241123_基于MindSpore学习Bert
241123_基于MindSpore学习Bert
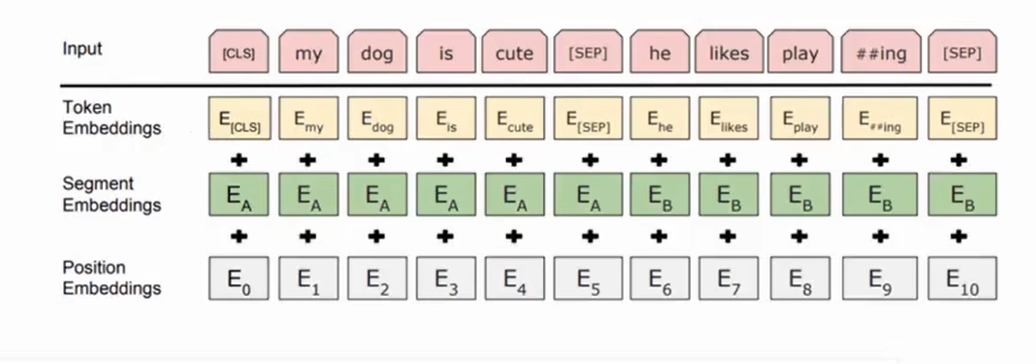
bert和transformer都有Embedding操作,包括词嵌入(word embedding)和位置嵌入(positional embedding)
但是transformer中的位置信息是三角函数
bert中的位置信息是可学习的,并增加了用于区分不同句子的段嵌入(Segment Embeddings)。
三个embedding作相加得到最后的embedding
bert就是多层的transformer encoder层构成的
bert训练
训练分为两个阶段:pre-train和fine-tune
pre-train阶段模型是在无标注的标签数据上进行训练
fine-rune阶段,模型先被pre-train模型参数初始化,然后所有的参数用下游的有标注的数据进行训练
预训练
由两个自监督任务组成。即MLM和NSP
MLM是在原句上挖洞,类似于完形填空,在输入的句子上mask掉一些单词,然后通过上下文预测该词(给模型做完形填空)。这个mask的概率是15%。也就是说,一共只有15%的单词被mask掉,所以训练速度较低。
NSP是判断句子B是不是A的下文。从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。

MLM 和 NSP 一起训练。该模型旨在最小化 MLM 和 NSP 的组合损失函数,从而形成一个强大的语言模型,增强了理解句子内上下文和句子间关系的能力。但是部分模型删除了NSP任务
微调Fine-Tuning
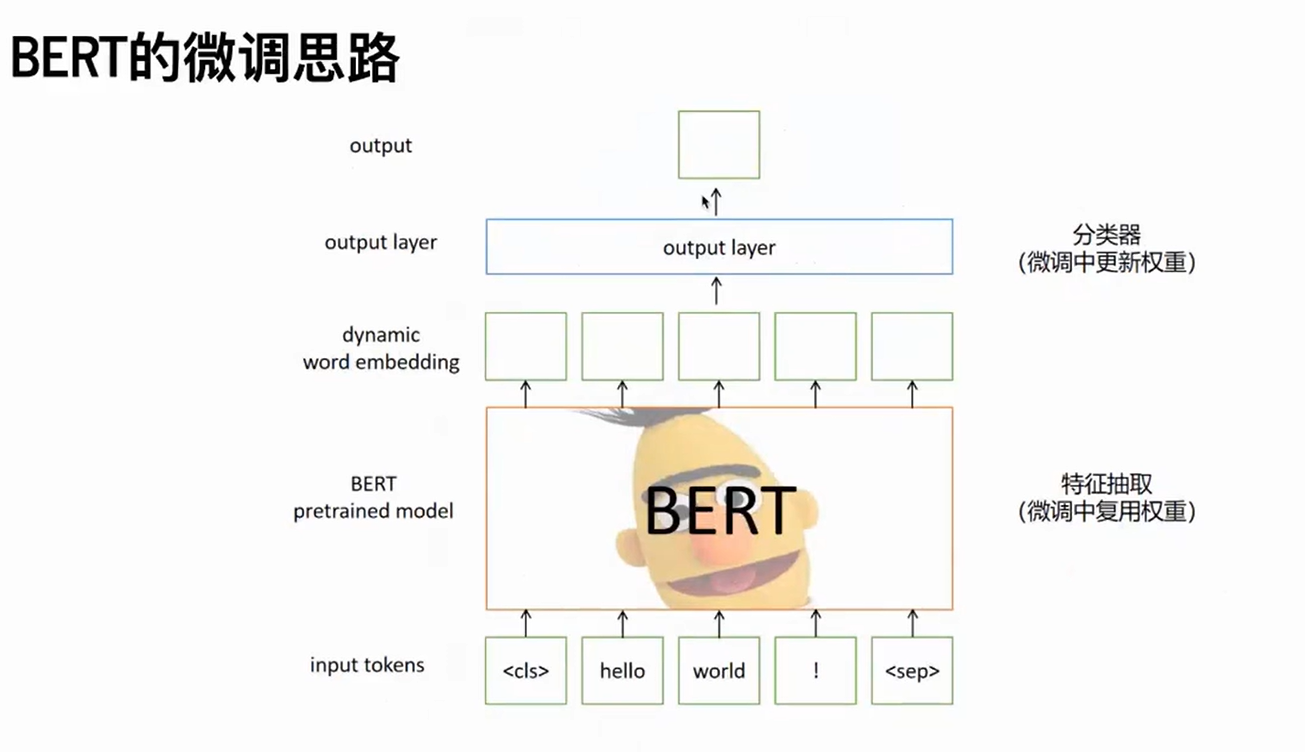
把bert当成一个特征提取器,特征输入到word embedding得到一个编码信息,然后送入分类器,做分类,得到loss,反向传播、更新,把得到的梯度送到optim中更新。
bert的下游任务分为
1、单句子分类(情感分析)
2、句子对分类(判断两个句子在语义上是否等效)
3、问答任务(给定描述、找到描述中针对问题的答案)
4、文本标注任务(命名体识别)
3、问答任务(给定描述、找到描述中针对问题的答案)
4、文本标注任务(命名体识别)
打卡截图: