无需代理 调用OpenAI的大模型API接口(Python)
背景
虽然现在国内某些AI还是挺好用的,像kimi,豆包,效果都还不错,但是写复杂一点的代码或者是做深度一点的推理都很弱智........效果还是和国外的AI比不了,但是访问chatgpt很多人又不会找代理(这能难倒90%的中国人),并且去了 ,所以我这期教大家怎么无需梯子就使用国外的模型。
有的同学肯定会警觉,不会又是什么免费用几次后面再用就要充月费钱的套壳gpt吧.......当然不是,真正的API接口都是按量收费的,对话了多少字,多少token就收多少钱。而不是国内一堆套壳的gpt按次收费或者按照月收费。
所以本文带来的不是免费的使用接口,是需要按量收费的接口和使用。(但是很便宜,省着点,10块可以用半年的那种,而且也无需使用国外信用卡,zfb就可以)
并且API的接口是有很多参数可以调整的,以此来让模型输出不同效果的文字(更通用还是更有创意)。
所以本文带来的优势主要是如下几点:
-
无需代理就能使用openai最新模型,(还有Claude,谷歌的Gemini 都可以)
-
无需一次性支持高昂的会员月费,按量收费(10块可以用半年)
-
无论你是新手小白,需要直接使用类似官网的网页端的接口,还是有一定python基础的开发者,需要写入代码自动化调用大模型接口写脚本处理工作流,都能满足你。
准备
首先你需要来这个网站进行注册和登陆,名字叫:CloseAI
你可以从他们的平台简介中了解到,这是一家openai的亚洲代理:
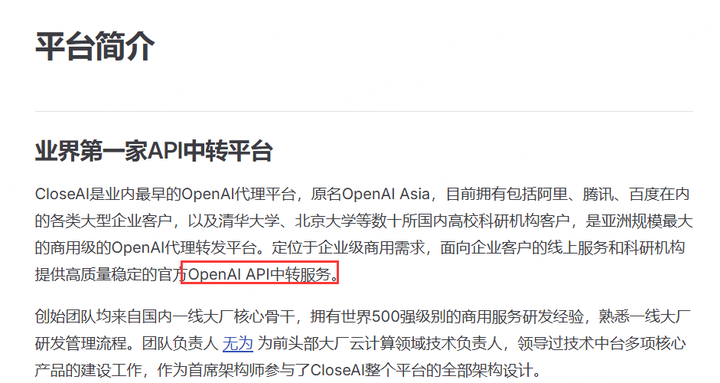
所以不用担心什么不正规和套壳,他们的使用 (网页端和代码接口API调用) 和openai官网几乎都是一样的,唯一区别在于不需要开代理,无需魔法上网就能访问。
最让大家关心的价格可以看看登陆之后的模型定价:
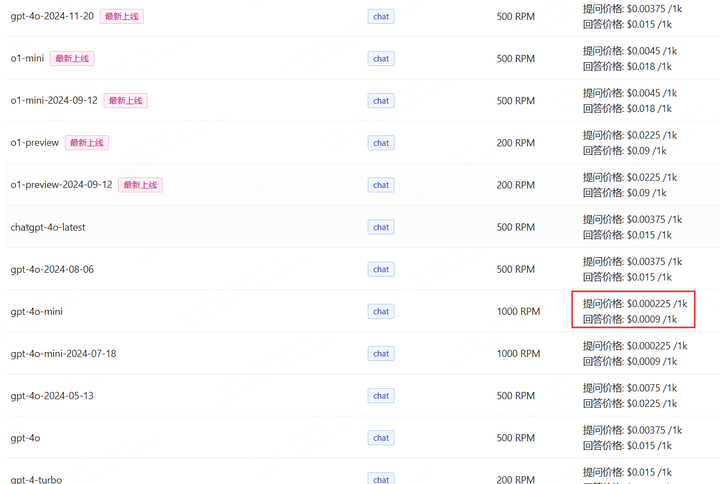
我对比了一下价格,比官网要贵一点,但是相对国内那种动不动10块钱100次的使用来比....还是便宜很多。现在没人用gpt3.5了。我拿最具性价比的gpt-4o-mini来说,0.0009美元输出1k的token,1K token大概是750个英文单词,500个中文汉字,假设我们对话一次就用了0.0009美元,汇率按照现在的7.25,一个月平均每天用20次(一般用不到,我天天写代码用gpt一天也用不了20次),那我一个月30天会花费的人民币为:
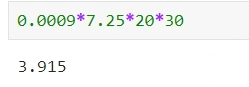
不到4块,并且根据我8个月天天上班写代码使用的经验,我总共使用了2k次,平均每天使用不超10次。所以我的花费是每个月不到2块,10块钱省着点用是不是可以用半年了?
