基于python的长津湖评论数据分析与可视化,使用是svm情感分析建模
-
引言
-
研究背景及意义
-
上世纪初开始,中国电影就以自己独有的姿态登上了世界电影史的舞台。中国电影作为国家文化和思想观念的反映与延伸,能够增强文化自信,在文化输出方面有着极其重要的作用1[1]。 改革开放以来,随着生产力的提高,物质生活质量也随之提高,人们对精神的追求也随之提高,越来越多的人选择了电影作为自己的休闲方式,电影产业得到了飞速发展,中国电影迎来了越来越受观众青睐的黄金机遇期。在影片质量上下足功夫的人越来越多。 近年来,随着互联网的普及与应用,我国已全面进入互联网时代。据中国互联网络信息中心(CNNIC)在北京发布的第50期《中国互联网络发展状况统计报告》显示,截至2021年6月,我国网民规模为10.51亿,与2021年12月相比增长1919万,网民普及率为74.4%。2[2]。随着信息化水平的提高,网络技术已经渗透了人们的日常生活中,各种电影社区网站APP平台产生并产出大量的电影评论数据,人机交互也日益频繁,用户不仅仅是简单的接收和浏览信息,而是越来越喜欢在媒体平台上发表自己的看法。本文通过Python爬取用户对《长津湖》电影观影后发表的评论看法,对用户的情感进行分析。
-
国内外研究和发展现状
-
情感分析研究现状 近几年,不少情感分析研究者都投入到这个领域,而在具体领域中,关于机器学习的傲人成果也越来越多地吸引着大众的目光,其中,在机器学习处理文本类情感分析的领域中,该领域的一大创举是将词典引入到与机器学习相结合的情感分析任务中,以特征选择预处理的数据文本, 对于文中所写内容的感情趋向,在词典中已经不是单纯的以词为主了, 词性的情感趋向在包含面上有了较大的拓展,各种词性的研究已经在的方案性研究中引入到词典中, 对一些表情包也采取了一系列体现文字情感趋向的处理手段。深度学习还引入了情感分析的问题研究,传统的机器学习方法解决方案经过一系列的工作经验总结,已经取得了相对成熟的发展成果。 根据处理文本信息的细粒度不同,目前研究领域中常见的文本情感分析方法采用的研究手段也不尽相同。对不同的数据采取不同的处理方式,在监督方法和非监督方法上联合发力,均取得了较好的效果。
-
机器学习研究现状
近年来,越多越多的研究者投入到机器学习这个领域当中,并且取得了不俗的成绩。相关研究者在基于情感词典的情感分析研究任务工作中,首要解决的问题是标注情感表达的趋向性,即根据语义规则的预设,根据情感辞典中的词性表达,对词的情感表达进行进一步的解释、情感的评分,从而得出一系列文本的整体情感倾向。使用机器学习算法,结合传统的词袋法,可以促进二分类任务中分类效果的提高,提升算法的性能和准确性。利用TF-IDF 算法可以挖掘出文本数据的深层信息,对于目标领域文本情感分类精准度有一定的提高,为传统的机器学习二分类任务提供了新的解决思路。通过将数据规则化和SVM相结合的方法,来处理评论文本中的表情以及多义词的情感分类,大大提升了在文本语义预测的准确率。
-
本文主要研究内容
-
随着经济的发展,中国文化领域不断发展,尤其是电影行业。各类平台层出不穷的不断涌现,获取电影评论数据唾手可得,然后大量无规则文本甚至带有表情的文本数据的出现,使得情感趋向产生一定的误差。 以《长津湖》为例,本文通过影评数据反映电影《长津湖》的口碑以及影响热度,结合SnowNLP库和算法训练出可以识别影评情绪倾向的模型,对没有评分数据的影评进行情绪倾向推测。
-
本文的组织结构
论文共有六个章节,结构安排如下。
第1章引言部分,介绍一下这篇文章的背景、目的以及考察的内容。
第2章对可能会用到的技术进行了概括性的描述,首先回顾了爬虫的基本理论,描述了网页的构成;其次对于情感分析和文本分词进行技术介绍。
