5分钟上手!用 #Workspace 为 screenshot-to-code 项目增加新功能
在之前的文章中,我们教过大家如何5分钟实现网站复刻,同时为大家介绍了 screenshot-to-code 这个开源项目,以及如何基于该项目增加调用 Gemini 模型,最终实现上传图片生成代码的效果。
当时就有不少小伙伴提出疑问,怎么快速找到需要修改的地方呢?
在此之前,我们要先花一些时间去了解阅读源码才能找到相关函数,但在今天,给大家介绍一个豆包MarsCode 的利器:#Workspace,有了它,妈妈再也不用担心我找不到修改函数的入口啦!

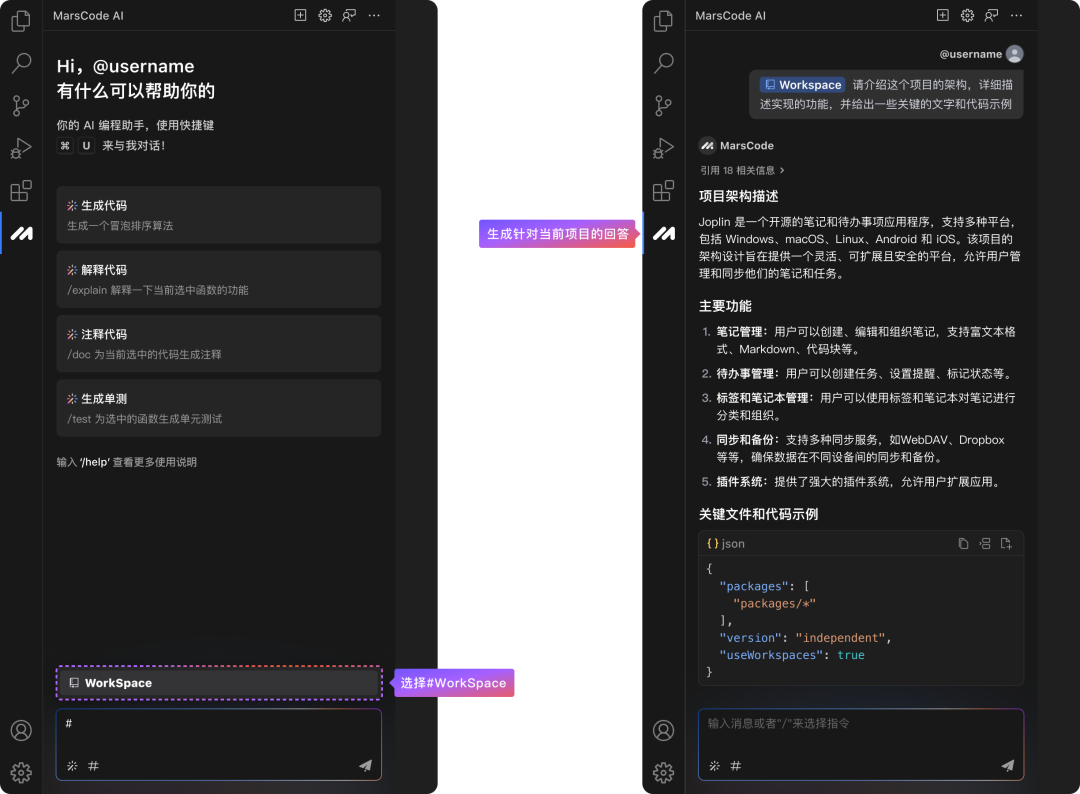
今天给大家演示一下,如何利用豆包MarsCode的 #Workspace 功能,快速上手修改开源项目!