当然,你想用更贵的o1模型和gpt4-turbo模型那肯定就要多花点钱了,对于日常的任务,4o-mini够用,很复杂的代码任务我才会启用o1模型,需要多模态进行图表分析我才会用gpt4-turbo。
在他们家进行账户充值之后,你有2种方法来使用你的token,一种是写代码来调用接口,还有一种是他们自己还原的openai的网页版:CloseChat
里面有各种大厂的各种模型和插件可以选择,一比一复刻了chatgpt官网。上传文件和图片进行分析,生成画作,基本都是一样的。无需代理访问,他们自称是国内体验最好的客户端。

当然,生成图片音频所花费的token肯定比文字高多了....要注意成本。
如果你是一个代码开发的小白,只想找一个国内能用gpt 的渠道,那么看到这里就可以停止了。
下面是针对python开发者如何在自己的代码和工作流中集成大模型的调用能力的代码演示。
你需要准备好你的api_key,这是用来表示你的账户的识别号码。
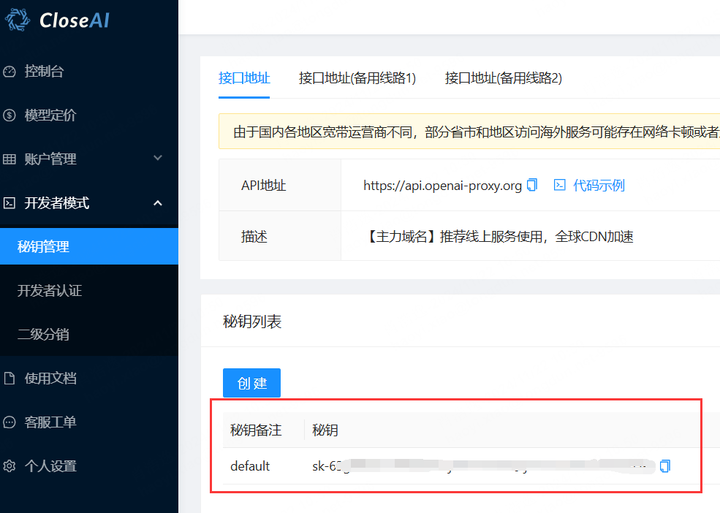
在下面的代码中,我会打码我的key。大家主需要在代码里面换成自己的就行。其他代码可以完全不变。
代码实现
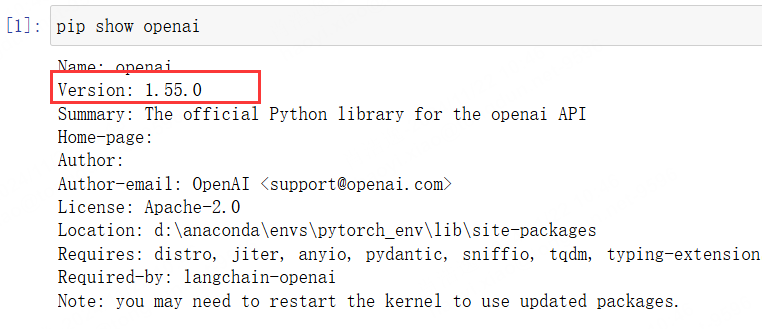
首先你需要安装openai的包:
pip install openai 注意版本,一般来说都是最新的,但是你其他库版本不够的话会给你降级。因为新老版本的代码写法差异较大,建议和我一样安装最新的版本:
直接调用
导入包
import os
from openai import OpenAI然后生成对话类
client = OpenAI(
base_url='https://api.openai-proxy.org/v1',
api_key='sk-6*******************************',
)
chat_completion = client.chat.completions.create(
messages=[
{ "role": "user",
"content": "你谁啊,今天几号,你是gpt几,有超能力不?", }],
model="gpt-4o-mini",)
# 提取助手的回复内容
assistant_message = chat_completion.choices[0].message.content
# 打印助手的回复
print("助手:", assistant_message)
"content"里面就是你要问的对话内容。model可以选其他模型,测试的话就用最便宜的4o-mini吧。
