网络安全 - DOS
1.1.1 摘要
最近网络安全成了一个焦点,除了国内明文密码的安全事件,还有一件事是影响比较大的——Hash Collision DoS(通过Hash碰撞进行的拒绝式服务攻击),有恶意的人会通过这个安全漏洞让你的服务器运行巨慢无比,那他们是通过什么手段让服务器巨慢无比呢?我们如何防范DoS攻击呢?本文将给出详细的介绍。
1.1.2 正文
在介绍Hash Collision DoS攻击之前,首先让我们复习一下哈希表(Hash table)。
哈希表(Hash table,也叫散列表),是根据关键码值(Key/Value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数(它的好坏将关系到系统的性能),存放记录的数组叫做哈希表。
大家知道哈希函数在计算哈希值时不可以避免地会出现哈希冲突。
假设我们定义了一个哈希函数hash(),m代表未经哈希计算的原始键,而h是m经过哈希函数hash()计算后得出的哈希值。
![]()
现在我们对原始键m1和m2进行哈希计算就可以获取相应的哈希值分别为:hash(m1)和hash(m2)。
![]()
如果原始键m1=m2,那么将可能得到相同的哈希值,但是键m1!=m2也可能得到相同的哈希值,那么就发生了哈希冲突(Hash collision),在大多数的情况下,哈希冲突只能尽可能地减少,而无法完全避免。
当发生哈希冲突时,我们可以使用冲突解决方法解决冲突,而主要的哈希冲突解决方法如下:
开放地址法
再哈希法
链地址法
建立一个公共溢出区
当发生哈希冲突时,我们的确可以采用以上的方法解决哈希冲突,但我们能不能尽可能避免哈希冲突的出现呢?如果哈希冲突被减少到微乎其微,那么我们系统性能将得到很大提高,我们通过使用冲突几率更低的算法计算哈希值。
一般情况衡量一种算法的好坏是通过它的最优,一般和最差情况的时空复杂度来衡量算法好坏的。
在理想情况下,哈希表插入、查找和删除一个元素操作的时间复杂度都为O(1),那么插入、查找和删除n个元素的时间复杂度就为O(n),任何一个数据项可以在一个与哈希表长度无关的时间内计算出一个哈希值(Key),然后根据哈希值(Key)定位到哈希表中的一个槽中(术语bucket,表示哈希表中的一个位置)。最理想情况是我们在长度为n的哈希表中插入n个元素,而且经过哈希计算后它们的哈希值恰好均匀地分配到哈希表的每个槽中完全没有冲突,这的确太理想了。但这不符合实际情况,由于我们无法预知插入元素的个数,而且哈希表的长度也是有限的,所以说哈希冲突是无法避免的。

图1 哈希表时间复杂度
碰撞解决大体有两种思路,第一种策略是根据某种原则将被碰撞数据定为到其它槽中,例如开放地址法的线性探索,如果数据在插入时发生了碰撞,则顺序查找这个槽后面的槽,将其放入第一个没有被占有的槽中;第二种策略是每个槽不只是只能容纳一个数据项的位置,而是一个可容纳多个数据项的数据结构(例如链表或红黑树),所有碰撞的数据以某种数据结构的形式组织起来(线性探索:di = 1,2,3,…,m – 1)。
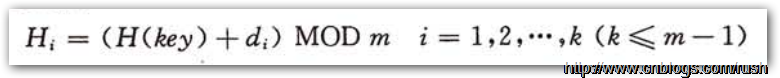
图2 开放地址法
不论使用哪种碰撞解决策略,都导致插入、查找和删除的操作的时间复杂度不再是O(1)。以查找为例:不能通过哈希值(Key)定位到槽就结束,还需要比较原始键(即未经过哈希的Key)是否相等,如果不相等,则使用与插入相同的算法继续查找,直到找到匹配的值或确认数据不在哈希表中。
.NET是使用第一种策略解决哈希冲突,它根据某种原则将碰撞数据定位到其他槽中。
而PHP是使用单链表存储碰撞的数据,因此实际上PHP哈希表的平均查找复杂度为O(L),其中L为桶链表的平均长度;而最坏复杂度为O(N),此时所有数据全部碰撞,哈希表退化成单链表。下图是PHP中正常哈希表和退化哈希表的示意图。
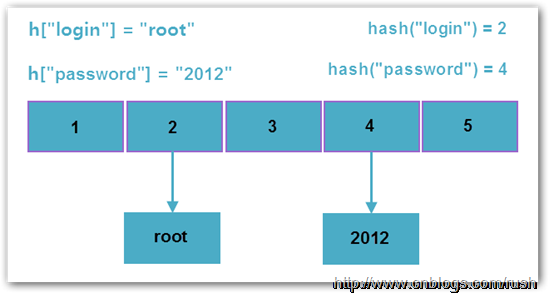
图3 正常哈希表
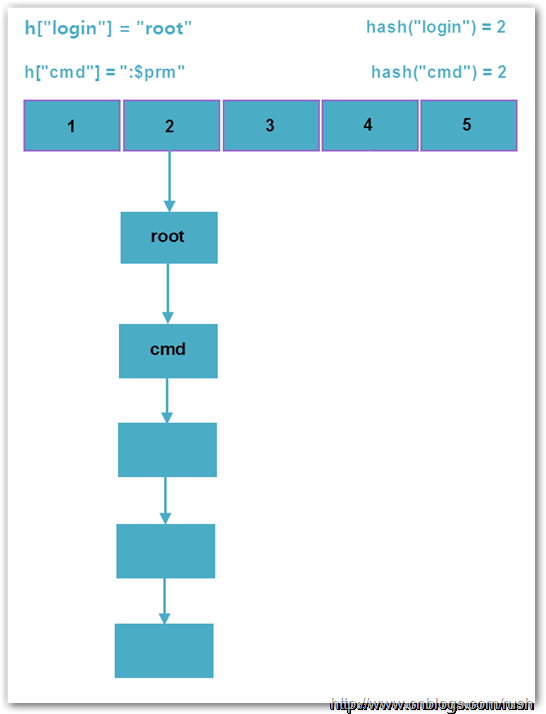
图4 退化哈希表
通过上图正常哈希表我们发现在正常情况下,哈希值分配的均匀冲突几率很低,而退化的哈希表中全部数据都在同一个槽上发生了冲突,这将导致数据插入、查找和删除的时间复杂度变为O(n2),由于时间复杂度提升了一个数量级,因此会消耗大量CPU资源,导致系统无法及时响应请求,从而达到拒绝服务攻击(DoS)的目的。
.NET中哈希表的实现
数据结构
在.NET中定义一个结构体bucket来表示槽,它只包含三个字段,具体代码如下:
/// <summary>
/// Defines hash bucket.
/// </summary>
private struct bucket
{
/// <summary>