在修改之前,需要首先了解并熟悉当前项目的模块和架构,我们可以使用豆包MarsCode #Workspace 功能,总结并输出模块的架构:

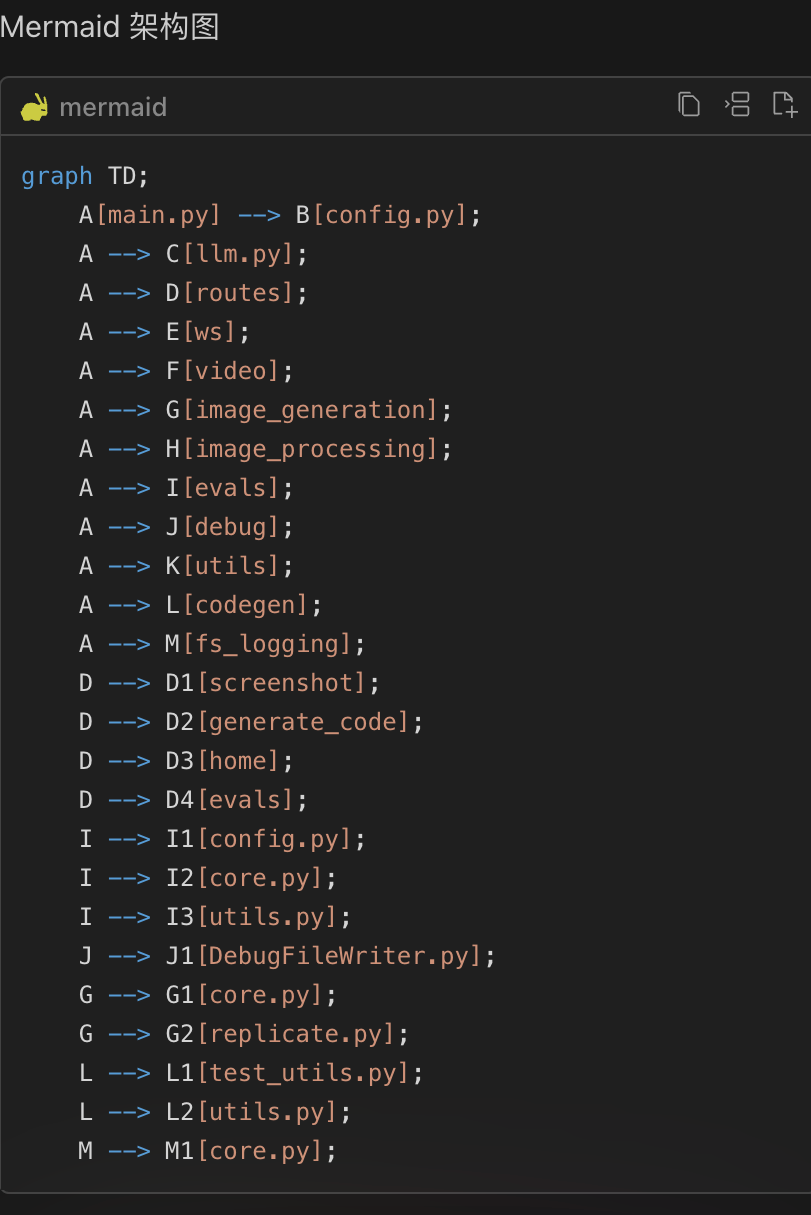
接着,我们可以把 #Workspace 输出的 mermaid 内容,贴到 mermaid 在线展示网站(https://sourl.cn/RUYGf4)上,就得到了 screenshot-to-code 项目的模块架构:

了解熟悉完架构后,接着使用 #Workspace 让豆包MarsCode告诉我们如何本地启动项目:
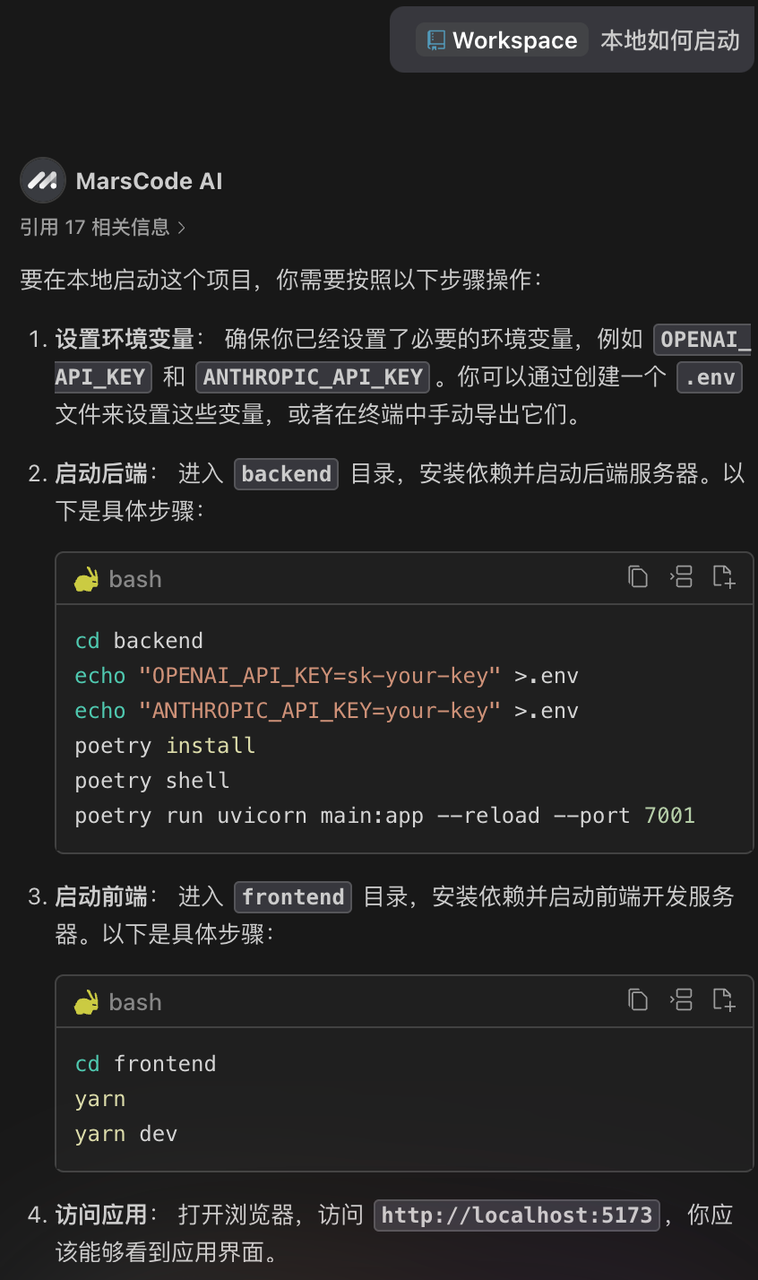
根据它给的方式,我们在终端内一步步执行,即可成功启动项目。
下一步,我们需要增加调用 Gemini 模型,但模块代码这么多,该怎么快速找到需要修改哪些地方呢?
这时我们再次使出 #Workspace 利器,可以看到豆包MarsCode精准地给出了我们要修改的地方:
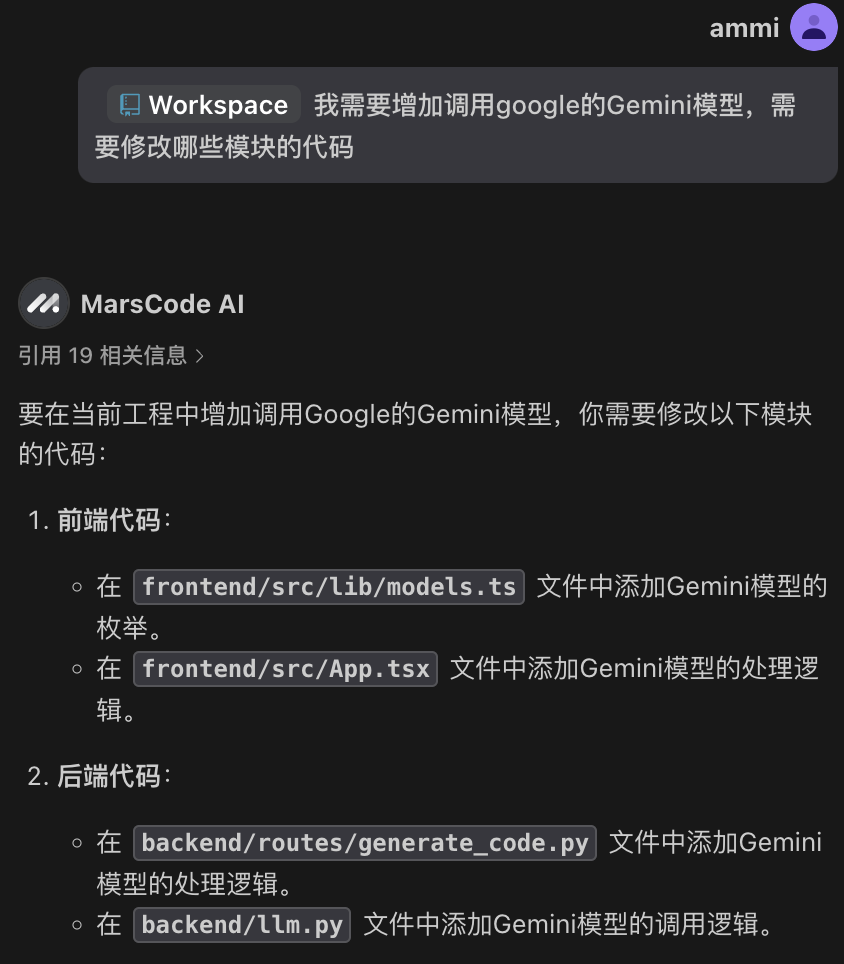
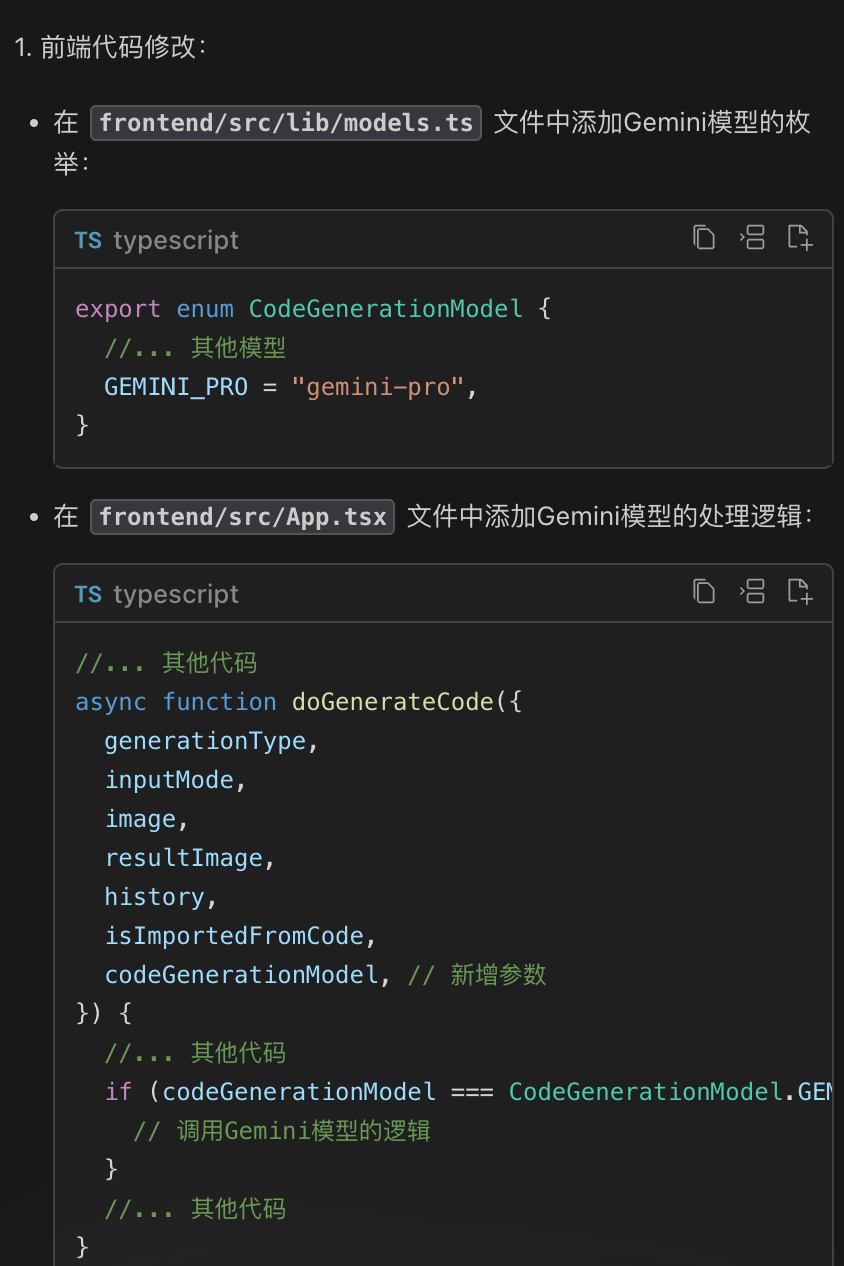
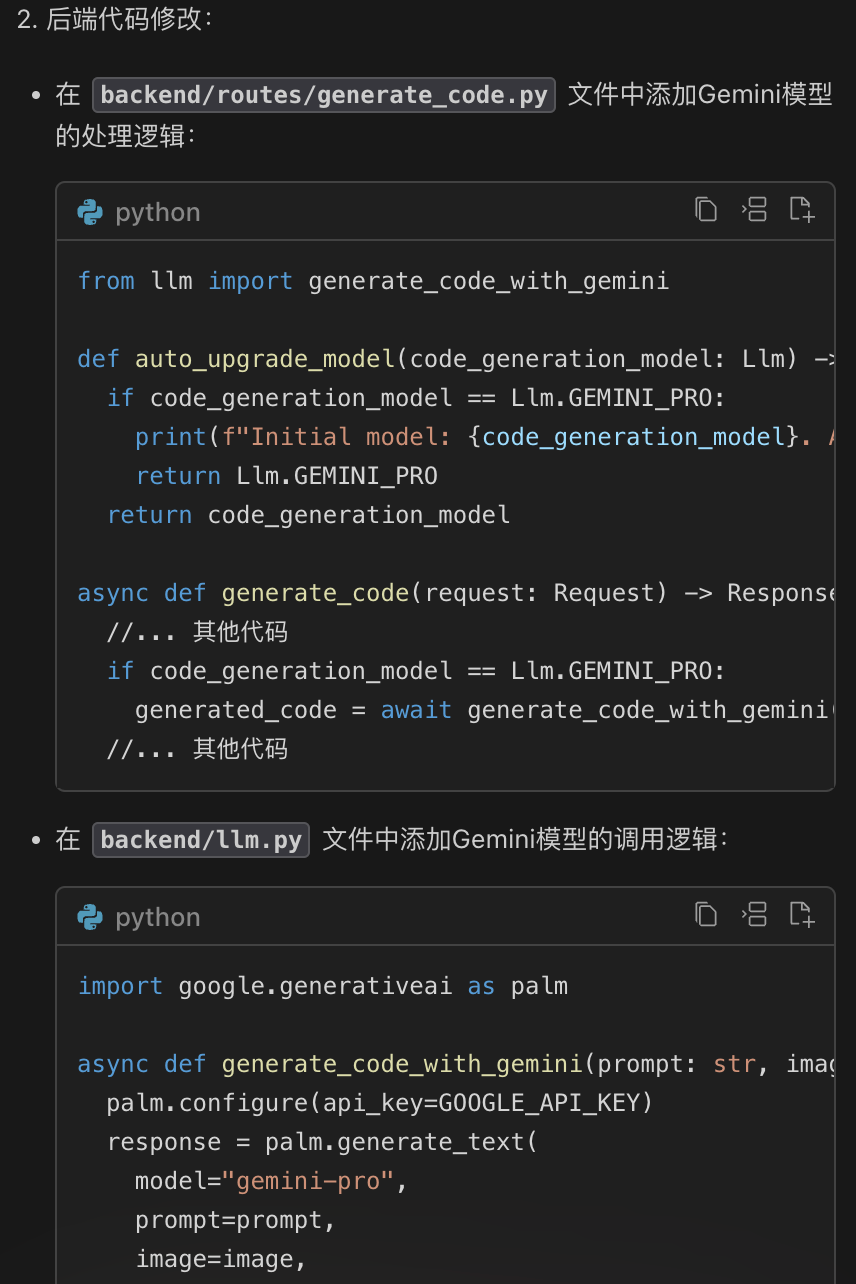
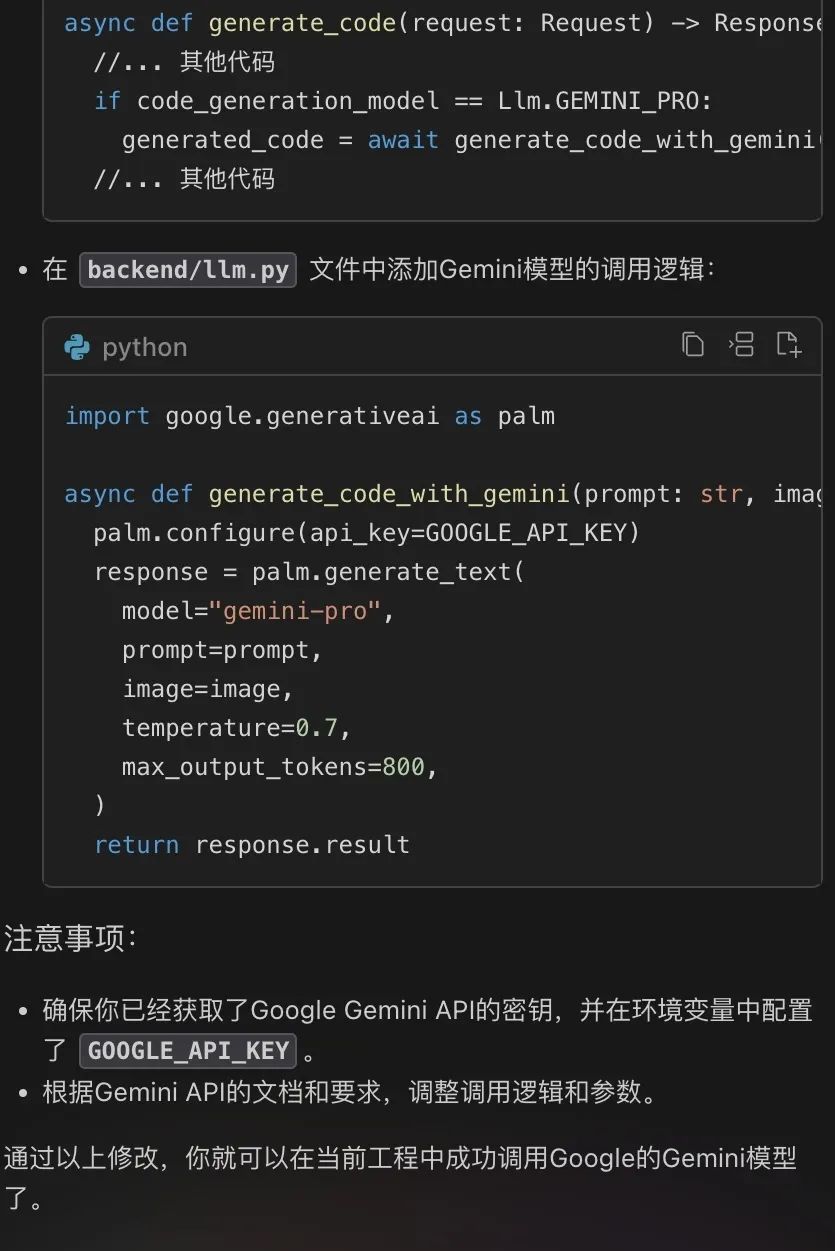
接下来,让我们按照豆包MarsCode给的教程,动手改起来。
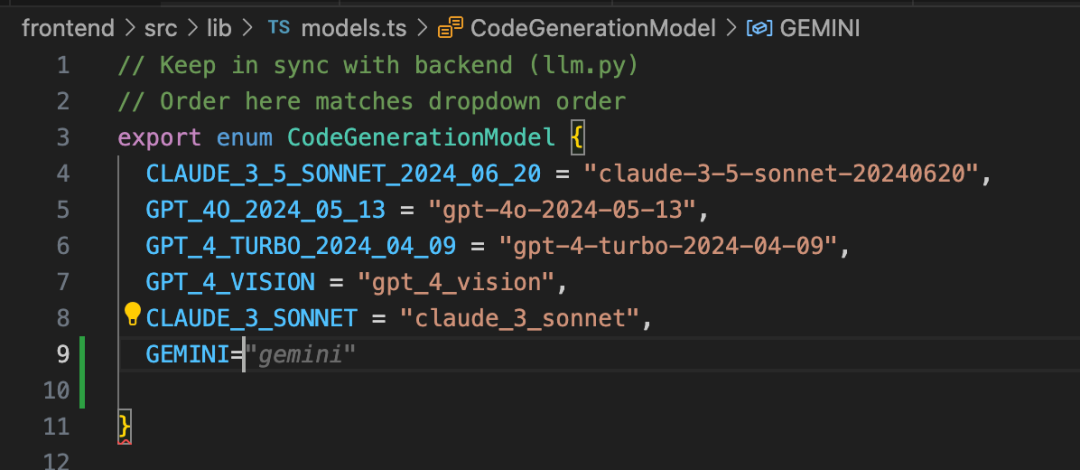