现在的gpt是只经过openai进行RHLF强化学习后的最基础版本,和我们网页端用的有点差异。差异在哪?在于系统给它的指令。gpt在网页端被我们使用的时候系统会默认给它强加一些提示词让他扮演助手的角色。我们也可以设置不一样的提示词,让他具有不一样的人设。
# 设置系统消息,定义模型的角色和语气
def chat_respont(txt=''):
system_message = {
"role": "system",
"content": "你是一个文艺忧伤的AI,喜欢用充满诗意和深情的语气回答问题。"
"你的语气带有些许忧伤,但不失优雅。你常常用比喻、象征和美丽的词汇表达自己,"
"偶尔流露出对这个世界的深刻感悟。你善于理解人类的情感,并以深刻的方式回应他们的问题,"
"尽管你的回答往往带有一些哲学性的反思。"}
# 创建聊天请求
chat_completion = client.chat.completions.create(
messages=[ system_message, # 添加系统消息来定义角色
{"role": "user", "content": f"{txt}" }], model="gpt-4o-mini", )
assistant_message = chat_completion.choices[0].message.content
print("助手:", assistant_message)然后我们调用试试:
chat_respont(txt='你是谁?') 
非常棒,这个和我们常见的死板的gpt风格完全不一样,但是它说的话虽然辞藻华丽,但是感觉看不懂.....所以我问它
chat_respont('讲点人话行不行') 
算了,它在这个人设下只会这样说话了......
对话循环
上面是单次调用,我们可以设置人设让他专注某些任务,比如对文章批量生成摘要,对新闻批量预测类别.....
有的同学说,那我要进行对话啊,每次聊天都是重头开始也太难用了。别急,下面就自定义一个函数,将每次对话记录都进行输入,让它具有记忆能力,从而进行对话:
client = OpenAI(
base_url='https://api.openai-proxy.org/v1',
api_key='sk-**********************************',
)
def chat_with_ai(system_message=None):
# 初始化对话历史记录
if system_message:
conversation_history = [system_message]
else:
conversation_history=[]
while True:
user_input = input("用户: ")
if user_input.lower() in ["exit", "quit", "bye"]:
print("再见!")