/// The hask key.
/// </summary>
public object key;
/// <summary>
/// The data value.
/// </summary>
public object val;
/// <summary>
/// The key has hash collision.
/// </summary>
public int hash_coll;
}
当发生冲突时,线性探索再散列在处理的过程中容易产生记录的二次聚集,而.NET通过使用再哈希和动态增加哈希表长度来减少再发生哈希冲突。
/// <summary>
/// Rehashes the specified newsize.
/// </summary>
/// <param name="newsize">The newsize.</param>
private void rehash(int newsize)
{
this.occupancy = 0;
// Creates a new bucket.
Hashtable.bucket[] newBuckets = new Hashtable.bucket[newsize];
for (int i = 0; i < this.buckets.Length; i++)
{
Hashtable.bucket bucket = this.buckets[i];
if ((bucket.key != null) && (bucket.key != this.buckets))
{
this.putEntry(newBuckets, bucket.key, bucket.val, bucket.hash_coll & 0x7fffffff);
}
}
Thread.BeginCriticalRegion();
this.isWriterInProgress = true;
// Changes the bucket.
this.buckets = newBuckets;
this.loadsize = (int)(this.loadFactor * newsize);
this.UpdateVersion();
this.isWriterInProgress = false;
Thread.EndCriticalRegion();
}
通过上面的rehash()方法我们知道当发生冲突时,.NET通过再哈希和增大哈希表的长度来避免再发生冲突。
哈希算法
现在让我们看看.NET使用什么哈希算法,查看Object.GetHashCode()方法,具体代码如下:
public virtual int GetHashCode()
{
return InternalGetHashCode(this);
}
我们发现Object.GetHashCode()方法调用了另一个方法InternalGetHashCode(),我们进一步查看InternalGetHashCode()方法,发现它映射到CLR中的一个方法ObjectNative::GetHashCode,具体实现代码如下:
FCIMPL1(INT32, ObjectNative::GetHashCode, Object* obj) {
CONTRACTL
{
THROWS;
DISABLED(GC_NOTRIGGER);
INJECT_FAULT(FCThrow(kOutOfMemoryException););
MODE_COOPERATIVE;
SO_TOLERANT;
}
CONTRACTL_END;
VALIDATEOBJECTREF(obj);
DWORD idx = 0;
if (obj == 0)
return 0;
OBJECTREF objRef(obj);
HELPER_METHOD_FRAME_BEGIN_RET_1(objRef); // Set up a frame
// Invokes another method to create hash code.
idx = GetHashCodeEx(OBJECTREFToObject(objRef));
HELPER_METHOD_FRAME_END();
return idx;
}
FCIMPLEND
该方法的实现并不复杂,但我们很快就发现其实该方法里再调用GetHashCodeEx()方法,它才是具体的哈希算法的实现,这里就不做详细的介绍因为实现代码很长
现在主流编程语言都采用的哈希算法是DJB(DJBX33A),而.NET中的NameValueCollection.GetHashCode()方法就是使用DJB算法。
DJB的算法实现核心是通过给哈希值(Key)乘以33(即左移5位再加上哈希值)计算哈希值,接下来让我们看一下DJB算法的实现吧!
/// <summary>
/// Uses DJBX33X hash function to hash the specified value.
/// </summary>
/// <param name="value">The value.</param>
/// <returns>The hash string</returns>
public static uint DJBHash(string value)
{
if (string.IsNullOrEmpty(value))
{
throw new ArgumentNullException("The hash value can't be empty.");
}
uint hash = 5381;
for (int i = 0; i < value.Length; i++)
{
// The value of ((hash << 5) + hash) the same as
// the value of hash * 33.
hash = ((hash << 5) + hash) + value[i];
}
}
我们看到DJB算法实现十分简单,但它却是十分优秀的哈希算法,它生成的哈希值冲突几率很低,接下来让我们看一下.NET中String.GetHashCode()方法的实现——DEK算法。
/// <summary>
/// Returns a hash code for this instance.
/// </summary>
/// <returns>
/// A hash code for this instance, suitable for use in hashing algorithms
/// and data structures like a hash table.
/// </returns>
public override unsafe int GetHashCode()
{
// Pins the heap address, so GC can't collect it.
fixed (char* str = ((char*)this))
{
char* chPtr = str;
int num = 0x15051505;
int num2 = num;
int* numPtr = (int*)chPtr;
for (int i = this.Length; i > 0; i -= 4)
{
// Uses DEK to generate hash code.
num = (((num << 5) + num) + (num >> 0x1b)) ^ numPtr[0];
if (i <= 2)
{
break;
}
// Uses DEK to generate hash code.
num2 = (((num2 << 5) + num2) + (num2 >> 0x1b)) ^ numPtr[1];
numPtr += 2;
}
return (num + (num2 * 0x5d588b65));
}
}
String类中重写了GetHashCode()方法,由于GetHashCode()会涉及到一些指针操作,所以把该方法定义为unsafe表示不安全上下文,也许有人会奇怪C#中还能像C/C++中的指针操作吗?我们要在C#中使用指针操作,这时fixed关键字终于派上用场了。fixed 关键字是用来pin住一个引用地址的,因为我们知道CLR的垃圾收集器会改变某些对象的地址,因此在改变地址之后指向那些对象的引用就要随之改变。这种改变是对于程序员来说是无意识的,因此在指针操作中是不允许的。否则,我们之前已经保留下的地址,在GC后就无法找到我们所需要的对象
哈希碰撞攻击
通过前面介绍.NET中GetHashCode()方法,现在我们对于其中的实现算法有了初步的了解,由于哈希冲突的原理就是针对具体的哈希算法来构造数据,使得所有数据都发生碰撞。
但如何构造数据呢?首先让我们看一个例子,假设我们往一个类型为NameValueCollection的对象中插入数据。
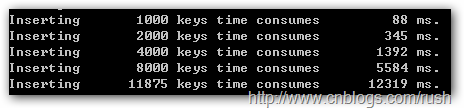
图5 插入数据
通过上图我们发现插入1000个数据只需88 ms,当插入2000个数据需时345 ms,随着插入数据规模的增大我们发现插入时间越来越长,哈希表的插入时间复杂度不是O(n)吗?大家肯定知道这是由于发生哈希冲突导致时间复杂度无法达到线性。
这里我们使用了一个简单方法构造冲突数据——蛮力法。(效率低)
由于蛮力法效率低,所以我们采用更加高效的方法中途相遇攻击(meet-in-the-middle attack)或等效子串(equivalent substrings)来构造冲突数据。
等效子串:
如果哈希函数具有这样的特性,当两个字符串的哈希值发生冲突,例如:hash(“string1”)=hash(“string2”),那么由这两个子串在同一位置上构成的字符串也发生哈希冲突,例如:hash(“prefixstring1postfix”)=hash(“prefixstring2postfix”)。
假设“EZ”和“FY”在哈希函数中发生冲突,那么字符串“EzEz”,“EzFY”,“FYEz”,“FYFY”两两之间也发生冲突。大家想查看使用等效子串的例子点这里。
中途相遇攻击:
如果在一个给定的哈希函数中不存在等效子串,那么蛮力法似乎是唯一的解决办法了。但我们前面介绍蛮力法效率低,明显的以32位为例这种方式命中目标的概率是1 /(2 ^ 32)。
现在我们只需计算16位哈希值,那么命中目标的概率是1/(2^16),这样命中几率大大的提高了,而且构造数据时间也缩短了。
我们使用等效子串方法把字符串分成两部分,前缀子串(长度为n)和后缀子串(长度为m),接着我们枚举前缀子串的哈希值,并且使得它们的哈希值相等。

现在我们通过异或运算使得枚举前缀子串的哈希值都相等,首先我们让前缀子串乘以1041204193再经过DJB33计算哈希值。也许有人会问为什么要乘以1041204193呢?
