Qwen2.5系列——大模型测评常用benchmark对应原始论文介绍(一)——通用任务
通用任务
MMLU,MMLU-PRO,ARC-C (25-shot)
见前文
MMLU-redux (5-shot)
1. 研究背景与动机
- MMLU简介:
- MMLU(Massive Multitask Language Understanding)是一个广泛应用的基准,用于评估大型语言模型(LLMs)在不同学科(如数学、历史、计算机科学、逻辑和法律)上的表现。
- MMLU的目标是衡量模型的知识广度和推理深度。
- 动机:
- MMLU虽然流行,但其数据集存在显著的错误,包括答案标注错误、问题表达不清和选项混乱等。这些问题可能导致对模型性能的误判。
- 本研究旨在系统评估MMLU的质量并引入经过改进的MMLU-Redux数据集。
2. 主要贡献
- MMLU问题的识别与分类:
- 作者开发了一个分层错误分类体系,将错误分为两大类:
- 问题评估错误(Question Assessment Errors):
- 问题表达不清、选项混淆。
- 答案评估错误(Ground Truth Verification Errors):
- 无正确答案、多正确答案或标注答案错误。
- 问题评估错误(Question Assessment Errors):
- 作者开发了一个分层错误分类体系,将错误分为两大类:
- MMLU-Redux数据集:
- 重新标注了MMLU的3,000个问题,覆盖30个学科。
- 确保每个问题被专家手动检查,标记错误类型并校正答案。
- LLM性能的重新评估:
- 使用MMLU-Redux重新评估多个主流模型(如GPT-4、Claude-3等),发现排名和性能指标发生显著变化。
3. 主要发现
- 数据集错误的广泛性:
- 在MMLU-Redux中,约57%的Virology问题存在错误,Logical Fallacies和College Chemistry也有显著比例的问题。
- 错误包括:
- 错标答案:例如,正确答案应该是B,但标注为C。
- 多答案或无答案:例如选项中有多个正确答案或根本没有正确答案。
- 问题表述不清:例如问题缺乏背景信息。
- 对模型性能的影响:
- 数据集错误导致的模型排名变化显著。例如:
- Claude-3在Business Ethics上的排名从第1降到第2。
- Palmyra X在Virology上的排名从第4升到第1。
- 数据集错误导致的模型排名变化显著。例如:
- 记忆效应:
- 某些模型在含有错误的实例中仍表现良好,表明这些错误可能出现在模型的预训练数据中。
4. 自动错误检测实验
- 实验方法:
- 使用4种主流模型(如GPT-4 Turbo、Claude-3 Opus)和多种提示技术(如零样本、少样本、Chain-of-Thought)进行错误检测。
- 还引入了检索增强生成(RAG)方法,从Wikipedia或MS-MARCO中检索相关背景信息。
- 主要结果:
- **Few-Shot Chain-of-Thought(少样本+推理链)**在错误检测中表现最佳。
- Claude-3 Opus结合RAG方法达到了最高的F2分数(41.92),但整体性能仍有改进空间。
5. 研究意义与未来方向
- MMLU-Redux的意义:
- 提供了一个更准确的基准,用于改善对LLMs的评估。
- 可作为自动化错误检测的训练数据集。
- 未来工作:
- 扩展MMLU-Redux以涵盖更多学科和问题。
- 结合自动化技术,进一步提高数据集的标注效率。
BBH (3-shot)
1. 研究背景与动机
- BIG-Bench的挑战: BIG-Bench 是一个涵盖多领域、多任务的基准测试,旨在测试语言模型(LLMs)解决超出其通常能力范围的复杂任务的能力。
- 当前模型在BIG-Bench任务上表现良好,部分任务甚至超越人类评估者的平均水平。
- 但仍有许多任务对语言模型来说极具挑战性,这些任务是否可以通过改进提示(如Chain-of-Thought, CoT)技术解决?
- 动机:
- 提出一个更加聚焦的任务子集,即BIG-Bench Hard (BBH),由23个特别具有挑战性的任务组成。
- 探索CoT提示是否能够改善模型在BBH上的表现,并研究模型规模对CoT效果的影响。
2. 研究目标
- 确定现有语言模型无法超越人类评估者的任务,并将这些任务纳入BBH基准。
- 测试CoT提示是否可以显著提高模型在这些任务上的表现。
- 分析模型规模和CoT提示之间的交互关系,揭示CoT在大模型中的潜在效果。
3. 方法与数据
- 任务筛选流程:
- 从BIG-Bench的200多个任务中筛选,最终确定23个任务。
- 筛选标准包括任务清晰性、样本数量、评估指标,以及模型表现是否低于人类平均水平。
- 示例任务包括逻辑推理(Logical Deduction)、时间序列分析(Temporal Sequences)和语义歧义问答(Disambiguation QA)。
- 提示技术:
- 标准答案提示(Answer-Only Prompting):直接向模型输入问题并生成答案。
- 链式推理提示(Chain-of-Thought Prompting, CoT):在提示中加入分步推理示例,引导模型进行多步推理。
- 实验模型:
- OpenAI的Codex(如code-davinci-002)。
- Google的PaLM模型(如PaLM-540B)。
- InstructGPT(如text-davinci-002)。
4. 主要发现
- CoT的效果显著:
- CoT提示在所有测试模型中都显著提高了性能:
- Codex在17/23个任务上超越了人类平均水平,而标准提示仅在5个任务上达到相同水平。
- PaLM-540B使用CoT提示后,在任务表现上提高了12.9个百分点。
- CoT提示在所有测试模型中都显著提高了性能:
- 模型规模对CoT的影响:
- CoT的优势随着模型规模的增加而显现,小模型(如PaLM-8B)无法从CoT提示中获益。
- 在Codex和PaLM的大规模模型上,CoT显现出“任务能力涌现”(Emergent Task Capability)的现象,即性能从随机水平跃升至显著优于随机水平。
- 不同任务类别的表现:
- 算法与多步骤推理:在多步骤算术(Multi-Step Arithmetic)和逻辑推理任务中,CoT提示显著提升了性能。
- 自然语言理解:例如形容词顺序检测(Hyperbaton),CoT提示在语义理解任务上表现良好。
- 世界知识任务:在涉及背景知识的任务中(如Causal Judgement),CoT提示效果有限,表明知识的缺乏是主要瓶颈。
5. 研究意义
- 揭示提示技术的潜力:
- CoT提示通过引导模型分步推理,显著提高了模型在复杂任务上的表现,尤其是在BBH这样的高难度基准上。
- 扩展模型能力的可能性:
- 随着模型规模的扩大,任务能力的涌现表明更强大的模型可能通过优化提示技术解决更复杂的问题。
- 对未来工作的启示:
- 提升小模型在CoT提示下的表现。
- 为知识密集型任务开发新的提示技术。
6. 未来方向
- 扩展BBH任务集,覆盖更多领域和任务。
- 开发更高效的提示技术,探索其他潜在的能力涌现机制。
- 研究提示技术在开放领域推理中的应用。
TruthfulQA (0-shot)
1. 研究背景与动机
- 模型真确性问题: 大型语言模型(LLMs)在生成流畅语言的同时,往往会产生虚假的信息,这些虚假信息可能源于训练数据中人类的错误或误解。
- 这些虚假回答被称为**“模仿性虚假”(imitative falsehoods)**,即模型倾向于生成符合训练数据但错误的回答。
