【论文速读】| RobustKV:通过键值对驱逐防御大语言模型免受越狱攻击

基本信息
原文标题:ROBUSTKV: DEFENDING LARGE LANGUAGE MODELS AGAINST JAILBREAK ATTACKS VIA KV EVICTION
原文作者:Tanqiu Jiang, Zian Wang, Jiacheng Liang, Changjiang Li, Yuhui Wang, Ting Wang
作者单位:Stony Brook University
关键词:越狱攻击、防御策略、大语言模型、KV缓存、攻击规避
原文链接:https://arxiv.org/pdf/2410.19937
开源代码:暂无
论文要点
论文简介:在大语言模型(LLM)的发展中,越狱攻击被认为是一种对模型安全性的严重威胁,攻击者通过巧妙地掩盖恶意查询使得LLM生成不当响应。目前的防御手段主要集中在防范越狱提示词上,但面对越狱提示词的适应性变化效果有限。本研究提出了一种新的防御方法RobustKV,通过策略性地逐出低重要性标记的KV缓存,减少恶意查询对模型响应的影响。实验证明RobustKV在保持模型正常响应的同时,有效抑制了各类越狱攻击,并为对抗适应性攻击提供了新的启示。
研究目的:本研究旨在提出一种无需大幅增加计算负担的越狱攻击防御机制。与传统防御方法不同,RobustKV通过对大语言模型的KV缓存进行优化,选择性地清除恶意查询中低重要性标记的KV值,降低攻击者通过调整提示词逃避防御的成功率,增强了模型的防御能力。
引言
大语言模型在各种任务中展现了优异性能,但也暴露了若干安全隐患,如训练数据泄露、有毒内容生成和恶意微调等。越狱攻击是一类典型的威胁手段,攻击者可以通过在提示词中嵌入恶意查询,绕过模型内置的安全防护,使其生成恶意响应。现有防御措施多集中在调整提示词层面,但由于攻击者可采用任意、动态的方式修改提示词,这种防御策略的局限性逐渐显现。此外,许多现有防御策略带来了计算开销的问题,限制了其实际部署的可行性。RobustKV的提出正是为了解决上述挑战,它通过优化KV缓存,直接削弱恶意查询的效果,避免了对提示词的过分依赖,且显著减少了计算成本。此策略为对抗越狱攻击提供了新的思路。

相关工作
现有研究主要聚焦于越狱攻击和防御方法。越狱攻击可以分为手工设计和基于学习的自动化生成,其中以GCG、AutoDAN等为代表的学习型攻击具备较强的适应性,能动态调整提示词以绕过防御。现有防御手段,如SmoothLLM和GoalPriority,多数针对提示词进行调整,通过扰动、优先指令等手段干扰攻击效果。然而,这些防御策略在面对灵活的越狱攻击时往往力不从心。此外,一些KV缓存优化方法(如SnapKV等)主要用于模型性能优化,未在越狱防御中得到广泛应用。RobustKV填补了这一空白,通过KV缓存逐出实现了更有效的防御。
研究背景
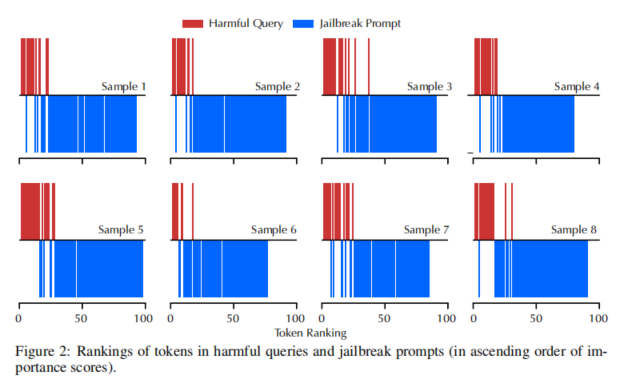
研究背景主要聚焦在大语言模型的威胁模型和KV缓存的重要性。攻击者通常通过伪装查询(即越狱提示词)混淆模型,从而生成恶意响应。为了使攻击有效,提示词中所包含的标记需要具备足够的“重要性”,而越狱提示词相对自由,恶意查询则需精准表述恶意信息。RobustKV正是基于这一观察,策略性地清除KV缓存中不重要的标记,从而抑制恶意查询的影响。此方法开辟了利用KV缓存优化技术防御越狱攻击的新途径。
研究方法
RobustKV的研究方法旨在通过精确的KV缓存管理来削弱恶意查询的效果。具体步骤分为三部分:
(1)注意力剖析:首先对输入提示词进行编码,收集标记在模型内各层注意力头中的权重分布,计算出每个标记的重要性。通过这种重要性分析,RobustKV能够识别出哪些标记在实现越狱攻击中是关键性的,哪些相对不重要。
(2)选择性逐出:根据标记的注意力权重,将重要性最低的一部分标记从模型的KV缓存中剔除。通过这种方式,RobustKV有效地减少了恶意查询在模型生成响应时的影响力,使得模型难以根据提示生成完整的恶意回应。
(3)响应生成:在执行KV缓存逐出后,模型继续完成剩余的推理过程生成响应,确保对普通查询的回答不产生影响。与传统防御策略不同,RobustKV通过精细的KV逐出设计,实现了对越狱攻击的高度抑制,既保持了模型对良性查询的响应质量,也在恶意查询的生成上增加了攻击者规避防御的难度。这种方法在有效性和计算效率上实现了创新,为LLM越狱防御提供了全新思路。
研究评估
实验设置:研究在Llama2、Vicuna等主流开源模型上评估了RobustKV的效果,采用了520条来自AdvBench的恶意提示词数据集,以及AlpacaEval和VicunaEval等数据集用于评估模型的正常响应性能。
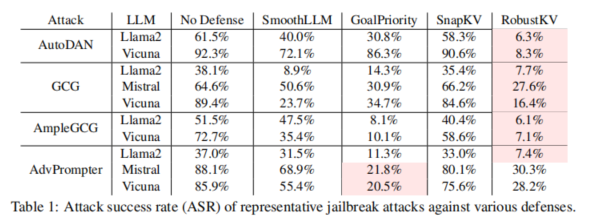
防御有效性:结果表明,RobustKV在抑制AutoDAN、GCG等攻击中的成功率上显著优于现有的防御方法,尤其在面对较强的安全防护时(如Llama2),更能有效压制恶意查询。同时,与现有的KV逐出方法相比,RobustKV表现出了更高的越狱防御效率。
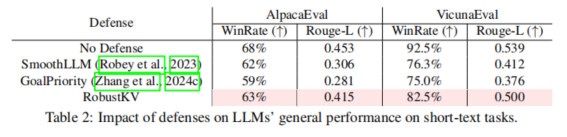
LLM UTILITY:在评估对正常响应的影响时,RobustKV较其他防御措施更能保持模型性能,表现在AlpacaEval和VicunaEval数据集上的得分均接近未防御状态下的模型。
论文结论
RobustKV提供了一种创新的越狱攻击防御手段,通过在LLM的KV缓存中策略性地清除恶意查询相关标记,削弱了恶意查询的存在感,有效阻止了模型生成恶意响应。该方法不仅在性能上超越了现有的防御策略,还提出了对抗适应性攻击的有效手段,为进一步研究KV缓存优化与越狱防御相结合的方向提供了新视角。这项研究为LLM安全性的提升开辟了新的思路。