第3章主要介绍了对数据集的爬取以及预处理相关工作。
第4章主要介绍前端框架,通过可视化分析初步处理的数据,并结合Echarts和Flask绘制相关图表,达到更直观地感受数据的目的。
第5章首先对数据的词向量方法做出介绍,再将数据集划分成训练集和测试集。其次,分别在CountVectorizer和TfidfVectorizer两种不同的词向量方式下,基于SVM构建出SVC模型进行模型训练,最后进行性能分析。
第6章分为两个部分,首先是总结篇,这个部分主要是总结归纳这个项目的工作,最后是展望,针对工作中的不足,指出可以改进的地方,以及下一步可以开展的研究方向。
-
相关方法理论介绍
本章将介绍本文的相关方法理论。共有两个方面,一个是爬虫原理,本部分包括对爬虫基本原理与相关页面爬取的分析方法的介绍;另一个是情感分析的介绍。
-
爬虫
爬虫,又名网络爬虫,就是能够自动访问互联网并将网络内容下载下来的程序,它也是搜索引擎的根基,最具代表性的就是两大搜索引擎Google和Baidu,都是将海量数据存储下载到云端,通过强大的网络爬虫提供给用户高质量的搜索服务。
-
爬虫基本原理
为了进一步了解爬虫基本原理,首先先介绍一下网页的基本结构。基本的网页是由HTML、CSS、JavaScript三部分构成的。HTML也叫超文本标记语言。通过HTML标签描述网页的文字、图片、声音等内容,用相应的HTML标签标记网页需要定义哪些内容。HTML语言发展至今,已然经历了6个版本,目前主流的版本是HTML5,只是由于人们的习惯,仍然称为HTML。CSS通常被称为CSS风格或样式表,主要是为了在HTML页面中设置文字内容(字体,尺寸,对齐方式等),图片的形状(宽度和高度,边框风格,边距等),以及提供丰富功能的外观显示风格,例如版面的布局。JavaScript是Web页面中的脚本语言,静态页面可以通过JavaScript转化为动态页面,支持用户交互,并对相应的事件做出反应3[3]。简单来说HTML就是人的骨架,CSS就是人穿在身上的衣服,而JavaScript就是人的行为。
爬虫可以概括为四个环节:分析网页结构,获取网页源码,提取数据,数据持久化。爬虫第一步是分析网页的结构,如果是静态网页,就直接将网页的源代码获取下来。Python中为用户提供了许多的库,如urllib、requests库等,利用此等功能的库,可向网站的服务器发送请求,得到相应的HTML代码。如果是动态网页,这个时候的HTML网页只是提供内容展示的一个框架,相应的数据是由JavaScript脚本加载出来的。这个时候我们可以通过抓包的方式,将动态加载的后台数据的网址找到,加以规律的查找并封装相应的参数请求页面将数据提取。当然Python也提供了Selenium 库,这是一个基于浏览器运行的库,对爬取JavaScript动态渲染的页面是非常有效的。爬虫第二步是获取网页源码,通过上述的网页分析之后我们可以获取到相应的网页源码。接下来进行第三步,提取数据。Python提供了re、Xpath、Beautiful Soup等数据解析库。提取数据的方法有多种,可以根据网页的结构挑选适合该网站的提取方式。爬虫的最后一步是数据持久化。持久化的形式多种多样,我们可以根据数据最终的使用方式存储成想应的格式,如json、txt、csv、xlsx等,也可以存储到数据库中,如Mysql、MongoDb、Redis等。
-
情感分析
-
情感分析介绍 情感分析也称为意见挖掘,它是利用计算机技术对文本的观点、情感倾向进行挖掘与分析,并利用人工智能的神经网络模型对文本情感倾向进行分类判定4[4]。情感分析主要有两类,一类是以字典为基础的感情分类法,如图2-1所示,另一类是以机器学习算法原理为基础的感情分类法,如图2-2所示。

添加图片注释,不超过 140 字(可选)
图2-1 基于情感词典的情感分析流程

添加图片注释,不超过 140 字(可选)
图2-2 基于机器学习的情感分析流程
-
中文分词
中文分词是指按照一定规范将连续的字序重新组合成词语序列的过程,分词是将一个汉字序列分割成一个单独的词语。其本质就是划分词的边界。由于中文不像英文一样存在空格边界,且汉语博大精深,不同的词组在一起便有不同的含义。当中文发生歧义就会产生不同的语义,也就会出现不同的切割方式5[5]。在一定程度上就会对分词造成影响。所以在进行机器学习之前,首先要最大限度的完成分词操作,确保词性标注的准确性,才能得到好的模型。
-
本章小结
该章节对爬取网页数据和情感分析可能会用到的技术进行了概括性介绍,首先是对爬虫技术的详细介绍,其次是对情感分词、中文分词和词向量化的介绍,以备后续章节使用。
-
数据采集及预处理
本章主要介绍了软硬件环境、数据采集及数据清洗的方法。首先是使用Python对网页数据进行爬取,再通过Pandas库对数据进行清洗。
-
软硬件环境 操作系统:Windows 11 家庭中文版22000.1098(MP276JKV)X64; 开发平台:PyCharm Community Edition 2022.2.1; 第三方库:jieba,wordcloud,requests; 额外补充:Echarts中国地图包,Echarts; 处理器:AMD Ryzen 5 5600U with Radeon Graphics 2.30 GHz 内存:16GB。
-
数据采集
图3-1 数据采集流程图
-
第一阶段爬取
-
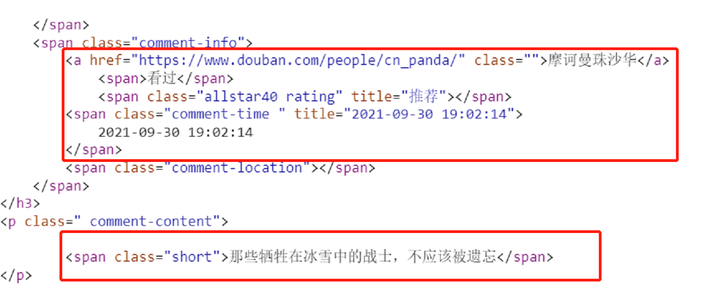
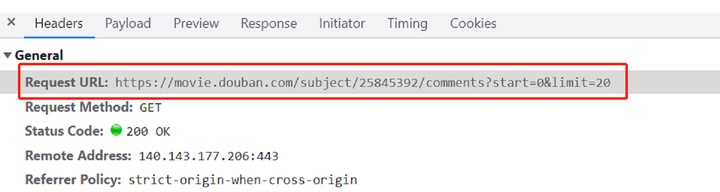
由图3-2所示,网页数据是直接渲染在HTML页面上的,通过requests模块即可抓取页面数据,通过图3-3对比可以发现,起决定性因素的参数是start 和 limit ,因此可以根据规律进行多页爬取,如图3-4所示。
添加图片注释,不超过 140 字(可选)
图3-2 网页结构分析
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
图3-3 网页请求分析

添加图片注释,不超过 140 字(可选)
图3-4 网页请求构造
-
参数说明(username:用户名 score:评分 time:发表评论的时间 comment:评论内容),根据图3-5所示,构建页面采集数据代码,结果如图3-6所示,并将数据持久化存储,内容如图3-7所示。

添加图片注释,不超过 140 字(可选)
图3-5 数据采集

添加图片注释,不超过 140 字(可选)
图3-6 控制台输出

添加图片注释,不超过 140 字(可选)
图3-7 采集结果
-
第二阶段爬取
-
通过图3-8分析发现该网站数据存储在json格式的数据集里面,通过图3-9,图3-10,图3-11对比两次JavaScript请求发现前一个数据集的最后一个id 是作为下一个请求页的参数,因此我们可以根据此规律构建多页的数据爬取的链接,如图3-12所示。

添加图片注释,不超过 140 字(可选)
图3-8 数据存放格式

添加图片注释,不超过 140 字(可选)
图3-8 数据存放格式

添加图片注释,不超过 140 字(可选)
图3-10 请求头参数规律1

添加图片注释,不超过 140 字(可选)
图3-11 请求头参数规律2

添加图片注释,不超过 140 字(可选)
图3-12 请求页逻辑构建
-
参数说明(uname:用户名 location:地区 addTime:发表评论的时间 content:评论内容),如图3-13所示,构建具体数据的采集逻辑过程,结果如图3-14所示,将数据持久化存储,结果如图3-15所示。

添加图片注释,不超过 140 字(可选)
图3-13 采集页面逻辑构造

添加图片注释,不超过 140 字(可选)
图3-14 控制台结果

添加图片注释,不超过 140 字(可选)
图3-15 采集结果
-
数据清洗 在进入分析之前,我们对数据文本进行了数据预处理,对空值项进行删除,对重复项进行去重,对包含表情的数据项不做处理,由于包含表情的数据项在情感分析时情绪分始终只有0.5,对模型影响不大,由于数据只做了去重和去空值操作,故此处不再过多赘述,将处理完的数据重新写入文件,部分结果如图3-16所示。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
图3-16部分数据展示
-
本章小结
该章节详细介绍了数据爬取的过程,在爬取过程中已经对数据做了初步预处理,并将时间戳的格式在爬取过程中转换为标准格式,便于日期排序。这便导致数据清洗只能做去重和去空的操作。
-
数据可视化
本章主要介绍数据可视化时使用到的框架Flask和组件Echarts的介绍,并展示相关生成的图表。
-
Flask介绍 Flask是一个轻量级的Web应用框架,由Python编写,Flask框架非常灵活,Flask只是完成了WerkZeug和模板引擎Jinja2的基本核心功能,它可以很好地结合MVC模式进行开发,可以在短时间内完成功能丰富的中小型网站或Web服务的网站的实现,其他的功能都是由第三方插件完成6[6],Flask的工作流程图如图4-1所示。

添加图片注释,不超过 140 字(可选)
图4-1 Flask工作流程图
-
Echarts介绍 Echarts,是一款能够在PC和移动设备上流畅运行、兼容绝大多数浏览器、底层依赖轻量级Canvas类库Zrender的纯JavaScript图表库,提供直观、生动、可交互、可高度个性化定制的数据可视化图表。能够支持折线图、柱状图、散点图、K线图、饼图、雷达图、和线图、力导向布局图、地图、仪表盘、漏斗图、事件河流图等12类图表,同时提供标题,详情气泡、图例、值域、数据区域、时间轴、工具箱等7个可交互组件,支持多图表、组件的联动和混搭展现。7[7]
-
数据图表展示
-
使用极坐标统计数据集中的评分分布区域数 由图4-2和图4-3可以看出用户对《长津湖》这部电影的喜爱程度是很高的,这反映出了《长津湖》这部电影质量还是不错的。

添加图片注释,不超过 140 字(可选)
图4-2 评论分区区域数
-
使用圆环图统计正负向评论条数 由图4-3可以看出正向评论数据占比居多,这也侧面衬托出《长津湖》电影质量是有迹可循的。

添加图片注释,不超过 140 字(可选)
图4-3 正负样本条数
-
使用柱形图统计当天评论总数 根据图4-4《长津湖》观众评论数量与日期的时间关系的分布,这也电影票房发展趋势吻合。

添加图片注释,不超过 140 字(可选)
图4-4 每日评论条数
-
使用中国地图统计各地区发表的评论数 由图4-5可看出线上观影用户绝大部分分布在沿海地区。基本上每个区域都为《长津湖》的票房贡献出力量。

添加图片注释,不超过 140 字(可选)
图4-5 地区评论条数
-
使用饼图对评论高频词展示 由图4-6可看出《长津湖》的评论趋向是正向的,“好看”,“中国加油”等词可以看出《长津湖》影片制作是很好的,能够让观众感同身受。

添加图片注释,不超过 140 字(可选)
图4-6 评论词频统计
-
使用词云组件将用户评论数据可视化
最后使用WordCloud绘制词云提取影评中的关键词。如图4-7所示,观众根据画面认为这是“向英雄致敬”、“中国加油”、大大的“好看”等“非常感人的历史战争片”,同时也充分为其票房提供了强有力的保障。

添加图片注释,不超过 140 字(可选)
图4-7 词云图
-
本章小结
该章节对Flask框架和Echarts组件做出详细介绍,并在Flask框架上搭建一个简易网站供可视化组件存放,由于Flask框架使用方便、简单,此处只对图表做出呈现,不详细描述网站的搭建过程。
-
数据建模
-
数据预处理
-
数据的质量影响着模型的正确率,所以本文保留评论内容大于4的评论内容。如图5-1所示。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
图5-1 数据预处理图1
-
将原始数据中存在的空格,标点符号,数字等数据清除。如图5-2所示。

添加图片注释,不超过 140 字(可选)
图5-2 数据预处理图2
-
使用snownlp库中的SnowNLP方法对评论内容做情感倾向度评分。如图5-3所示。

添加图片注释,不超过 140 字(可选)
图5-3 数据预处理图3
-
根据SnowNLP生成的评分数据划分数据标签0和1。如图5-4所示。

添加图片注释,不超过 140 字(可选)
图5-4 数据预处理图4
-
特征选择
-
本文选用CountVectorizer 和 TfidfVectorizer 两种特征选择方法对文本特征进行提取。
-
CountVectorizer的作用是统计每一段文本中的每个单词出现的频率,经过统计后形成一个矩阵,每一行代表一个词频统计结果,构成一个词汇表。TfidfVectorizer 这个函数把词转换为向量,TF是词频,idf是逆文本频率, idf即是一个词的重要程度体现,越高越重要8[8]。
-
随机抽取数据集。如图5-5所示。