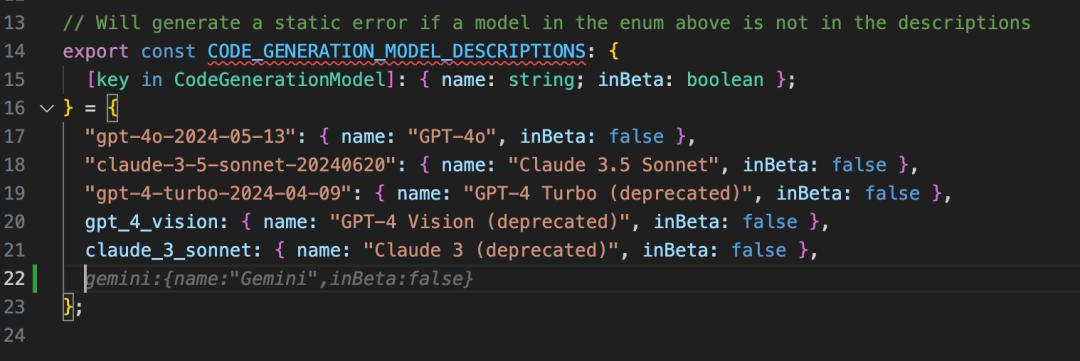
首先,我们需要打开 frontend/src/lib/models.ts 增加 Gemini 模型的枚举。当输入 GEMINI 之后,豆包MarsCode 自动为你推荐了补全代码,点击 Tab 键采纳即可。
紧接着,我们需要打开 frontend/src/App.tsx,找到修改入口:
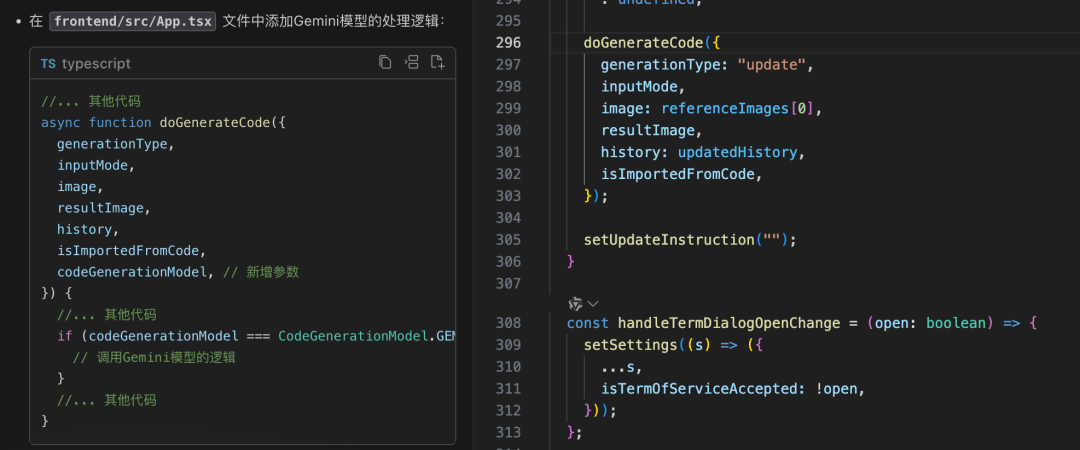
我们先拿豆包MarsCode 来解释一下这个函数的功能。

根据解释,该函数只是用于更新指令并生成代码,和我们要改的模型无关,我们忽略这个文件直接改后端代码。
后端部分主要修改 llm.py 和 generate_code.py 2个文件。根据前面的架构介绍,llm.py 负责调用 LLM,generate_code.py 则是生成代码的路由处理。因此我们需要先改 llm.py,增加调用 Gemini。
在这里,我们直接复制上次的代码,修改 llm.py:
class Llm(Enum):
GPT_4_VISION = "gpt-4-vision-preview"
GPT_4_TURBO_2024_04_09 = "gpt-4-turbo-2024-04-09"
GPT_4O_2024_05_13 = "gpt-4o-2024-05-13"
CLAUDE_3_SONNET = "claude-3-sonnet-20240229"
CLAUDE_3_OPUS = "claude-3-opus-20240229"
CLAUDE_3_HAIKU = "claude-3-haiku-20240307"
