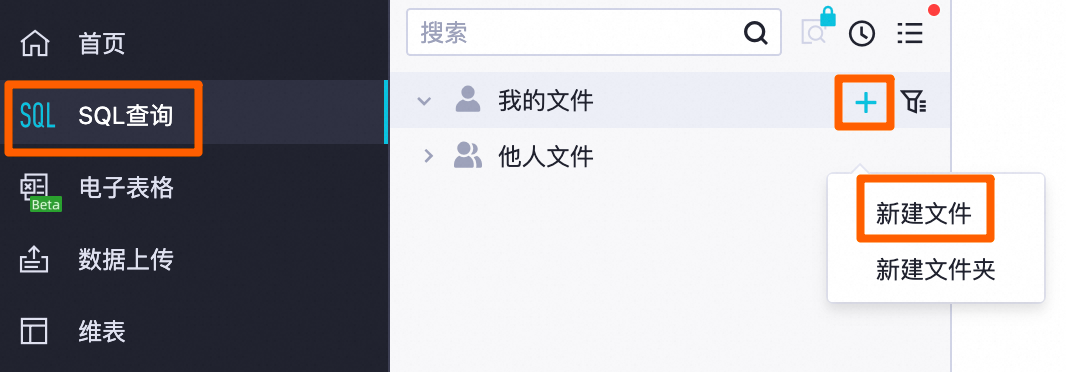
在左上角单击
> 全部产品 > 数据分析 > SQL查询。
-
在我的文件后单击

> 新建文件,自定义文件名后单击确定。
-
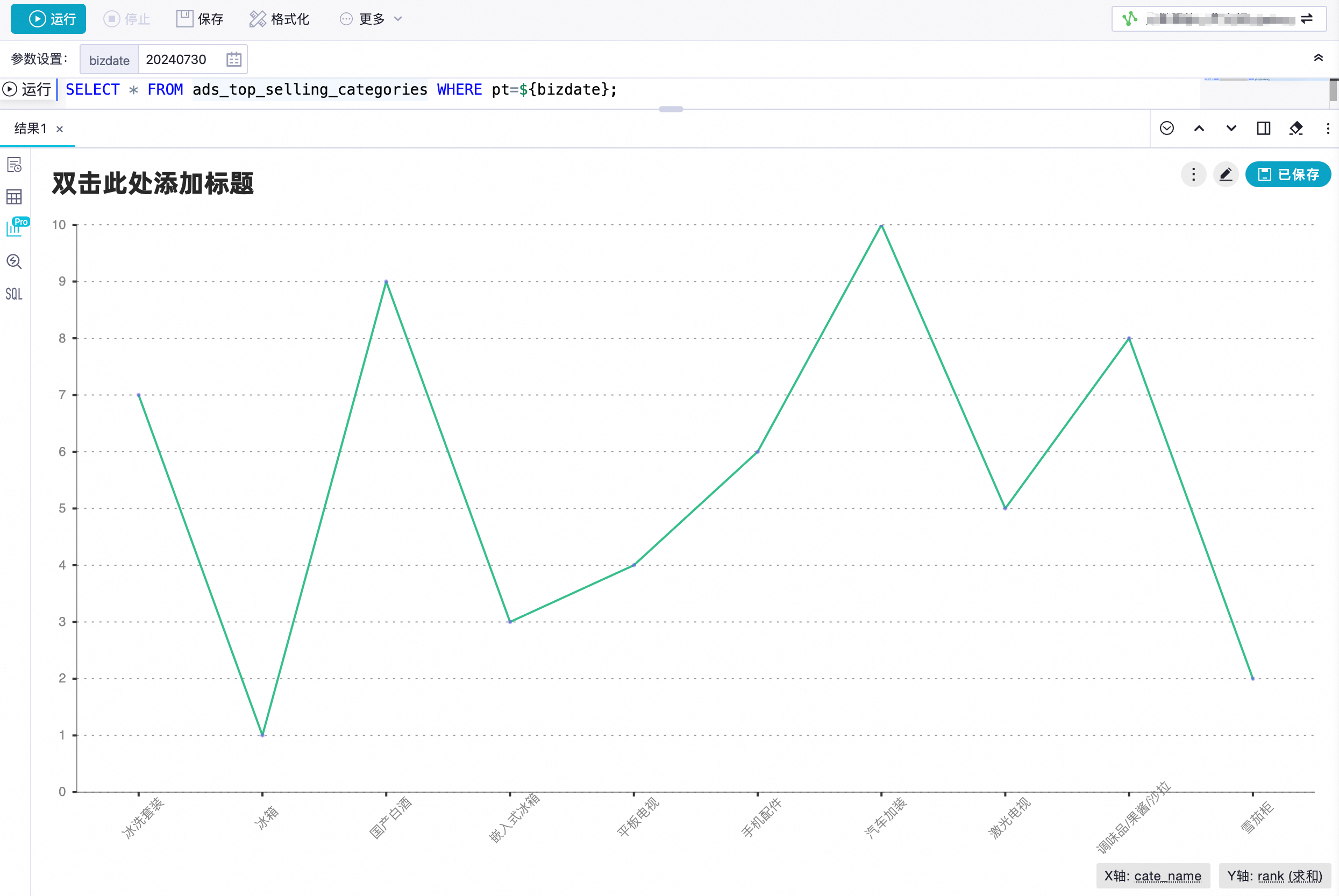
在SQL查询页面,配置如下SQL。
