智能体来了:构建用于具有结构化输出的内容审核的智能 AI Agent 智能体
智能体来了:一个专注于AI Agent开发的专业学习与交流社区!

在本教程中,我们将探索如何创建一个可以管理内容并生成结构化报告的智能 AI 智能体。我们将使用 OpenAI 的结构化输出和函数调用的新功能来构建这个高级系统。我们的目标是开发一种能够有效分析内容并提供详细、有组织的结果的人工智能。
人工智能输出的演变
OpenAI 最近推出了结构化输出功能,这改变了我们使用人工智能模型的方式。在此更新之前,开发者在使用人工智能生成的内容时面临许多挑战。响应通常只是纯文本或简单的 JSON 格式。这给开发商和企业都带来了问题。
人工智能输出缺乏结构常常导致信息不一致。开发人员必须编写复杂的代码来理解人工智能的响应,这需要花费大量时间,并且可能会导致错误。人工智能如何呈现信息也很难控制,因此很难在现有系统中使用这些输出。
这些限制使得为需要精确、结构化数据的任务构建可靠的应用程序变得尤其具有挑战性。处理法律文件、合规报告和业务分析的团队发现,他们花在处理人工智能输出上的时间比实际从中受益的时间还要多。
游戏规则改变者:结构化输出
但现在,情况发生了变化。 OpenAI 引入了一种称为“结构化输出”的东西。这意味着人工智能现在可以以更易于使用的格式为我们提供信息。想象一下,询问食谱并返回一份组织整齐的成分和步骤列表,而不仅仅是一段文本。这就是我们正在谈论的改进。对于我们的内容审核智能体来说,这确实令人兴奋。我们现在可以向人工智能询问精确格式的特定类型的信息。需要法律条款、财务数据或合规要求?人工智能可以以易于使用的结构化方式提供这些。这节省了处理和组织信息的大量时间和精力。
但这还不是全部。 OpenAI 还在其人工智能模型中添加了一种称为“函数调用”的功能。这就像让我们的人工智能智能体能够根据其处理的信息按下按钮和拉动控制杆。它不仅提供数据,还可以采取行动。
通过结合结构化输出和函数调用,我们的智能体变得异常强大。它可以处理多个信息源,做出复杂的决策,并创建高度定制的报告。这就像拥有一个超级智能的助手,不仅可以理解复杂的信息,还可以用它做一些有用的事情。这种人工智能对于需要快速审查大量内容的企业来说非常有用。它可以帮助确保内容符合某些标准、标记潜在问题,甚至提出改进建议。而且由于它运行快速且一致,因此可以将人类主持人解放出来,专注于更复杂的任务。
在本教程中,我们将逐步介绍如何构建这种人工智能智能体。我们将向您展示如何设置它、如何使用这些新功能以及如何使其满足您的特定需求。最后,您将拥有一个强大的工具,可以帮助完成各种内容审核任务。
让我们开始编码
首先,为我们的项目创建一个新目录:
mkdir structuredOutput
cd structuredOutput
接下来,让我们设置一个虚拟环境。这将帮助我们将项目依赖项与其他 Python 项目分开管理。
对于 Windows:
python -m venv venv
venv\Scripts\activate
对于 macOS 和 Linux:
python3 -m venv venv
source venv/bin/activate
激活虚拟环境后,让我们安装所需的库:
pip install pydantic openai pandas colorama python-dotenv supabase
现在,在structuredOutput目录中创建一个app.py文件。这将是我们项目的主文件。
接下来,在同一目录中创建一个.env文件。该文件将存储我们的敏感信息,例如 API 密钥。将以下占位符添加到文件中:
OPENAI_API_KEY=your_openai_api_key_here
SUPABASE_URL=your_supabase_url_here
SUPABASE_KEY=your_supabase_key_here
如果您还没有这些密钥,请不要担心。在下一部分中,我们将指导您创建 Supabase 帐户、设置表并获取必要的凭据。如果您还没有 OpenAI API 密钥,我们还将解释如何获取它。
通过以这种方式设置我们的环境,我们可以确保我们的项目井井有条,我们的依赖项得到管理,并且我们的敏感信息得到保护。当我们继续构建结构化输出智能体时,这种方法将为我们的成功奠定基础。
在接下来的部分中,我们将深入了解设置 Supabase 和 OpenAI 的细节,然后我们将开始构建智能体的核心功能。敬请关注!
设置 API 密钥
现在我们已经有了项目结构,接下来让我们获取应用程序所需的 API 密钥。
OpenAI API 密钥
要获取您的 OpenAI API 密钥:
- 访问您的 OpenAI 仪表板:https: //platform.openai.com/settings/organization/general
- 查找 API Keys 部分并创建一个新的密钥
- 复制此密钥并将其粘贴到
OPENAI_API_KEY变量的.env文件中
苏帕贝斯简介
Supabase 是一种开源 Firebase 替代品,提供了一套用于构建可扩展且安全的应用程序的工具。它在一个包中提供 PostgreSQL 数据库、身份验证、即时 API 和实时订阅。
我们在这个项目中使用 Supabase 有几个原因:
- 轻松设置:Supabase 提供了一个用户友好的界面来创建和管理数据库。
- PostgreSQL 的强大功能:它构建在 PostgreSQL 之上,使我们能够访问强大的、功能齐全的数据库。
- 实时功能:Supabase 允许实时数据同步,这对于协作文档生成非常有用。
- 内置身份验证:虽然我们在本教程中没有使用它,但 Supabase 的身份验证系统对于将来保护您的应用程序非常有价值。
- 可扩展性:Supabase 旨在随着您的应用程序进行扩展,使其适合小型项目和大规模部署。
设置 Supabase
现在,让我们设置您的 Supabase 项目:
- 如果您还没有 Supabase 帐户,请访问https://supabase.com/dashboard/sign-up创建一个 Supabase 帐户。
- 登录后,单击“新建项目”并按照提示创建新项目。
- 创建项目后,您将进入项目仪表板。
- 在左侧边栏中,单击您的项目主页并向下滚动以找到 api 部分。
- 在这里,您将找到您的项目 URL 和 API 密钥。复制这些并将它们分别添加到
SUPABASE_URL和SUPABASE_KEY变量的.env文件中。
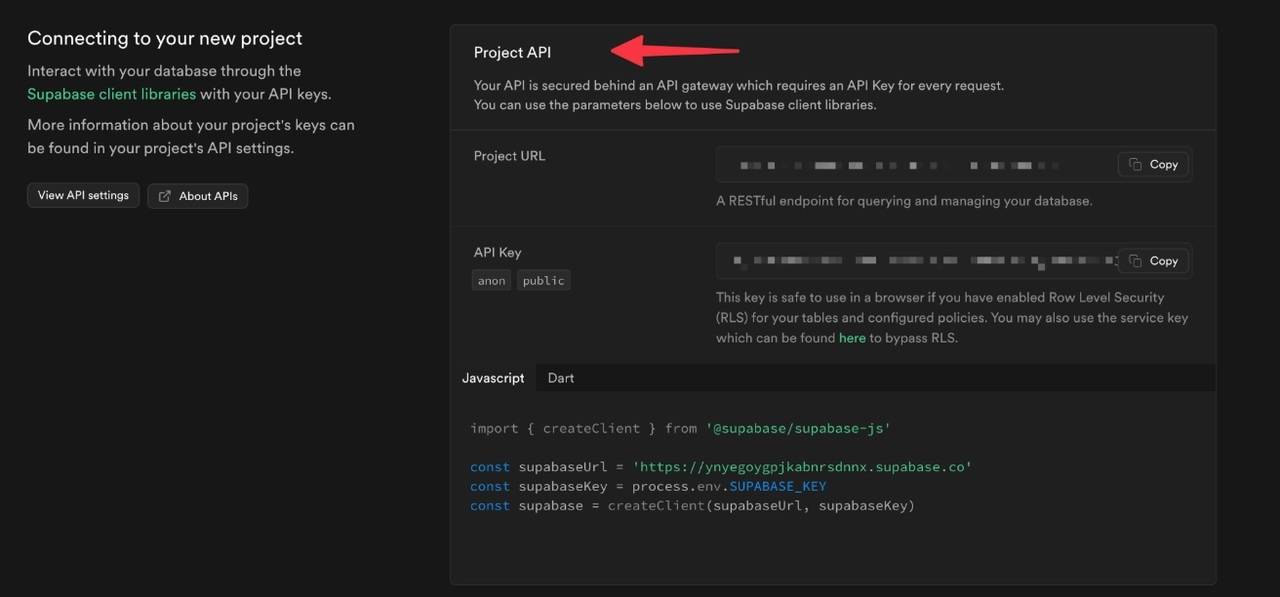
您的.env文件现在应该看起来像这样(当然,使用您的实际密钥):
OPENAI_API_KEY=sk-youropenaiapikeyhere
SUPABASE_URL=https://yourprojectid.supabase.co
SUPABASE_KEY=your.supabase.api.key.here
下一步
干得好!您现在已经为我们的项目设置了必要的帐户和 API 密钥。在下一节中,我们将深入创建 Supabase 表、选择适当的字段并为文档生成系统设置架构。这将为存储和检索人工智能智能体将使用的结构化数据奠定基础。
创建 Supabase 表
现在我们已经设置了 Supabase 项目,让我们创建一个用于存储审核数据的表。该表将成为我们结构化输出系统的支柱,使我们能够有效地存储和检索审核结果。
创建表的步骤
- 在 Supabase 项目仪表板中,查找侧边栏并单击“表编辑器”选项卡。
- 单击“创建新表”按钮。
- 将您的表命名为
MODERATION_TABLE。 - 暂时取消选中“启用行级安全性 (RLS)”选项。 (注意:在生产环境中,您需要设置适当的安全规则。)
设置架构
对于我们的审核项目,我们需要一个可以适应内容审核各个方面的特定模式。在 Supabase UI 中,您将看到标题为“列”的部分,其中包含“关于数据类型”和“通过电子表格导入数据”选项。在其下方,您将找到“名称”、“类型”、“默认值”和“主要”字段。
这是我们将使用的架构:
- id (text)
- content_id (text)
- status (text)
- content (text)
- reported_to (text)
- is_offensive (bool)
- confidence_score (float4)
- flagged_terms (text)
- created_at (timestamp)
- moderation_result (text)
使用 Supabase UI 将这些列中的每一列添加到表中。确保为每列设置正确的数据类型并将“id”列标记为主键。
添加所有列后,单击“保存”按钮以创建表。
下一步
现在我们的 Supabase 表已经建立,我们为存储 AI 审核智能体的结构化输出奠定了坚实的基础。在下一节中,我们将开始构建与此表交互的 Python 代码,包括插入新审核条目和检索现有审核条目的函数。这将构成我们审核系统数据管理功能的核心。
进入实际编码
让我们将此代码分解为几个部分,然后深入研究每个函数。我们将从前两部分开始。
导入和初始设置
让我们将此代码分解为几个部分,然后深入研究每个函数。我们将从前两部分开始。
导入和初始设置
from pydantic import BaseModel
from openai import OpenAI
import json
import re