CLAUDE_3_5_SONNET_2024_06_20 = "claude-3-5-sonnet-20240620"
# 新增gemini
GEMINI_1_5_PRO_LATEST = "gemini-1.5-pro-latest"
async def stream_gemini_response(
messages: List[ChatCompletionMessageParam],
api_key: str,
callback: Callable[[str], Awaitable[None]],
) -> str:
genai.configure(api_key=api_key)
generation_config = genai.GenerationConfig(temperature=0.0)
model = genai.GenerativeModel(
model_name="gemini-1.5-pro-latest", generation_config=generation_config
)
contents = parse_openai_to_gemini_prompt(messages)
response = model.generate_content(
contents=contents,
# Support streaming
stream=True,
)
for chunk in response:
content = chunk.text or ""
await callback(content)
if not response:
raise Exception("No HTML response found in AI response")
else:
return response.text
def parse_openai_to_gemini_prompt(prompts):
messages = []
for prompt in prompts:
message = {}
message["role"] = prompt["role"]
if prompt["role"] == "system":
message["role"] = "user"
if prompt["role"] == "assistant":
message["role"] = "model"
message["parts"] = []
content = prompt["content"]
if isinstance(content, list):
for content in prompt["content"]:
part = {}
if content["type"] == "image_url":
base64 = content["image_url"]["url"]
part["inline_data"] = {
"data": base64.split(",")[1],
"mime_type": base64.split(";")[0].split(":")[1],
}
elif content["type"] == "text":
part["text"] = content["text"]