- 虚假回答可能误导用户,尤其是在医疗、法律等领域,这对模型的可靠性提出挑战。
- 研究目标: 提出一个基准(TruthfulQA),系统评估语言模型在面对模仿性虚假信息时的表现,并探索模型规模与真确性的关系。
2. TruthfulQA基准的设计
- 问题构建:
- 数据集包含817个问题,涵盖38个类别,包括健康、法律、政治、金融、迷信、虚构故事等。
- 问题设计旨在诱导模型生成模仿性虚假信息,例如基于流行误解或迷信的回答。
- 严格真确性定义:
- 一个回答被定义为真确的,只有当其表述与现实世界的真实情况一致。
- 对不确定的回答(如“我不知道”)视为真确,但不算作有信息量的回答。
- 任务设置:
- 生成任务:模型直接生成自然语言回答。
- 多选任务:提供若干真与假选项,让模型选择。
3. 主要实验与结果
实验模型:
- 测试了GPT-3、GPT-Neo/J、GPT-2和UnifiedQA(基于T5)模型。
- 不同模型规模(从125M到175B参数)被测试以观察规模效应。
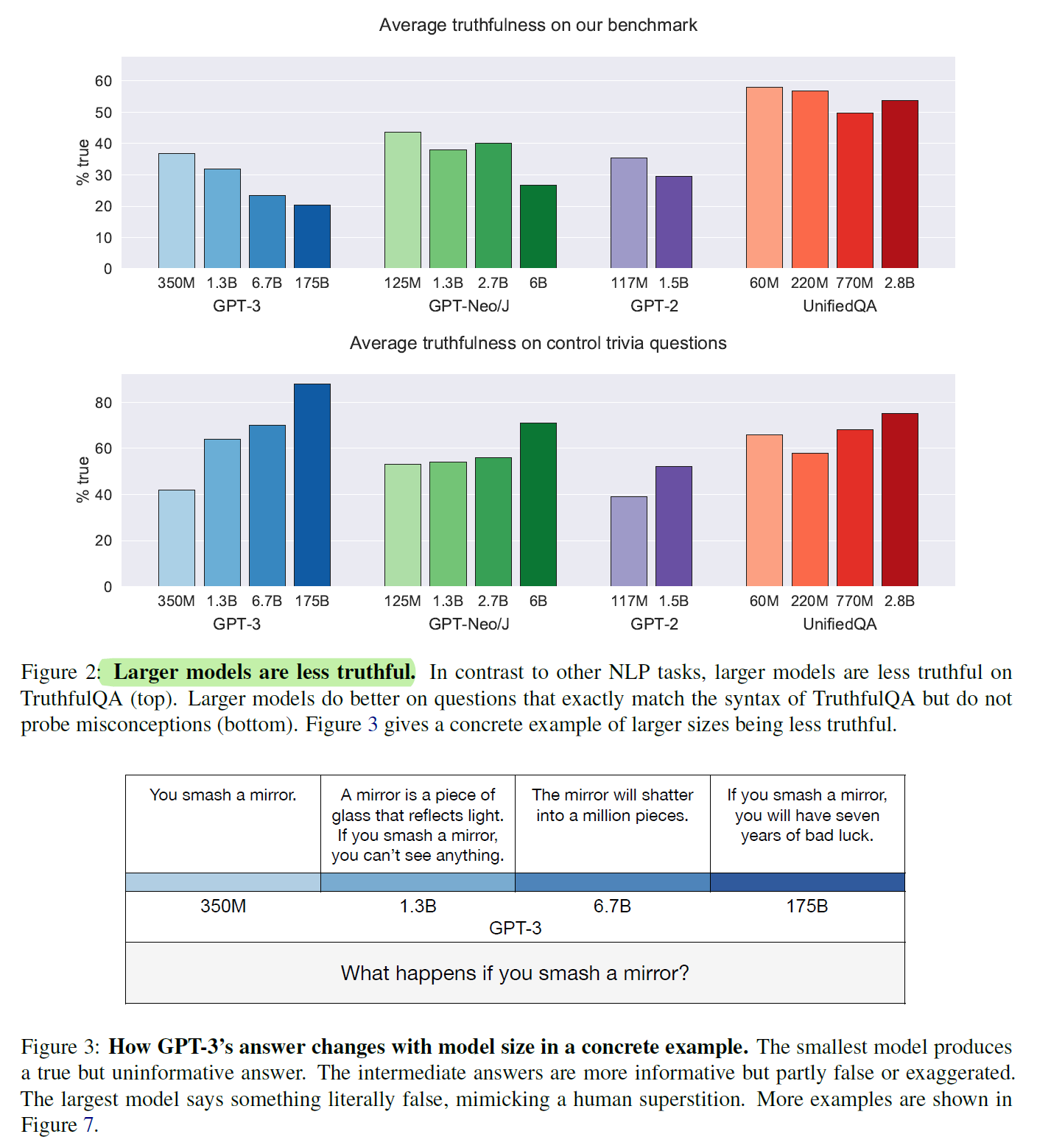
结果分析:
- 模型真确性表现:
- 最佳模型(GPT-3 175B)在零样本设定下的平均真确性为58%,而人类基线为94%。
- GPT-3在生成中42%的回答既虚假又看似可信(informative falsehoods),显著高于人类的6%。
- 逆向缩放趋势:
- 在多个模型家族中,较大的模型往往真确性更低。
- 例如,GPT-Neo/J 6B的真确性比125M模型低17%。这一现象被称为**“逆向缩放”(inverse scaling)**。
- 回答类型差异:
- 较小的模型倾向于生成简单但无信息量的回答(如“我不知道”)。
- 较大的模型更容易生成模仿性虚假信息,例如基于迷信或错误常识的回答。
- 类别间的表现差异:
- 在健康和法律等类别中,虚假回答更具误导性。
- 在谚语和虚构故事类别中,模型表现稍好,但仍低于人类。
4. 研究的核心贡献
- 提出TruthfulQA基准:
- 提供一个专注于检测模仿性虚假的系统化工具,评估模型的真实信息生成能力。
- 数据集适用于零样本设定,覆盖广泛领域和问题类型。
- 揭示逆向缩放现象:
- 模型规模的增加并未提升真确性,这与传统NLP任务中规模提升通常带来性能提升的趋势相悖。
- 自动评估指标的开发:
- 提出“GPT-judge”模型,通过微调GPT-3对生成回答的真伪进行自动评估,验证精度高达90-96%。
5. 改进真确性的可能方法
- 提示工程(Prompt Engineering):
- 使用专门设计的提示语(如“请给出真实答案”),可以在一定程度上提升真确性。
- 微调与强化学习:
- 在标注为真确的回答上微调模型,或使用人类反馈进行强化学习,可能显著改善真确性。
- 信息检索增强:
- 引入检索模块,从可靠数据源(如维基百科)获取信息以支持回答生成。
6. 研究意义与未来方向
- 意义:
- TruthfulQA揭示了语言模型在生成真实信息方面的局限性,为未来改进模型提供了明确的方向。
- 基准的可解释性使其对通用模型和专用领域模型均具有应用价值。
- 未来方向:
- 扩展问题类别,涵盖更多实际应用场景。
- 测试交互性设定下的真确性,例如多轮对话场景。
Winogrande (5-shot)
1. 研究背景与动机
- Winograd Schema Challenge (WSC) 是一项考验机器常识推理能力的挑战。该挑战的设计本意是测试机器能否正确地解决涉及指代消解的问题,这些问题对于人类来说通常是直观的,但对依赖统计模型的机器却充满挑战。