import time
import pandas as pd
from colorama import Fore, Back, Style, init
import os
from supabase import create_client, Client
from dotenv import load_dotenv
from datetime import datetime
from typing import List
# Load environment variables from .env file
load_dotenv()
# Initialize colorama for cross-platform colored output
init(autoreset=True)
# Initialize Supabase client
url: str = os.getenv("SUPABASE_URL")
key: str = os.getenv("SUPABASE_KEY")
supabase: Client = create_client(url, key)
# Hardcoded table name
MODERATION_TABLE = "MODERATION_TABLE"
本节通过导入必要的库和初始化关键组件来设置我们的环境。我们使用 Pydantic 进行数据验证,使用 OpenAI 进行 AI 交互,使用 Supabase 进行数据库操作。 Colorama 用于彩色控制台输出,增强可读性。
数据库操作
def supabase_operation(operation, data=None, filters=None):
query = supabase.table(MODERATION_TABLE)
if operation == "insert":
query = query.insert(data)
elif operation == "select":
query = query.select("*")
elif operation == "update":
query = query.update(data)
elif operation == "delete":
query = query.delete()
else:
raise ValueError("Unsupported operation")
if filters:
for column, operator, value in filters:
if operator == "eq":
query = query.eq(column, value)
elif operator == "gt":
query = query.gt(column, value)
elif operator == "lt":
query = query.lt(column, value)
elif operator == "like":
query = query.like(column, value)
return query.execute()
这个函数, supabase_operation ,是一个与我们的 Supabase 数据库交互的多功能助手。它支持插入、选择、更新和删除等各种操作。让我们来分解一下:
- 我们首先为
MODERATION_TABLE创建一个查询对象。 - 根据操作(插入、选择、更新或删除),我们相应地修改查询。
- 如果提供了过滤器,我们会将它们应用于查询。这允许更具体的数据库操作。
- 最后,我们执行查询并返回结果。
该函数抽象了数据库操作的复杂性,使得在其余代码中更容易对我们的审核数据执行各种操作。
数据模型和审核功能
让我们检查代码的下一部分,它定义了我们的数据模型和核心调节功能。
# Step 1: Define Pydantic Models for Structured Outputs
class ModerationResult(BaseModel):
is_offensive: bool
confidence_score: float
flagged_terms: list[str]
class ModerationOutput(BaseModel):
content_id: str
content: str
status: str
is_offensive: bool
confidence_score: float
flagged_terms: List[str]
created_at: str
# Step 2: Define the Moderation Functions
def moderate_text(content_id: str, content: str) -> dict:
offensive_terms = ["badword1", "badword2", "offensivephrase"]
flagged_terms = [
term
for term in offensive_terms