SELECT * FROM ads_top_selling_categories WHERE pt=${bizdate}; -
单击顶部的运行(

),根据页面提示,在右上角选择MaxCompute数据源后单击确定,然后在费用预估页面,单击运行。
-
在查询结果中单击

,查看可视化图表结果,您可以单击图表右上角的

自定义图表样式。自定义图表样式的更多信息,请参见增强分析(卡片和报告)。
-
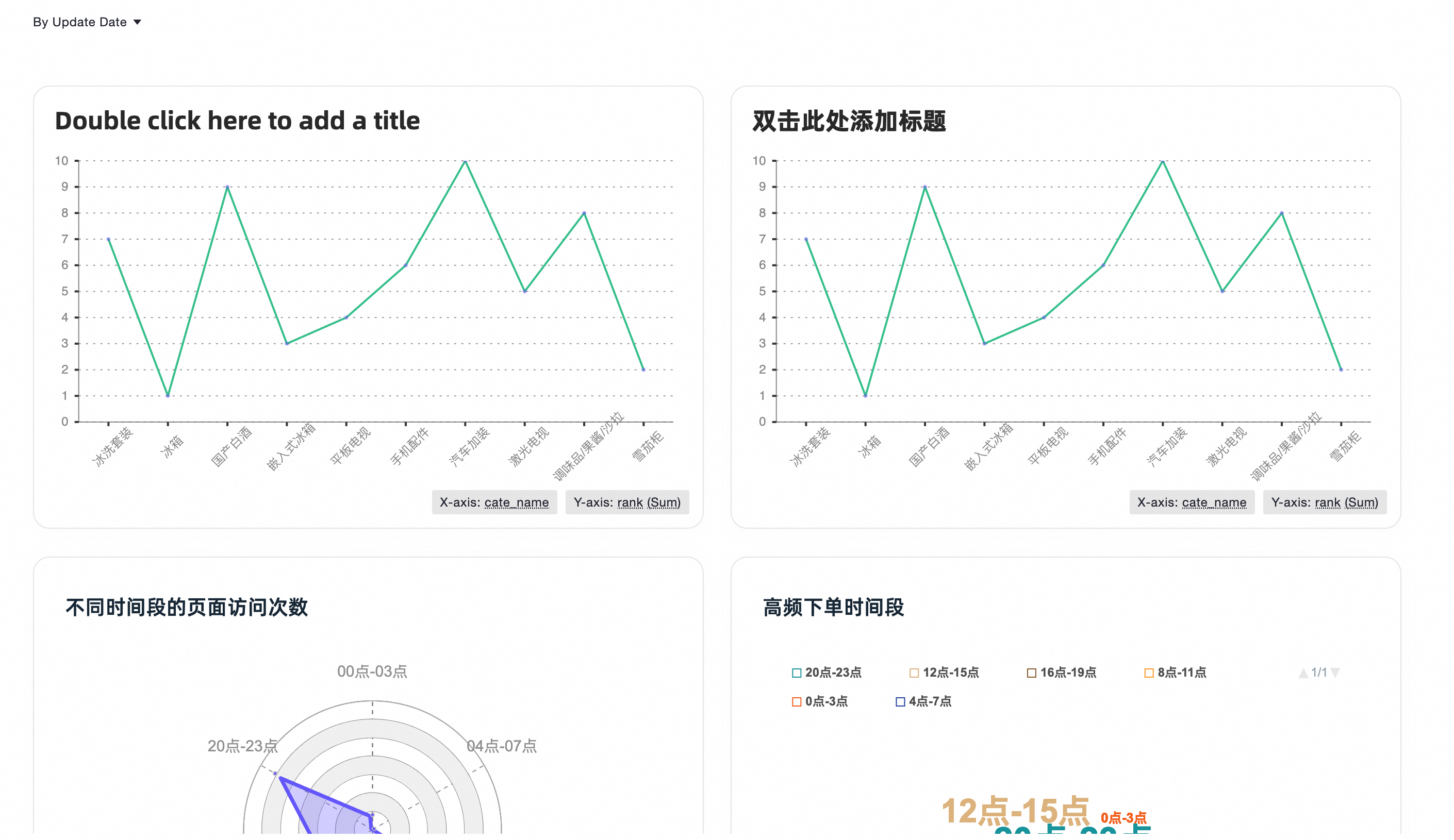
您也可以单击图表右上角保存,将图表保存为卡片,然后在左侧导航栏单击卡片(

)查看。
步骤四:周期性调度
通过完成前文操作步骤,您已经获取了前一天各类商品的销售数据,但是,如果需要每天获取