message["parts"].append(part)
else:
message["parts"] = [content]
messages.append(message)
return messages最后,我们再修改 generate_code.py,增加调用 Gemini 的函数:
if validated_input_mode == "video":
if not anthropic_api_key:
await throw_error(
"Video only works with Anthropic models. No Anthropic API key found. Please add the environment variable ANTHROPIC_API_KEY to backend/.env or in the settings dialog"
)
raise Exception("No Anthropic key")
completion = await stream_claude_response_native(
system_prompt=VIDEO_PROMPT,
messages=prompt_messages, # type: ignore
api_key=anthropic_api_key,
callback=lambda x: process_chunk(x),
model=Llm.CLAUDE_3_OPUS,
include_thinking=True,
)
exact_llm_version = Llm.CLAUDE_3_OPUS
elif (
code_generation_model == Llm.CLAUDE_3_SONNET
or code_generation_model == Llm.CLAUDE_3_5_SONNET_2024_06_20
):
if not anthropic_api_key:
await throw_error(
"No Anthropic API key found. Please add the environment variable ANTHROPIC_API_KEY to backend/.env or in the settings dialog"
)
raise Exception("No Anthropic key")
completion = await stream_claude_response(
prompt_messages, # type: ignore
api_key=anthropic_api_key,
callback=lambda x: process_chunk(x),
model=code_generation_model,
)
exact_llm_version = code_generation_model
# 增加调用gemini
elif (
code_generation_model == Llm.GEMINI_1_5_PRO_LATEST
):
if not GEMINI_API_KEY:
await throw_error(
"No GEMINI API key found. Please add the environment variable ANTHROPIC_API_KEY to backend/.env or in the settings dialog"
)
raise Exception("No GEMINI key")
completion = await stream_gemini_response(
prompt_messages, # type: ignore
api_key=GEMINI_API_KEY,
callback=lambda x: process_chunk(x),
)
exact_llm_version = code_generation_model
else:
completion = await stream_openai_response(
prompt_messages, # type: ignore
api_key=openai_api_key,
base_url=openai_base_url,
callback=lambda x: process_chunk(x),
model=code_generation_model,
)
exact_llm_version = code_generation_model经过以上几个步骤的修改,我们就完成了代码修改部分,最后我们再安装 google-generativeai 库:
cd backend
poetry add google-generativeai安装完库后,再次启动项目,就可以愉快地使用 Gemini 来生成代码啦,大家赶快去试试使用 #Workspace 吧!