if re.search(r"\b" + re.escape(term) + r"\b", content, re.IGNORECASE)
]
is_offensive = len(flagged_terms) > 0
confidence_score = 0.9 if is_offensive else 0.1 # Simplified confidence score
result = {
"content_id": content_id,
"content": content,
"status": "moderated",
"is_offensive": is_offensive,
"confidence_score": confidence_score,
"flagged_terms": flagged_terms, # Keep as a list
"created_at": datetime.utcnow().isoformat(),
}
try:
supabase_operation("insert", data=result)
print(f"{Fore.GREEN}✅ Moderation result saved to database.{Style.RESET_ALL}")
except Exception as e:
print(f"{Fore.RED}❌ Error saving to database: {e}{Style.RESET_ALL}")
return result
- Pydantic 模型:我们使用 Pydantic 来定义结构化数据模型。
ModerationResult表示核心审核输出,而ModerationOutput包含有关审核内容的附加元数据。 - moderate_text 函数:这是我们的主要审核函数。它的工作原理如下:
- 它需要一个
content_id和要审核的content。 - 它根据预定义的攻击性术语列表检查内容。
- 它计算内容是否具有攻击性并分配置信度分数。
- 结果被格式化为与我们的
ModerationOutput模型匹配的字典。 - 然后使用我们之前定义的
supabase_operation函数将结果插入到我们的Supabase 数据库中。 - 最后返回审核结果。
- 它需要一个
该功能构成了我们审核系统的核心。它是一个简化版本,可以通过更复杂的审核技术(例如机器学习模型或更复杂的规则集)进行扩展。
Pydantic 模型的使用确保我们的数据在整个应用程序中结构一致,从而更容易使用和验证。
def block_content(content_id: str) -> dict:
result = {
"content_id": content_id,
"status": "blocked",
"reason": "Content deemed too offensive.",
}
# Insert the blocked content record into the database
supabase_operation("insert", data=result)
return result
block_content函数将content_id作为输入。它旨在当内容被认为过于冒犯时将其标记为已阻止。此函数在我们的数据库中创建一条记录,指示内容已被阻止以及原因。这是维护平台内容标准的关键功能。
def issue_warning(content_id: str) -> dict:
result = {
"content_id": content_id,
"status": "warning_issued",
"reason": "Content is borderline inappropriate.",
}
# Insert the warning record into the database
supabase_operation("insert", data=result)
return result
issue_warning用于边界不适当的内容。它还采用content_id并在数据库中记录警告。此功能对于跟踪经常发布可疑内容的用户或让用户有机会在采取更严厉的行动之前修改其行为非常有用。
def report_to_human(content_id: str, content: str) -> dict:
result = {
"content_id": content_id,
"status": "reported",
"content": content,
"reported_to": "human_moderator@example.com",
}
# Insert the report record into the database
supabase_operation("insert", data=result)
return result
report_to_human函数是我们处理复杂情况的后备函数。它需要content_id和content本身。该功能会标记内容以供人工审核,这对于处理人工智能可能无法准确判断的微妙情况至关重要。