最新的销售数据,则可以为数据开发中各任务节点配置周期任务,使其周期性定时执行。
说明
为简化操作,快速入门教程以可视化方式为业务流程配置调度,DataWorks还支持手动精细化配置,各任务节点支持根据SQL自动解析上下游依赖,调度配置的更多信息,请参见任务调度配置。
-
在左上角单击
> 全部产品 > 数据开发与运维 > DataStudio(数据开发)。
-
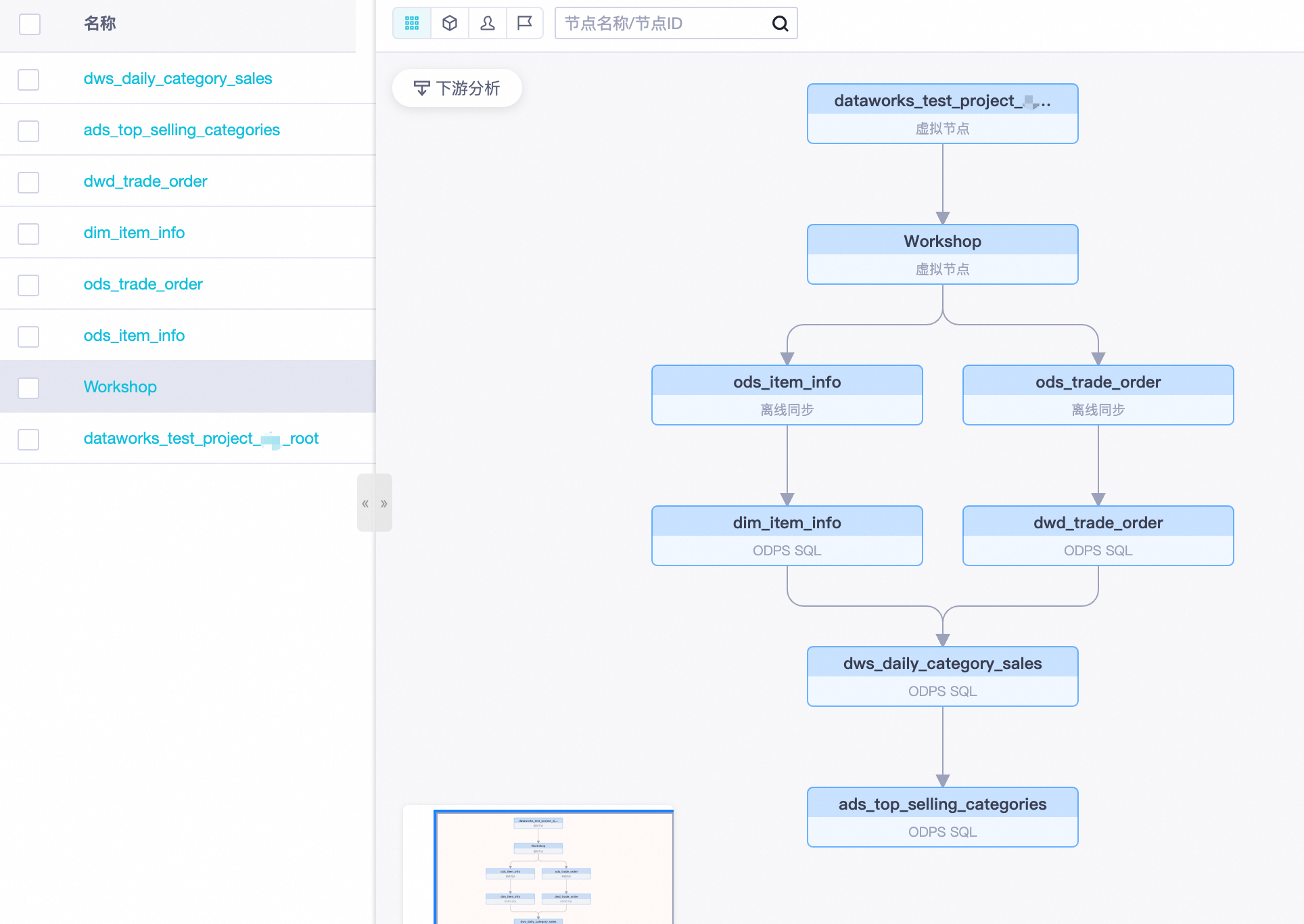
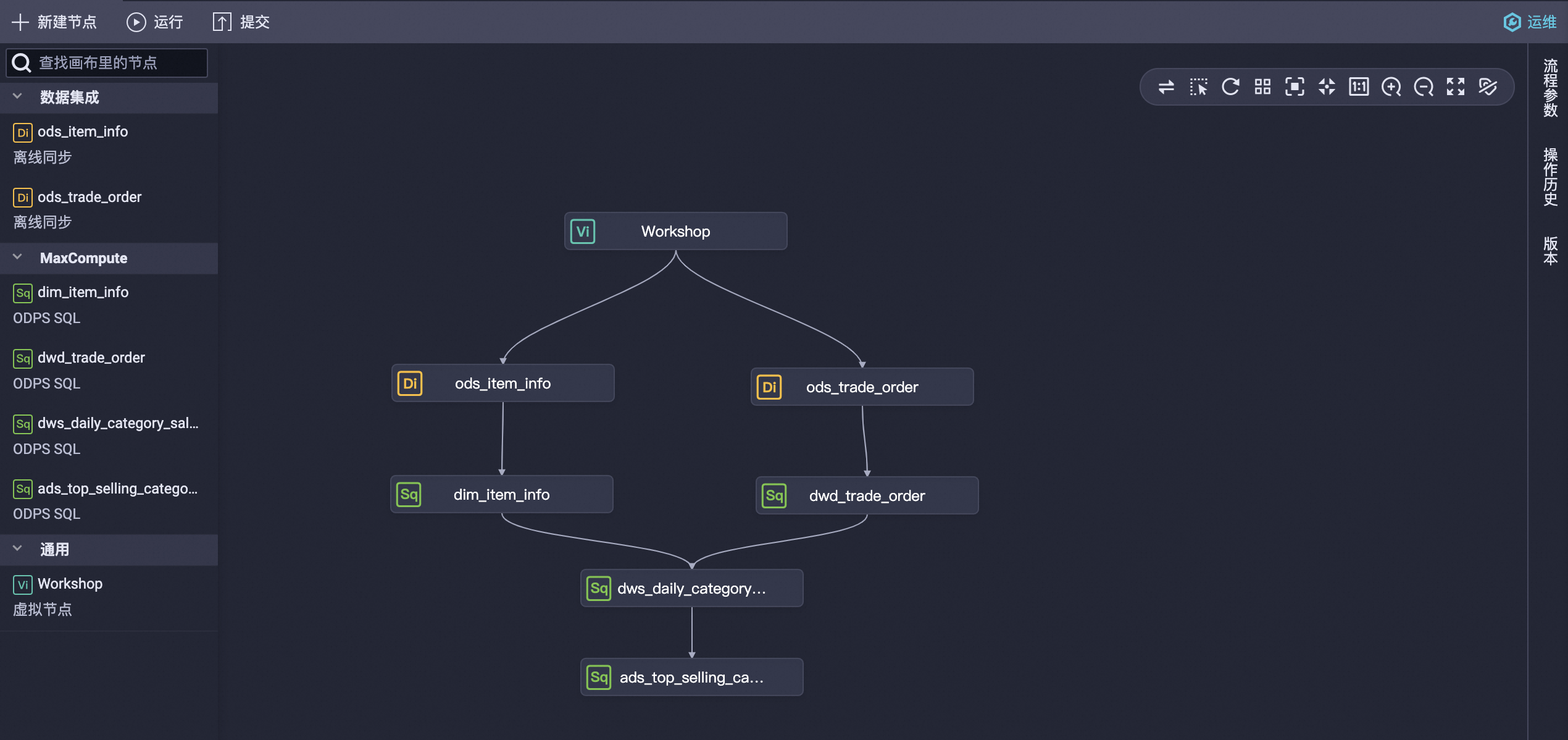
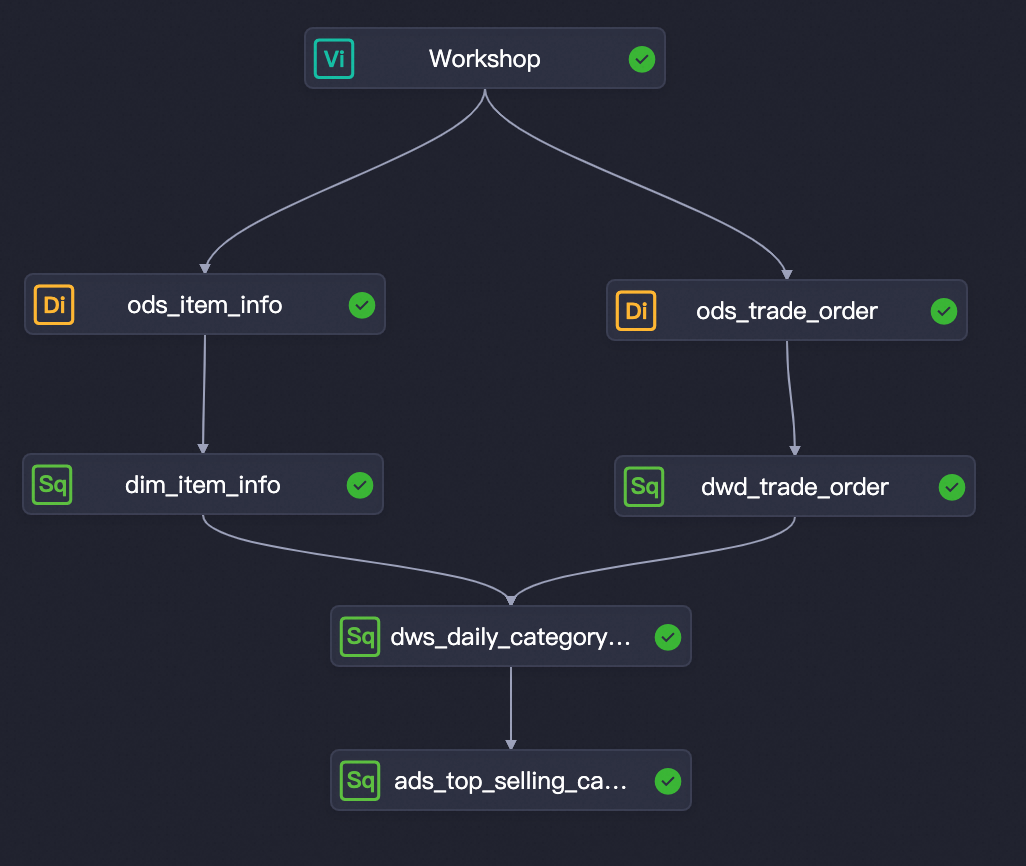
双击业务流程Workflow,在画布中移动各节点位置并按下图拖拽出各节点的上下游依赖关系。