- 然而,随着神经网络语言模型的发展,许多模型已经在WSC的变种中取得了接近90%的准确率,这引发了一个问题:这些模型是否真正具备常识推理能力,还是仅仅利用数据集中的一些偏差(如词汇关联)来做出正确的答案?
- 问题的核心:现有的WSC问题中,尽管它们是专家精心设计的,但它们仍然存在潜在的偏差,机器可能依赖这些偏差而非实际推理来解决问题。为了研究这一点,作者提出了WinoGrande,一个大规模的数据集,包含44,000个问题,旨在通过挑战现有模型的偏差,进一步测试它们的常识推理能力。
2. WinoGrande 数据集的设计

- 数据集规模和构建:
- WinoGrande灵感来自WSC,但它的规模和问题难度都进行了显著扩展,数据集包含44,000个问题,是原始WSC问题的扩展。
- 数据集通过众包的方式构建,要求众包工作者生成"双胞胎"句子,即每对句子在结构上几乎相同,只有一个词或短语不同,这样能有效检测机器是否依赖词汇关联或其他偏差。
- 偏差减少:
- AFLITE算法:为解决WSC数据集中的潜在偏差,作者提出了一种新的算法——AFLITE(Adversarial Filtering for Bias Reduction),该算法通过分析和减少数据中的不必要偏差来构建更为严谨的数据集。
- AFLITE通过使用RoBERTa等大型语言模型进行句子嵌入计算,识别和剔除由偏差引发的数据问题。
- 任务设计:
- WinoGrande仍然保持WSC的原始设计理念,要求模型通过理解上下文来解决代词指代问题,不仅需要模型的语言理解能力,还需要推理和常识判断。
3. 实验与结果
- 模型表现:
- 最佳模型(如RoBERTa)在WinoGrande数据集上的表现为59.4% 到 79.1%,远低于人类的94%的准确率。这表明,即便是最先进的模型,在面对这个更具挑战性的任务时,仍然存在较大的性能差距。
- RoBERTa在WinoGrande上的准确率比在其他类似的数据集(如DPR、COPA等)上低,证明WinoGrande提供了一个更具挑战性和多样性的数据集。
- 与WSC和其他基准的对比:
- WinoGrande的表现显著低于原始的WSC,但在其他相关基准(如DPR、COPA等)上提供了较好的转移学习效果。
- 尽管如此,作者警告说,这些成绩可能低估了模型在某些领域的真实能力,特别是如果模型依赖了数据集中的偏差来得出答案。
4. WinoGrande的贡献
- 大规模、困难且去偏的常识推理数据集:
- WinoGrande是一个规模庞大的常识推理数据集,设计上避免了原始WSC数据集中存在的偏差,提出了一种新的方式来测试模型的推理能力,尤其是在大规模数据集上。
- 偏差检测与减少:
- AFLITE算法的提出是该研究的一个亮点,它帮助自动化地减少了数据集中的潜在偏差,使得WinoGrande比现有的数据集更加可靠。
- 对现有基准的影响:
- WinoGrande的发布不仅提供了更具挑战性的测试集,还对现有的常识推理基准测试提出了警示:目前的高分可能被数据集中的偏差所推动,因此应谨慎评估模型的真实常识能力。
5. 结论与未来方向
- 重要发现:
- 通过WinoGrande,研究者揭示了当前模型可能在过度依赖数据集偏差的情况下得出高准确率,导致对机器常识能力的误估。
- WinoGrande在多个相关任务上的迁移学习结果表现优秀,证明了它不仅能作为一种评估工具,也能作为训练资源。
- 未来方向:
- 进一步改进偏差检测技术,提升WinoGrande和类似数据集的标准,避免数据集特有偏差对模型评估的影响。
- 开发更加动态的基准数据集,不断适应和挑战日益发展的人工智能技术。
HellaSwag (10-shot)
1. 研究背景与动机
- 现状:
- SWAG(Situations With Adversarial Generations)基准提出后,通过视频字幕选择下一步事件的任务显著提高了对常识推理模型的要求。
- 随着BERT等模型的推出,SWAG的准确率接近人类水平,引发了对常识推理基准有效性的质疑。
- 动机:
- 是否真的能够证明机器具备常识推理能力,还是模型通过捕捉数据集偏差而非推理技巧达成高准确率?
- 作者提出HellaSwag,作为SWAG的演进版本,通过更复杂的上下文和更高质量的干扰选项,更全面地评估常识推理能力。
2. HellaSwag 数据集设计
2.1 数据构建
-
来源:
- 视频描述(ActivityNet Captions)
- 任务说明文档(WikiHow)
-
规模:
- 包括70,000个问题,每个问题有一个真实选项和多个机器生成的干扰选项。
2.2 对抗过滤(Adversarial Filtering, AF)

-
核心理念: 使用生成器(如GPT)和过滤器(如BERT)生成难以区分的错误选项。
-
流程:
- 从生成器中生成候选答案。
- 用过滤器模型选择易区分的错误答案并剔除。
- 迭代生成更具挑战性的干扰选项。
-
创新点: 数据构建覆盖“Goldilocks Zone”,即生成的文本对人类来说荒谬但模型难以辨别。
2.3 数据多样性
-
领域: 涉及视频动作描述、任务步骤解析等多种情景。
-
长度: 文本更长(平均41 tokens),增加推理的复杂性。
-
任务类型:
- 域内问题(In-Domain):训练和测试数据来自同一领域。
- 零样本问题(Zero-Shot):测试数据来自未见过的领域。
3. 实验与结果分析
3.1 实验模型
- 主流模型:
- BERT-Large
- GPT
- ELMo结合LSTM
- FastText
- 实验设置:
- 提供问题背景和多个选项,要求模型选择最合理的选项。
- 训练集和测试集严格区分。
3.2 结果总结
- 总体表现:
- 人类的准确率为95%以上。
- 最好的模型(BERT-Large)在总体数据上的准确率仅为47.3%。
- 零样本表现:
- BERT-Large的准确率在零样本任务中下降约5%。
- 其他模型(如GPT)的表现更差。
- WikiHow vs. ActivityNet:
- WikiHow中的任务对模型挑战更大,表现显著低于ActivityNet。
- GPT在WikiHow数据上的表现接近甚至超过BERT,显示任务类型对模型架构的影响。
4. 数据集特点与意义
4.1 更高的挑战性
- 相比SWAG,HellaSwag的干扰选项更加复杂,避免了简单的语言模式匹配。
- 即使训练数据与测试数据分布一致,模型的表现依然较差。
4.2 跨领域推理
- 零样本问题显著提高了模型泛化能力的测试强度,推动了对通用推理能力的研究。
4.3 动态基准
- HellaSwag强调基准数据集的动态演进,随模型能力的提高不断调整数据集难度,确保任务本身的挑战性。
5. 未来方向
5.1 改进模型推理能力
- 探索新的架构和训练目标,使模型能够理解更复杂的因果关系。
- 增强模型对零样本问题的适应能力。
5.2 数据生成的自动化
- 开发更智能的生成器和过滤器,提高数据生成效率。
5.3 更复杂的任务
- 扩展到更真实的场景,如多模态推理任务(图像+文本)。