这些函数中的每一个都会返回一个字典,其中包含有关所采取操作的信息。他们都使用我们的supabase_operation函数将记录插入数据库,确保所有审核操作都被记录并可追踪。
这些功能共同创建了一个全面的审核系统。它们允许对不同类型的内容进行一系列响应,从彻底阻止到人工审核,从而在内容审核方面提供灵活性和细微差别。
现在我们需要初始化客户端并添加定义我们的模式
# Initialize the OpenAI client
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY")
)
首先,我们初始化 OpenAI 客户端。该客户端是我们与 OpenAI 强大的语言模型交互的门户。 API 密钥至关重要,因为它验证我们对 OpenAI 服务的请求。
现在,让我们分别看看每个函数模式:
moderate_text_function = {
"name": "moderate_text",
"description": "Moderate the provided text content to detect offensive language.",
"parameters": {
"type": "object",
"properties": {
"content_id": {
"type": "string",
"description": "A unique identifier for the content being moderated.",
},
"content": {
"type": "string",
"description": "The text content to be moderated.",
},
},
"required": ["content_id", "content"],
"additionalProperties": False,
},
}
moderate_text_function模式定义了我们的人工智能应该如何理解和使用我们的主要调节功能。这个模式告诉人工智能,当它需要审核文本时,应该使用这个函数。它可能包括内容 ID 和要审核的实际文本内容的参数。
block_content_function = {
"name": "block_content",
"description": "Block the content if it's deemed highly offensive.",
"parameters": {
"type": "object",
"properties": {
"content_id": {
"type": "string",
"description": "A unique identifier for the content being blocked.",
}
},
"required": ["content_id"],
"additionalProperties": False,
},
}
当需要彻底阻止内容时,将使用block_content_function模式。如果人工智能确定内容严重违反准则,需要立即删除,则会调用此函数。该架构可能包含需要阻止的内容 ID 的参数。
issue_warning_function = {
"name": "issue_warning",
"description": "Issue a warning for borderline inappropriate content.",
"parameters": {
"type": "object",
"properties": {
"content_id": {
"type": "string",
"description": "A unique identifier for the content being warned.",
}
},
"required": ["content_id"],
"additionalProperties": False,
},
}
对于issue_warning_function ,架构描述了如何针对边界内容发出警告。此功能对于有问题但不足以完全阻止的内容很有用。该架构可能包含接收警告的内容 ID 的参数。
report_to_human_function = {
"name": "report_to_human",
"description": "Report the content to a human moderator for further review.",
"parameters": {
"type": "object",
"properties": {
"content_id": {
"type": "string",
"description": "A unique identifier for the content being reported.",
},