-
单击右侧流程参数,配置参数名称为
bizdate,参数值或表达式为$bizdate,单击保存。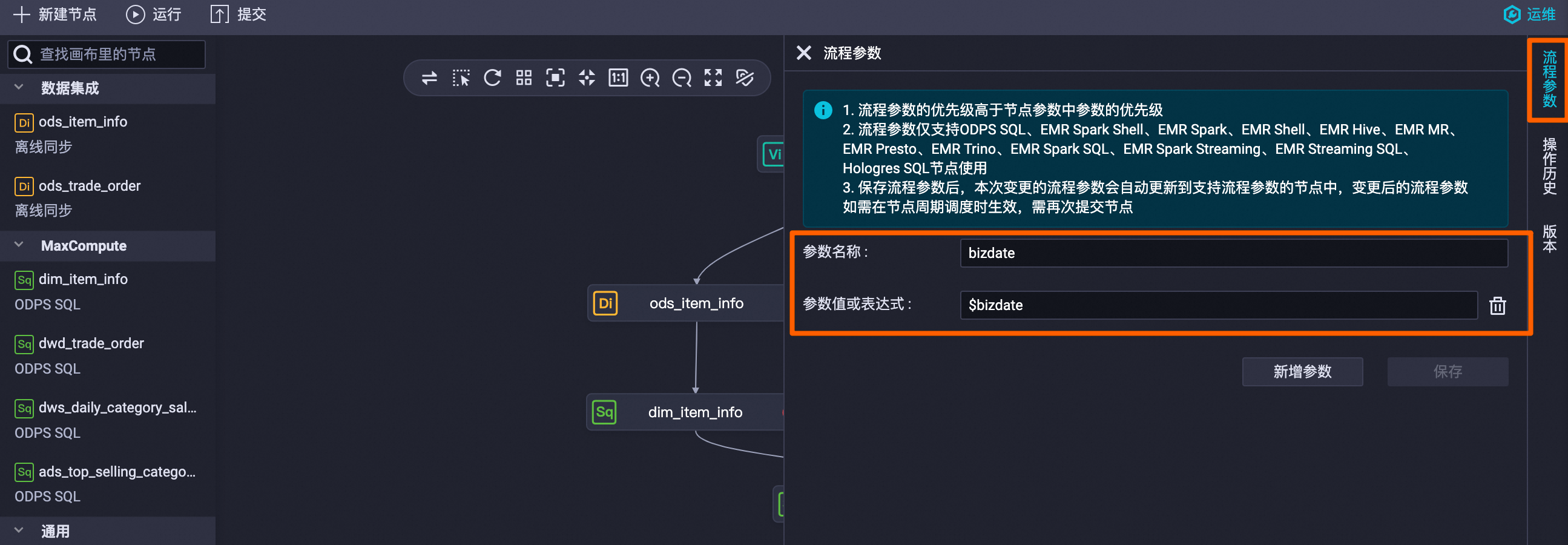
-
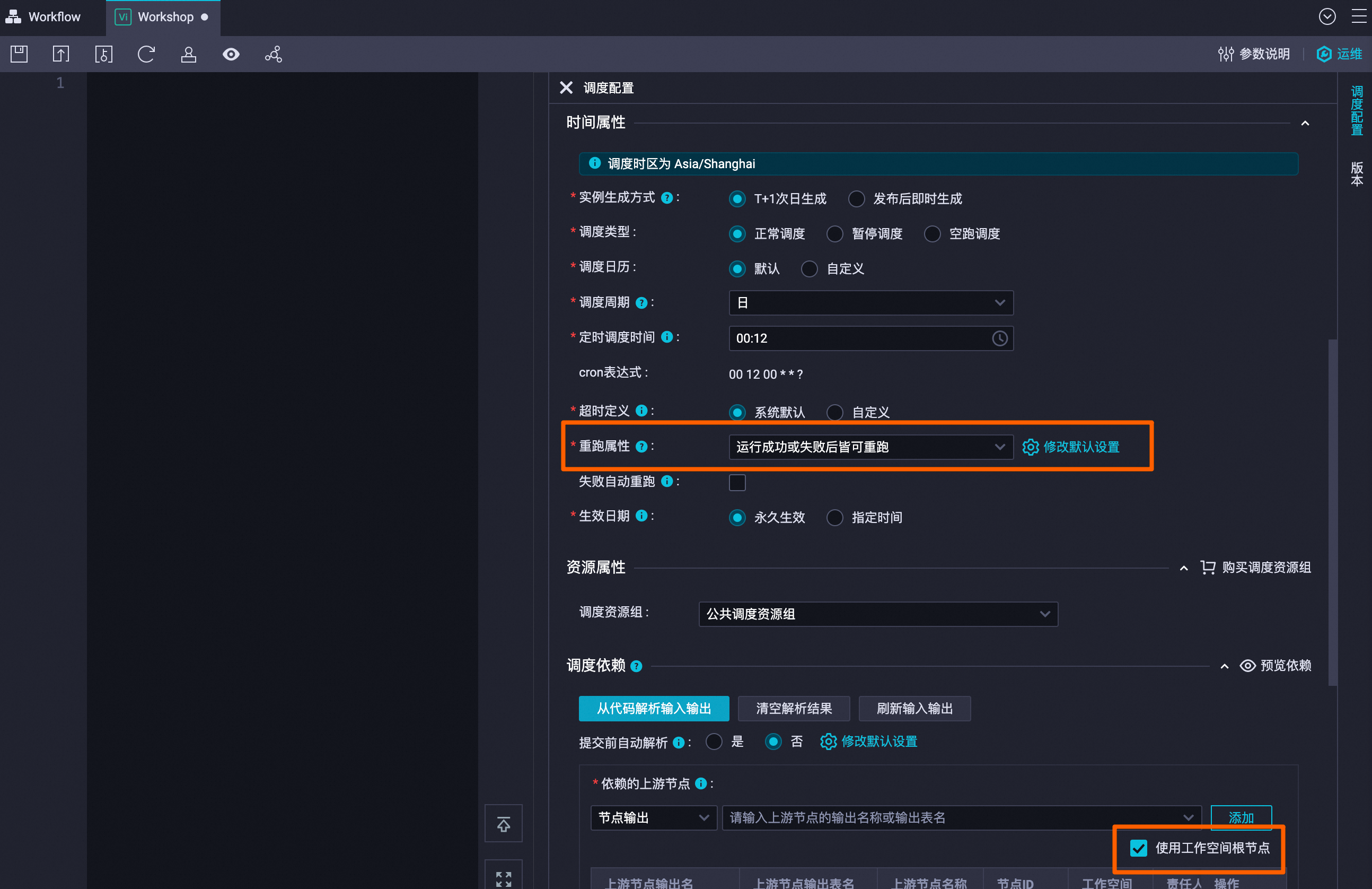
