一文详解kafka知识点
目录
1、kafka定义
2、消息队列
2.1、产品选择
2.2、应用场景
2.3、消息队列的两种模式
3、kafka架构
4、kafka生产者
4.1、kafka生产者原理
4.2、kafka生产者异步发送
4.3、同步发送
4.4、分区
4.4.1、kafka分区好处
4.4.2、分区策略
4.4.3、自定义分区
4.5、生成吞吐量
4.6、数据可靠性
4.7、数据重复分析
4.7.1、幂等性
4.7.2、事务原理
4.8、数据有序
4.9、数据乱序
5、kafka-broker
5.1、zk存储
5.2、broker-工作原理
5.3、节点服役和退役
5.4、kafka-副本
5.5、Leader选举
5.6、Follower故障
5.7、Leader故障
5.8、分区副本分配
5.9、Leader Partition自动平衡
5.10、文件存储机制
5.10.1、Log文件和Index文件详解
5.11、文件清除策略
5.12、高效读写数据
6、kafka消费者
6.1、kafka消费方式
6.2、kafka消费者总体工作流程
6.3、消费者组
6.3.1、消费者组初始化流程
6.3.2、消费者组详细消费流程
6.4、kafka分区分配策略
6.4.1、Range
6.4.2、RoundRobin
6.4.3、Sticky
6.5、offset
6.5.1、自动提交offset
6.5.2、手动提交offset
6.5.3、指定offset消费
6.6、指定时间消费
6.7、漏消费与重复消费
6.8、消费者事务
6.9、数据积压
1、kafka定义
传统定义:kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
发布/订阅:消息的发布者不会将消息直接发生给特定的订阅者。而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
新定义:kafka是一个开源的分布式事件流平台(Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务。

2、消息队列
2.1、产品选择
目前企业中比较常见的消息队列产品主要有kafka、ActiveMQ、RabbitMQ、RoketMQ等
| ActiveMQ | RabbitMQ | RocketMQ | kafka | Pulsar | |
| 单机吞吐量 |
较低(万级) |
一般(万级) |
高(十万级) |
高(十万级) |
高(十万级) |
| 开发语言 |
Java |
Erlang |
Java |
Java/Scala |
Java |
| 维护者 |
Apache |
Spring |
Apache(Alibaba) |
Apache(Confluent) |
Apache(StreamNative) |
| Star数量 |
2.1K |
10.4K |
18.8K |
24.3K |
12.4K |
| Contributor |
126 |
246 |
438 |
991 |
600 |
| 社区活跃度 |
低 |
高 |
较高 |
高 |
高 |
| 消费模式 |
P2P、Pub-Sub |
direct、topic、Headers、fanout |
基于Topic和MessageTag的的Pub-Sub |
基于Topic的Pub-Sub |
基于Topic的Pub-Sub,支持独占(exclusive)、共享(shared)、灾备(failover)、key共享(key_shared)4种模式 |
| 持久化 |
支持(小) |
支持(小) |
支持(大) |
支持(大) |
支持(大) |
| 顺序消息 |
不支持 |
不支持 |
支持 |
支持 |
支持 |
| 性能稳定性 |
好 |
好 |
一般 |
较差 |
一般 |
| 集群支持 |
主备模式 |
复制模式 |
主备模式 |
Leader-Slave每台既是master也是slave,集群可扩展性强 |
集群模式,broker无状态,易迁移,支持跨数据中心 |
| 管理界面 |
一般 |
较好 |
一般 |
无 |
无 |
| 计算和存储分离 |
不支持 |
不支持 |
不支持 |
不支持 |
支持 |
| AMQP支持 |
支持 |
支持 |
支持 |
不完全支持 |
不完全支持 |
2.2、应用场景
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
(1)缓存/消峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。

(2)解耦:允许你独立的扩展或修改两边的处理过程,只确保他们遵循同样的接口约束

(3) 异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。

2.3、消息队列的两种模式
(1)点对点
- 消费者主动拉取数据,消息收到后清除消息

(2)发布/订阅模式
- 可以有多个topic主题(浏览、点赞、收藏、评论等)
- 消费者消费数据之后,不删除数据
- 每个消费者相互独立、都可以消费到数据

思考:那么什么时候删呢?
3、kafka架构
1、为方便扩展,并提高吞吐量,一个topic分为多个partition
2、配合分区的设计,提出消费者组的概念,组内每个消费者并行消费,一个分区partition只能由一个消费者来消费。
3、为了提高可用性,为每个partition增加若干副本,类型NameNode HA。分区挂掉之后follow可以成为leader。
4、ZK中记录谁是leader,kafka2.8以后也可以不配置不采用ZK。