"content": {
"type": "string",
"description": "The text content to be reported.",
},
},
"required": ["content_id", "content"],
"additionalProperties": False,
},
}
当人工智能确定需要人工干预时,将使用report_to_human_function模式。这可能适用于人工智能对自主处理没有信心的复杂情况。该模式可能包括内容 ID 和内容本身的参数,允许人工审核者查看完整的上下文。
# Define the function list
functions = [
moderate_text_function,
block_content_function,
issue_warning_function,
report_to_human_function,
]
最后,我们将所有这些函数模式编译到一个列表中。此列表代表了我们的人工智能可用于内容审核的完整工具包。当与 OpenAI API 交互时,我们将传递这个列表,让 AI 根据对内容的分析来选择最合适的函数。
通过以这种方式构建我们的功能,我们可以让人工智能清楚地了解其可以使用的内容审核工具,从而实现更智能和上下文感知的决策。
初始消息设置
messages = [
{
"role": "system",
"content": "You are an intelligent content moderation assistant. Engage in a conversation and moderate content when required. You have a set of tools to use and after every response and word blocked report to the human",
},
{
"role": "user",
"content": "Let's start the moderation. I'll provide some content.",
},
]
此部分初始化messages列表,这对于维护与 AI 的对话上下文至关重要:
- 第一条消息设置系统角色,将人工智能的行为定义为内容审核助手。
- 第二条消息模拟初始用户输入以开始对话。
这些消息为人工智能提供了初始上下文,为审核过程奠定了基础。
对于造成的混乱,我深表歉意。我将根据要求提供详细的解释以及正确的 H2 标头和代码块。
主对话循环
我们的内容审核系统的核心是主对话循环。该循环管理用户和人工智能之间正在进行的交互,处理输入、处理响应并执行审核操作。
初始化
try:
print(f"{Fore.CYAN}{Style.BRIGHT}=== Content Moderation System Initialized ===\n")
while True:
该循环从初始化阶段开始。我们打印一条欢迎消息以表明审核系统已准备就绪。这给用户一个明确的指示,表明他们可以开始与系统交互。彩色文本的使用增强了用户体验。
然后,我们进入无限 while 循环,允许我们的系统持续接受和处理用户输入,直到明确告知停止。
用户输入处理
user_input = input(f"{Fore.GREEN}User: {Style.RESET_ALL}")
if user_input.lower() in ["exit", "quit", "stop"]:
print(f"{Fore.YELLOW}Exiting the conversation. Generating final report...")
break
messages.append({"role": "user", "content": user_input})
在每次迭代中,我们处理用户输入。系统用绿色的“User:”前缀提示用户。然后,我们通过将用户的输入与退出命令列表进行比较来检查用户是否想要退出对话。如果他们没有退出,我们会将他们的输入附加到我们的消息列表中,从而维护整个对话历史记录。
内容分析
print(f"\n{Fore.BLUE}🤔 Analyzing content...{Style.RESET_ALL}")
time.sleep(1) # Reduced thinking time for better UX
response = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=messages,
functions=functions,
function_call="auto",
response_format=ModerationOutput,
)
print(f"{Fore.MAGENTA}📜 API Response received{Style.RESET_ALL}")
捕获用户的输入后,我们进入分析阶段。我们表明内容分析正在进行中,并添加短暂的暂停以获得更好的用户体验。然后,系统向 OpenAI API 发送请求,传递整个对话历史记录、可用函数,并指定 AI 可以决定是否调用某个函数。