由于1041204193 * 33 = 34359738369
二进制值:00000000000000000000000000000000001(使用Int32)
我们知道1041204193 * 33 = 1,那么现在的前缀子串的哈希值只与它的字符相关,这将导致冲突几率增大了。
HashBack()方法的示意代码如下:
/// <summary>
/// The hash back function.
/// </summary>
/// <param name="tmp">The string need to hash back.</param>
/// <param name="end">The hash back value.</param>
/// <returns>The hash back string.</returns>
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
private static unsafe int HashBack(string tmp, int end)
{
int hash = end;
fixed (char* str = tmp)
{
char* suffix = str;
int length = tmp.Length;
for (; length > 0; length -= 1)
{
hash = (hash ^ suffix[length - 1]) * 1041204193;
}
return hash;
}
}
我们看到HashBack()方法包含两个参数,一个是要计算哈希值的字符串,而另外一个就是最后发生冲突的哈希值。
接来下我们让实现DJB33哈希函数示意代码如下:
/// <summary>
/// The hash function with DJB33 algorithm.
/// </summary>
/// <param name="tmp">The string need to hash.</param>
/// <returns>The hash value.</returns>
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
private static unsafe int Hash(string tmp)
{
int hash = 5381;
fixed (char* str = tmp)
{
char* p = str;
int tmpLenght = tmp.Length;
for (; tmpLenght > 0; tmpLenght -= 1)
{
hash = ((hash << 5) + hash) ^ *p++;
}
return hash;
}
}
现在我们完成了HashBack()和Hash()方法,首先我们使用HashBack()方法计算出前缀子串的哈希值,然后再使用Hash()方法找出和前缀子串发生冲突的子串,最后把前缀和后缀拼接起来就构成了冲突字符串了。
也许大家听起来有点别扭,那么让我们通过具体的例子来说明吧!
假设我们找到前缀“BIS”,而且HashBack(“NBJ”) = 147958270,然后我们通过暴力方法找出了和前缀有冲突的后缀Hash(“SKF0FTG”) = 147958270,接着我们把它们拼接起来计算Hash(“NBJ” + “SKF0FTG”) = 6888888,我们看到拼接起来的字符串计数出来的哈希值是我们事先已经指定好的,所以我们可以通过这种方法不断构造冲突数据。
接着我们使用以上的冲突数据进行插入测试,一开始运行插入数据CPU的消耗就开始变得大了,曾经一度消耗到100%那时机器根本动不了,所以无法截图。
图7 哈希冲突测试
防御
限制CPU时间
这是最简单的方法可以减少此类攻击的影响,它通过减少CPU请求时间将被允许参加。对于PHP可以设置max_input_time参数值;在IIS(ASP.NET)中,可以通过设置“关机时间限制”值(默认90s)。
限制POST请求参数个数
本次微软推出的安全性更新是通过限制 ASP.NET处理 HTTP POST 请求時最多只能接受1000个参数个。
如果我们的Web应用程序需要接受超过1000个参数,可以通过设置WebConfig中MaxHttpCollectionKeys的值来修改最多限制数,具体设置如下:
<!--Setting Max Http post value--> <appSettings> <add key="aspnet:MaxHttpCollectionKeys" value="1001" /> </appSettings>
限制POST请求长度
使用随机的哈希算法
由于我们事先知道使用的哈希算法,所以构造冲突数据更加有针对性,但一旦才有随机哈希算法我们没有办法预知使用算法,所以冲突数据很难构造,但不幸的是许多主流的编程语言都是采用非随机哈希算法,除了Perl之外,像.NET,Java,Ruby,PHP和Python等都是采用非随机算法。
1.1.3 总结
本文通过引入哈希表,接着介绍哈希表的实现和发生哈希冲突时处理的方法,然后针对具体的哈希算法构造冲突数据(等效子串和中途相应),最后介绍该如何防御Hash Denial Of Service 攻击。
由于我们事先知道使用的哈希算法,所以构造冲突数据更加有针对性,所以通过使用随机哈希算法可以更加有效防御Hash Denial Of Service 攻击,估计许多语言将会重新设计它们的哈希函数。