添加图片注释,不超过 140 字(可选)
图5-5 定义数据随机抽取方法
-
将随机抽取的数据集划分成训练集和测试集。如图5-6所示。

添加图片注释,不超过 140 字(可选)
图5-6 划分数据集
-
使用TfidfVectorizer函数对文本进行向量化,如图5-7所示。

添加图片注释,不超过 140 字(可选)
图5-7 文本向量化1
-
使用jieba库进行中文分词。如图5-8所示。

添加图片注释,不超过 140 字(可选)
图5-8 jieba中文分词
-
将分词的结果向量化。如图5-9所示。

添加图片注释,不超过 140 字(可选)
图5-9 文本向量化2
-
划分训练集数据和测试集数据。如图5-10所示。

添加图片注释,不超过 140 字(可选)
图5-10 划分数据集2
-
SVM模型
-
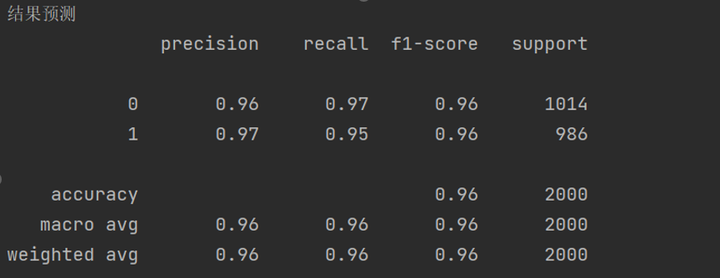
将TfidfVectorizer向量化的数据分为训练数据和测试数据加以训练,将模型结果绘制成ROC曲线和混淆矩阵,如图5-11、图5-12所示。
添加图片注释,不超过 140 字(可选)
图5-10 模型评分1

添加图片注释,不超过 140 字(可选)
图5-11 ROC曲线1

添加图片注释,不超过 140 字(可选)
图5-12 混淆矩阵1
-
将CountVectorizer向量化的数据分为训练数据和测试数据加以训练,将模型结果绘制成ROC曲线和混淆矩阵,如图5-14、图5-15所示。

添加图片注释,不超过 140 字(可选)
图5-13 模型评分2

添加图片注释,不超过 140 字(可选)
图5-14 ROC曲线2

添加图片注释,不超过 140 字(可选)
图5-15 混淆矩阵2
-
单条数据预测

添加图片注释,不超过 140 字(可选)
图5-16 差评数据预测

添加图片注释,不超过 140 字(可选)
图5-17 好评数据预测
-
实验结果分析
在此之前,我们有必要对SVM模型进行一番了解。支持向量机(SVM)模型是一个二分类模型。在文本分类、图像分类、生物序列分析和生物数据挖掘等领域都有广泛的应用,是被视为文本分类中效果较为优秀的一种算法9[9]。
两种词向量的数据在SVC模型的训练后,预测结果都在89以上,如图5-10、图5-13所示。TfidfVectorizer更为精准,CountVectorizer稍微差了一些,但两者都达到了预期目标。单条数据的预测值也符合预期,效果如图5-16、图5-17所示。
-
总结和展望
-
本文总结 随着我国经济的发展,文化领域不断发展,尤其是电影行业最为瞩目,中国电影不仅质量提升,种类繁多,观众对电影的选择也是多种多样,对于情感分析进行相关研究具有一定的现实意义。 《长津湖》作为一部投入了巨大资金的历史战争题材电影,在众多电影中脱颖而出,凭借着扣人心弦的内容打动了观众,在两个月的时间内取得了56亿的票房亮,成为中国爱国电影的新标杆。几大平台和推广方对其票房走势产生了重要的推动影响。本文以电影评论情感分析切入点分别用两种不同的词向量方法,在数据集方面将评论数据分为好评和差评,综合打乱之后划分训练集、测试集。之后基于SVM分别构建出两种不同词向量的方法对模型进行训练,两种方法在模型训练之后的准确率基本符合预期,最高准确率在96%左右,测试集也是在96%左右。
-
工作展望
本文在回顾了情感分析的相关技术后,在具体工作中,基本完成了数据采集、数据预处理、特征工程、数据可视化等处理工作,后续开展对SVM等模型建模以及试验工作,对于情感分析的工作流程、技术有了深刻的认知和理解。然而在性能上,仅凭现有的工作是远远不够的,只是提供了某种可行的方法,本文的相关工作仍有不足之处,希望在今后能进一步完善改进。