双击虚拟节点(Workshop),配置如下周期调度参数后,单击顶部的保存(

)。
说明
其他参数保持默认即可。
-
切换至Workflow业务流程页签,单击顶部的运行,参数bizdate填写为前一天(例如今天为20240731,则此处填写为20240730),测试所有流程是否均能成功运行。
-
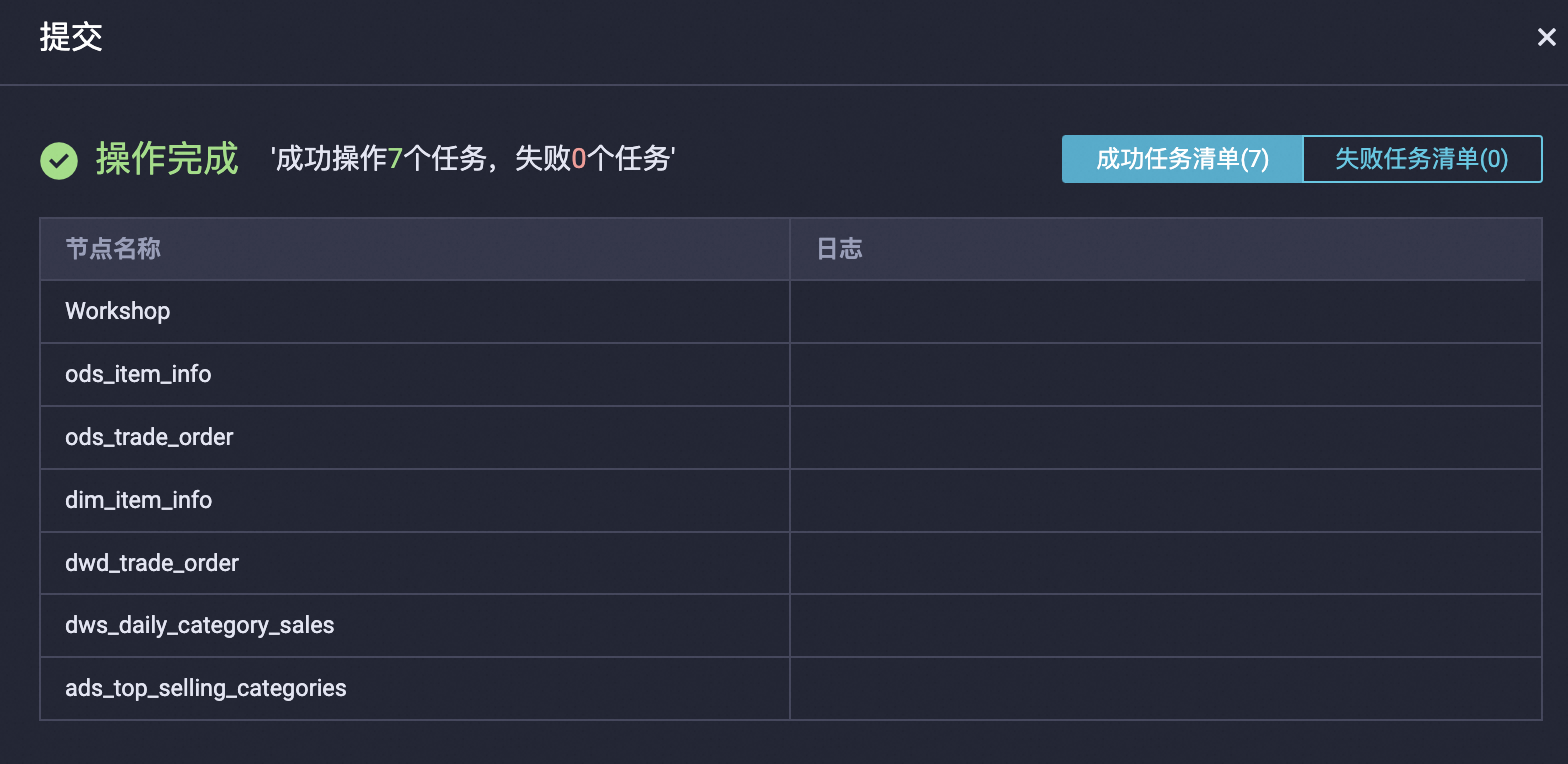
所有节点均能成功运行后,点击顶部的提交,将流程中所有节点提交至运维中心。
-
在左上角单击
> 全部产品 > 数据开发与运维 > 运维中心(工作流)。
-
在周期任务运维 > 周期任务中即可看到已创建的周期任务。
说明
如需展示如下图的所有上下游依赖节点,请右键单击Workshop节点,选择展开子节点 > 四层。