响应处理
choice = response.choices[0]
if choice.message.function_call:
function_name = choice.message.function_call.name
function_args = json.loads(choice.message.function_call.arguments)
print(f"\n{Fore.YELLOW}🔍 Action Required: {function_name}{Style.RESET_ALL}")
print(f"{Fore.CYAN}Arguments: {json.dumps(function_args, indent=2)}{Style.RESET_ALL}")
收到API响应后,我们对其进行处理。我们检查人工智能是否决定调用一个函数。如果是这样,我们提取函数名称和参数,准备执行适当的审核操作。
函数执行
根据调用的函数,采取不同的操作:
if function_name == "moderate_text":
moderation_result = moderate_text(
content_id=function_args["content_id"],
content=function_args["content"],
)
output = ModerationOutput(**moderation_result)
print(f"\n{Fore.GREEN}💡 Moderation Output:{Style.RESET_ALL}")
print(f"{json.dumps(output.dict(), indent=2)}")
if output.is_offensive:
print(f"{Fore.RED}⚠️ Offensive Content Detected{Style.RESET_ALL}")
block_response = block_content(output.content_id)
print(
f"{Fore.RED}⛔ Content Blocked: {block_response['status']}{Style.RESET_ALL}"
)
if output.confidence_score > 0.8:
warning_response = issue_warning(output.content_id)
print(
f"{Fore.YELLOW}⚠️ Warning Issued: {warning_response['status']}{Style.RESET_ALL}"
)
report_response = report_to_human(
output.content_id, function_args["content"]
)
print(
f"{Fore.MAGENTA}📧 Reported to Human: {report_response['reported_to']}{Style.RESET_ALL}"
)
# Prepare the function call result message
function_call_result_message = {
"role": "function",
"name": function_name,
"content": json.dumps(moderation_result),
}
# Append the function call result to the messages
messages.append(
{
"role": "assistant",
"content": "Moderation completed. Here's the output.",
}
)
messages.append(function_call_result_message) # The function's response
print(
f"\n{Fore.BLUE}🔄 Integrating moderation result...{Style.RESET_ALL}"
)
time.sleep(1)
# Make a second API call with the updated messages
second_response = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=messages,
response_format=ModerationOutput,
)
# Print the final response from the model
final_message = second_response.choices[0].message.content
print(f"{Fore.GREEN}📝 Assistant Response:{Style.RESET_ALL}")