4、kafka生产者
4.1、kafka生产者原理
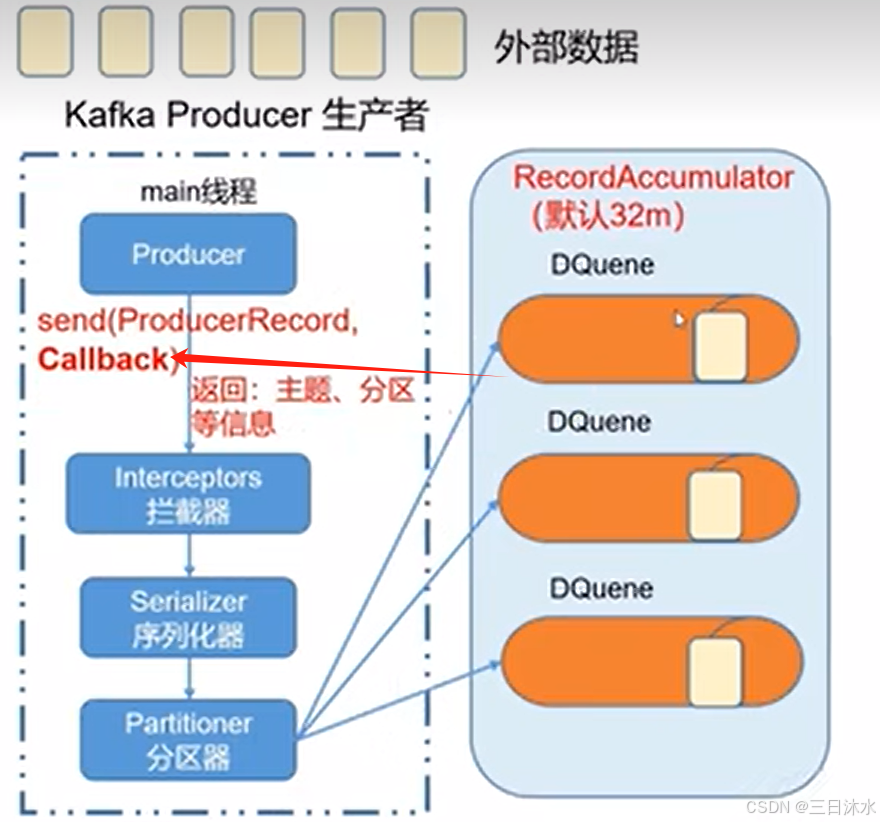
(1)主线程:kafka producer生产者send(ProduceRecord)、可选的拦截器Interceptor、序列化器、分区器。
创建多个分配,都是在内存里面完成的,(RecordAccumulator)总大小默认32M,(ProducerBatch)一批次16k。
(2)sender线程:NetWorkClient 汽车、各个请求。以每个broker为key,把数据放到一个队列里面,发送给broker应答,每个队列最多缓存5个请求。selector:高速公路,链路。
什么时候拉数据发生?
- batch.size:只有数据积累到batch.size之后,sender才会发生数据。默认16k
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。
(3)kafka集群:分为多个broker、拥有备份的能力,收到数据之后,发送acks应答。
- 0:生产者发送过来的数据,不需要等待数据落盘应答;
- 1:生产者发送过来的数据,Leader收到数据后应答;
- -1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答。-1和all等价。
什么是ISR?
- AR(Assigned Repllicas):一个partition的所有副本(就是replica,不区分leader或follower)
- ISR(In-Sync Replicas)能够和 leader 保持同步的 follower + leader本身 组成的集合。
- OSR(Out-Sync Relipcas)不能和 leader 保持同步的 follower 集合
- 公式:AR = ISR + OSR

应答机制-成功:清理掉每个分区的数据。
应答机制-失败:默认是一直重试,可以修改retries重试次数。

4.2、kafka生产者异步发送
异步发送:外部的数据发送到队列里面的,kafka回调异步发送。