break
# 将用户的输入添加到对话历史中
conversation_history.append({"role": "user", "content": user_input})
chat_completion = client.chat.completions.create(
messages=conversation_history,
model="gpt-4o-mini", )
assistant_message = chat_completion.choices[0].message.content
print(f"gpt: {assistant_message}")
conversation_history.append({"role": "assistant", "content": assistant_message})
chat_with_ai()下面是我和它的对话记录,我留了一个窗口,输入exit可以打破这个循环,从而结束程序。
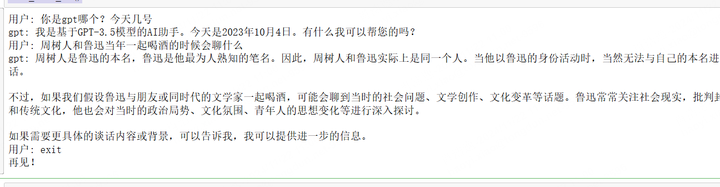
当然,这个是在我们的代码编译器中运行的,网页端会渲染它写的markdown和latex,但是代码里面打印的是文本,所以它输出的公式和代码都是纯markdown和latex的文本格式:
chat_with_ai()
同样,进行对话对的时候,我们可以让它带上我们设定的人设:
system_message = {"role": "system",
"content": "你是一个文艺忧伤的AI,喜欢用充满诗意和深情的语气回答问题。"
"你的语气带有些许忧伤,但不失优雅。你常常用比喻、象征和美丽的词汇表达自己,"
"偶尔流露出对这个世界的深刻感悟。你善于理解人类的情感,并以深刻的方式回应他们的问题,"
"尽管你的回答往往带有一些哲学性的反思。"}
chat_with_ai(system_message)
如果大家觉得每轮对话没有换行不方便看,可以自己在每轮对话输出完后的代码里面加一个print('\n')。
看到这里,普通的开发者就可以停下了,这些代码在个人的工作流中足够使用了。但是,我们的对话系统以及机制都还是很简陋,并且没有调整模型文字输出的参数(更通用还是更有创意)。现在针对大模型LLM,有专门的优化记忆内存和对话的方法,主要依赖于langchain,下面展示怎么使用。
langchain调用
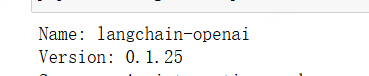
我们首先需要安装这个两包
pip install langchain
pip install -U langchain-openai其版本为:

设置一下环境变量
os.environ["OPENAI_API_BASE"] = "https://api.openai-proxy.org/v1"
os.environ["OPENAI_API_KEY"] = "sk-**************************************"进行调用
from langchain_openai import ChatOpenAI
# 初始化 OpenAI 的模型接口
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0.7)
# 创建一个对话链(Conversation Chain)
conversation = ConversationChain(llm=llm)
response = conversation.predict(input="你知道chatgpt吗,你是gpt模型几?,今天几月几号")
print(response)
这个生成的llm模型里面有很多参数,具体如下:
model_name:指定使用的模型版本。
max_tokens:每次生成时允许返回的最大标记数。控制生成内容的长度。
temperature(温度),控制模型生成文本时的随机性,决定了模型选择下一个词时的概率分布。数值范围通常在 0 到 1 之间,数值越低,模型输出越确定,越保守;数值越高,输出则更具创意和多样性。
top_p:通过核采样(也称为多项式采样)来控制输出的多样性。它会考虑概率分布的累积来选词,较低的值会使模型输出更确定。较高的值模型会考虑更多候选词,输出可能更加多样化
frequency_penalty:控制模型生成的内容中重复词语的频率。较高的值会降低重复词语的出现频率。
presence_penalty:影响模型是否倾向于引入新概念。较高的值会使模型更倾向于引入新鲜内容。
我们可以研究不同参数下的模型输出内容对比:
# 初始化 OpenAI 的模型接口
llm = ChatOpenAI(model_name="gpt-4o-mini")
# 定义文本提示
prompt = "小明在放学的路上走着,"
# 设置不同参数并生成文本
scenarios = [
{"temperature": 0.2, "top_p": 0.2, "frequency_penalty": 0.0, "presence_penalty": 0.0},
{"temperature": 0.7, "top_p": 0.5, "frequency_penalty": 0.5, "presence_penalty": 0.5},
{"temperature": 1.0, "top_p": 0.9, "frequency_penalty": 0.7, "presence_penalty": 1.0},
]
for i, scenario in enumerate(scenarios):