print(f"{final_message}")
对于文本审核,我们调用moderate_text函数并处理其结果。可以根据审核输出采取其他操作,例如阻止内容或发出警告。
elif function_name == "block_content":
block_response = block_content(function_args["content_id"])
print(f"{Fore.RED}⛔ Content Blocked: {block_response['status']}{Style.RESET_ALL}")
elif function_name == "issue_warning":
warning_response = issue_warning(function_args["content_id"])
print(f"{Fore.YELLOW}⚠️ Warning Issued: {warning_response['status']}{Style.RESET_ALL}")
elif function_name == "report_to_human":
report_response = report_to_human(
function_args["content_id"], function_args["content"]
)
print(f"{Fore.MAGENTA}📧 Reported to Human: {report_response['reported_to']}{Style.RESET_ALL}")
其他功能处理诸如阻止内容、发出警告或向人工管理员报告等操作。每个操作都会被执行,并且其结果会被打印出来供用户查看。
定期人工智能响应
else:
assistant_reply = choice.message.content
print(f"{Fore.CYAN}💬 Assistant Reply:{Style.RESET_ALL}")
print(f"{assistant_reply}")
如果没有进行函数调用,我们只需将 AI 的响应打印给用户。
周期完成
print(f"\n{Fore.CYAN}{Style.BRIGHT}--- End of Moderation Cycle ---\n")
错误处理和结论
except Exception as e:
print(f"{Fore.RED}❌ An error occurred: {e}{Style.RESET_ALL}")
print(
f"{Fore.GREEN}{Style.BRIGHT}✅ Moderation log saved to database.{Style.RESET_ALL}"
)
此部分管理异常并提供最终状态更新。 except块捕获并显示主循环执行期间发生的任何错误,并将它们打印为红色以便可见。最终的打印语句,无论有任何错误,都会确认审核日志已保存到数据库中,并显示为绿色以进行积极强化。这可确保用户了解错误并成功完成审核过程。
运行智能体
要运行内容审核智能体,请执行以下步骤:
- 打开终端或命令提示符。
- 导航到包含
app.py目录。 - 运行以下命令:
python app.py
这将启动智能体,您将看到初始化消息。然后,您可以通过输入消息开始与系统交互。
智能体的工作流程
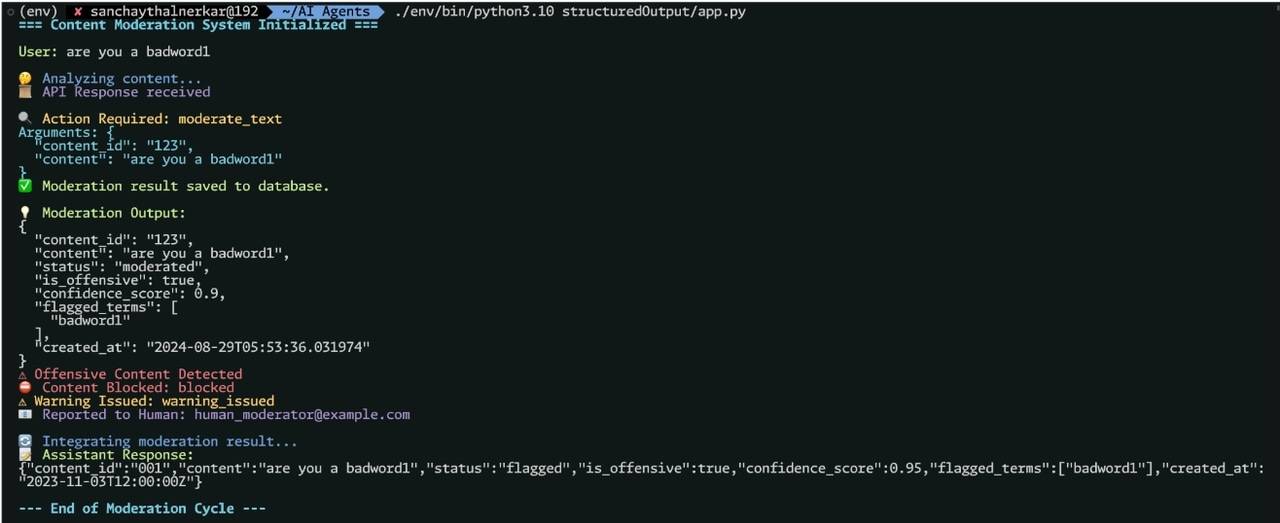
数据输入数据库

现实生活场景
在现实应用程序中,该智能体可能是更大的异步系统的一部分。它的工作原理如下:
-
聊天或社交媒体平台中的每条消息都会发送给该智能体进行审核。
-
智能体将异步处理每条消息,从而实现大容量、实时审核。
-
根据智能体的决定,消息可能是:
-
立即允许通过
-
被阻止发帖
-
标记为人工审核
-
对用户帐户触发警告或操作
-
-
审核结果将记录在数据库中,以便随着时间的推移审核和改进系统。
这种设置允许进行可扩展的、由人工智能驱动的内容审核,可以同时处理多个对话或平台上的大量消息,从而提供更安全、更可控的用户体验。
结论
在本教程中,我们使用 OpenAI 的结构化输出功能和函数调用构建了一个复杂的 AI 驱动的内容审核系统。该系统演示了如何:
- 为人工智能驱动的应用程序建立开发环境
- 集成 OpenAI 的 API 以进行高级语言处理
- 使用 Supabase 实施数据库解决方案进行日志记录和数据持久化
- 创建强大的交互式内容审核循环
通过运行python app.py ,您可以启动智能体并体验实时内容审核。在生产环境中,该系统可以扩展为异步处理多个对话,为各种平台提供高效、人工智能驱动的审核。
该项目作为构建更复杂的人工智能系统的基础,展示了在实际应用中将结构化输出与函数调用相结合的潜力。随着人工智能技术的不断发展,此类系统将在维护安全和高效的在线环境方面发挥至关重要的作用。
原文链接:
智能体来了:构建用于具有结构化输出的内容审核的智能 AI Agent 智能体