数据分类问题-鸢尾花数据集
鸢尾花(Iris)简介
鸢尾花是一种常见的单子叶植物,属于百合目,常见于公园等地。由于其品种繁多,了解鸢尾花的种类识别数据集将有助于在社交场合中展示你的知识。
鸢尾花数据集的重要性
鸢尾花数据集是模式识别和机器学习领域中使用最广泛的数据集之一。许多教材和工具(如 R 和 scikit-learn)都内置了该数据集,学术界也有大量论文基于此数据进行实验,显示出其在研究中的重要性。
数据来源与背景
鸢尾花数据集最初由 Edgar Anderson 测量,并在著名统计学家和生物学家 R.A. Fisher 于 1936 年发表的文章《The use of multiple measurements in taxonomic problems》中被引用,作为线性判别分析的例子。这使得该数据集在机器学习领域广为人知。
数据集中两类鸢尾花的记录是在加拿大加斯帕半岛的同一天、同一时间段,由同一人使用相同的测量仪器在同一牧场测量而得。这份数据已有 70 年历史,尽管年代久远,但依然经典,详细数据集可在 UCI 数据库中找到。
数据集详情
鸢尾花数据集包含三类鸢尾花:Setosa、Versicolour 和 Virginica,每类各有 50 条样本记录,共计 150 条。数据集包括四个属性:
- 花萼长度
- 花萼宽度
- 花瓣长度
- 花瓣宽度
所有属性的单位均为厘米,且均为数值变量,数据中不存在缺失值。以下是各属性的统计信息:
| 属性 | 最大值 | 最小值 | 均值 | 方差 |
|---|---|---|---|---|
| 萼长 | 7.9 | 4.3 | 5.84 | 0.83 |
| 萼宽 | 4.4 | 2.0 | 3.05 | 0.43 |
| 瓣长 | 6.9 | 1.0 | 3.76 | 1.76 |
| 瓣宽 | 2.5 | 0.1 | 1.20 | 0.76 |
数据探索
在进行任何机器学习任务之前,了解数据集的基本情况至关重要。这包括数据的背景、量级、缺失值情况、数据类型及各属性的统计指标。常用的统计指标包括:
- 频率和众数:用于无序分类数据,众数为最高频率的值。
- 百分位数:针对有序数据,计算各属性的 10、25、50、75、90 等百分位数。
- 位置度量:如均值和中位数。
- 散布度量:使用极差和方差描述连续数据属性。可用绝对平均偏差、中位数绝对偏差和四分位数极差等指标来度量。
- 多元属性的散布度量:可独立计算各属性的散布度量,连续变量通常使用协方差表示。
数据探索不仅需要汇总统计,适当的可视化也能提供直观的信息。Python 提供了强大的工具来进行数据探索,使用 NumPy 进行统计计算,使用 Matplotlib 进行可视化。
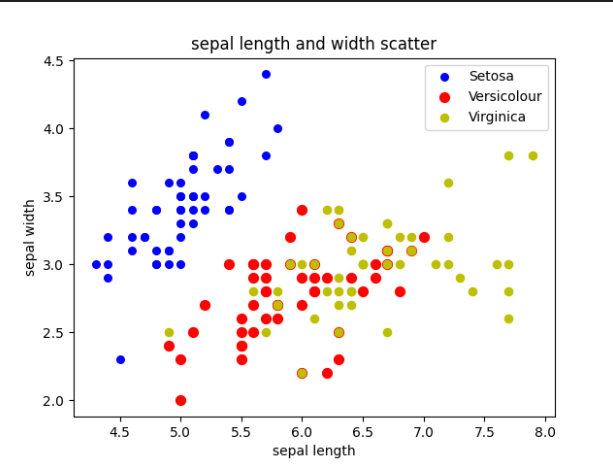
常见的可视化技术包括直方图、盒图、饼图、散点图和百分位数图。以下是萼长和萼宽属性的散点图示例:
需要按照一些依赖:
pip install matplotlib scikit-learn
from matplotlib import pyplot
from sklearn.datasets import load_iris
iris = load_iris()
setosa_sepal_len = iris.data[:50, 0]
setosa_sepal_width = iris.data[:50, 1]
versi_sepal_len = iris.data[50:100, 0]
versi_sepal_width = iris.data[50:100, 1]
vergi_sepal_len = iris.data[100:, 0]
vergi_sepal_width = iris.data[100:, 1]
pyplot.scatter(setosa_sepal_len, setosa_sepal_width, marker = 'o', c = 'b', s = 30, label = 'Setosa')
pyplot.scatter(versi_sepal_len, versi_sepal_width, marker = 'o', c = 'r', s = 50, label = 'Versicolour')
pyplot.scatter(vergi_sepal_len, vergi_sepal_width, marker = 'o', c = 'y', s = 35, label = 'Virginica')
pyplot.xlabel("sepal length") # 花萼长度 (cm)
pyplot.ylabel("sepal width") # 花萼宽度 (cm)
pyplot.title("sepal length and width scatter") # 花萼长度与宽度散点图
pyplot.legend(loc = "upper right")
pyplot.show()
可以绘制出鸢尾花的萼长和萼宽的散点图,帮助更好地理解数据的分布情况。