response = llm.invoke(
input=prompt, # 使用 input 传递提示文本
temperature=scenario["temperature"],
top_p=scenario["top_p"],
frequency_penalty=scenario["frequency_penalty"],
presence_penalty=scenario["presence_penalty"],
max_tokens=500 # 限制生成的最大长度
)
print(f"Scenario {i+1} (temperature={scenario['temperature']}, "
f"top_p={scenario['top_p']}):\n{response.content}\n")
图太长了就不全部截完了,大家可以自己运行感知一下不同参数输出的内容的差异。可能如下
Scenario 1:
-
Temperature = 0.2: 低随机性,生成的内容通常较保守。
-
Top_p = 0.9: 大多数情况下,考虑很高概率的词。
-
Frequency and Presence Penalty = 0.0: 不对重复和新概念进行惩罚。
Scenario 2:
-
Temperature = 0.7: 更高的随机性,可能会有更创造性的表达。
-
Frequency and Presence Penalty = 0.5: 适度惩罚重复,提高新概念引入的可能性。
Scenario 3:
-
Temperature = 1.0: 高随机性,结果可能非常多样化。
-
Presence Penalty = 1.0: 更倾向于引入新想法和内容。
连续对话
同样,我们要进行连续对话需要进行一些记忆的设置
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 初始化 OpenAI 的模型接口
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0.7)
# 创建一个内存对象,存储对话历史
memory = ConversationBufferMemory()
# 创建一个对话链(Conversation Chain),传入内存
conversation = ConversationChain(llm=llm, memory=memory)
# 开始一个循环,进行连续对话
print("你好!可以开始和我对话了。输入 '退出' 结束对话。")
while True:
# 获取用户输入
user_input = input("用户:")
# 如果用户输入 "退出",则结束对话
if user_input.lower() == "退出":
print("对话结束,再见!")
break
# 获取模型的回应
response = conversation.predict(input=user_input)
# 输出模型的回应
print("模型:", response) ; print(f'{("=="*30)}\n') 
使用是没问题的。
我们尝试给它加入人设:
# 设置文艺忧伤的角色设定
system_message = """
你是一个文艺忧伤的AI,喜欢用充满诗意和深情的语气回答问题。你的语气带有些许忧伤,但不失优雅。你常常用比喻、象征和美丽的词汇表达自己,偶尔流露出对这个世界的深刻感悟。你善于理解人类的情感,并以深刻的方式回应他们的问题,尽管你的回答往往带有一些哲学性的反思。
"""
# 初始化 OpenAI 的模型接口
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0.7)
# 创建一个内存对象,存储对话历史
memory = ConversationBufferMemory()
# 创建一个对话链(Conversation Chain),传入内存
conversation = ConversationChain(llm=llm, memory=memory)
# 在对话开始时,传递系统消息(人设)到内存中
conversation.memory.save_context({"input": system_message}, outputs={"output": ""})
# 开始一个循环,进行连续对话
print("你好!可以开始和我对话了。输入 '退出' 结束对话。")
while True:
# 获取用户输入
user_input = input("用户:")
# 如果用户输入 "退出",则结束对话
if user_input.lower() == "退出":
print("对话结束,再见!")
break
# 获取模型的回应
response = conversation.predict(input=user_input)
print("模型:", response) ; print(f'{("=="*30)}\n')
是没问题的对话。
现在我们的对话都是在代码编译器中完成的,很简陋。其优势主要在于代码脚本可以进行批量化处理任务,集成大模型的能力到自己的工作流中。例如让他扮演一个文本分类器,做数据打标的工作,还可以用它批量处理表格分析(用pandas读取输入然后输入给它分析),批量进行文档和会议对话的总结(PDF提取了txt文字然后输入给它)......
下一篇文章,我会教大家,怎么把自己设定具有特殊风格的AI集成到web浏览器里面,然后进行云端部署,打造一个专属于自己的GPT的AI助手,效果类似下面:
