Rook入门:打造云原生Ceph存储的全面学习路径(下)
文章目录
- 六.Rook部署云原生CephFS文件系统
- 6.1 部署cephfs storageclass
- 6.2 创建容器所需cephfs文件系统
- 6.3创建容器pod使用rook-cephfs提供pvc
- 6.4 查看pod是否使用rook-cephfs
- 七.Ceph Dashboard界面
- 7.1 启用dashboard开关
- 7.2 ceph-dashboard配置外部访问
- 7.3 Dashboard web admin密码查看
- 7.4 dashboard web登录查看
- 八.Prometheus监控
- 8.1 查看rook-ceph-mgr metrics监控指标
- 8.2部署prometheus-operator
- 8.3 部署prometheus实例
- 8.4部署grafana
- 8.5配置grafana监控ceph模板
- 8.6 在grafana上查看ceph集群状态
- 九.常见故障排查
- 9.1 ceph集群出现警告mgr modules have recently crashed
- 9.2 ceph集群出现警告 mons are allowing insecure global_id reclaim
- 9.3 rook部署ceph集群某个pod异常或者pending状态
- 9.4 PVC处于pending状态
- 9.5 rook-ceph osd down格式化硬盘重新挂载
- 十.ceph集群常用命令
- 10.1查看集群状态命令
- 10.2 Ceph mds命令
- 10.3 ceph osd命令
- 10.4 ceph pg命令
- 10.5 ceph osd pool命令
- 10.6 rados命令
六.Rook部署云原生CephFS文件系统
6.1 部署cephfs storageclass
cephfs文件系统与RBD服务类似,要想在kubernetes pod里使用cephfs,需要创建一个cephfs-provisioner storageclass服务,在rook代码里已有资源文件,单独部署即可
[root@node1 examples]#
kubectl create -f deploy/examples/csi/cephfs/storageclass.yaml
查看cephfs storageclass名称
[root@node1 examples]# kubectl get storageclasses.storage.k8s.io | grep rook-cephfs
rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 21d
[root@node1 examples]#
6.2 创建容器所需cephfs文件系统
创建容器所需pvc指定rook部署rook-cephfs存储类名称
[root@node1 cephfs]# cat pvc.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: rook-cephfs
[root@node1 cephfs]#
[root@node1 cephfs]# kubectl apply -f pvc.yaml
查看pvc所提供是rook-cephfs
[root@node1 cephfs]# kubectl get pvc | grep cephfs-pvc
cephfs-pvc Bound pvc-da18c8f9-00c1-4c39-8c53-68a628fa8bdd 1Gi RWO rook-cephfs 21d
rook-cephfs 7d23h
[root@node1 cephfs]#
6.3创建容器pod使用rook-cephfs提供pvc
[root@node1 cephfs]# cat pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: csicephfs-demo-pod
spec:
containers:
- name: web-server
image: nginx:latest
volumeMounts:
- name: mypvc
mountPath: /var/lib/www/html
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: cephfs-pvc
readOnly: false
[root@node1 cephfs]#
[root@node1 cephfs]# kubectl apply -f pod.yaml
查看pod运行状况
[root@node1 cephfs]# kubectl get pod | grep cephfs
csicephfs-demo-pod 1/1 Running 0 21d
[root@node1 cephfs]#
6.4 查看pod是否使用rook-cephfs
[root@node1 cephfs]# kubectl exec -it csicephfs-demo-pod -- bash
root@csicephfs-demo-pod:/# df -hT | grep csi-vol
10.68.91.46:6789,10.68.110.0:6789,10.68.225.251:6789:/volumes/csi/csi-vol-50d5c216-3e2a-11ed-9773-9a6110af61d6/f4e696bf-757d-4793-b2c2-3091d38ccec5 ceph 1.0G 0 1.0G 0% /var/lib/www/html
root@csicephfs-demo-pod:/#
root@csicephfs-demo-pod:/# echo "cephfs" > /var/lib/www/html/index.html
root@csicephfs-demo-pod:/# cat /var/lib/www/html/index.html
cephfs
root@csicephfs-demo-pod:/#
注:登录相应pod容器可以看到pod已经挂载cephfs文件系统地址,可以在相应挂载目录创建内容。
七.Ceph Dashboard界面
ceph有一个dashboard web管理界面,通过web界面在可以查看集群的状态,包括总体运行状态,mgr、osd、rgw等服务状态,还可以查看ceph pool池及pg状态等相关信息。
7.1 启用dashboard开关
在cluster.yaml文件中,dashboard.enable=true即可。rookoperator就会启用ceph-mgr dashboard模块,默认已启用。Ceph-dashboard默认会通过service的方式将服务暴露给外部,通过8443的https端口进行访问。
[root@node1 examples]# kubectl get svc -n rook-ceph | grep rook-ceph-mgr-dashboard
rook-ceph-mgr-dashboard ClusterIP 10.68.218.45 <none> 8443/TCP 24d
[root@node1 examples]#
7.2 ceph-dashboard配置外部访问
Dashboard web界面外部访问可以通过ingress或者NodePort方式,这里使用NodePort方式将dashboard服务暴露给kubernetes集群外部访问,外部通过nodeport端口访问dashboard服务。
Dashboard-external-https资源文件应用
[root@node1 examples]# kubectl apply -f dashboard-external-https.yaml
查看dashboard nodeport端口32367
[root@node1 examples]# kubectl get svc -n rook-ceph | grep rook-ceph-mgr-dashboard
rook-ceph-mgr-dashboard ClusterIP 10.68.218.45 <none> 8443/TCP 24d
rook-ceph-mgr-dashboard-external-https NodePort 10.68.104.233 <none> 8443:32367/TCP 22d
[root@node1 examples]#
7.3 Dashboard web admin密码查看
用户名默认是admin,密码通过下面方式查看
[root@node1 examples]# kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo ""
Z(M(@>GBC4TUZXQgT6%$
[root@node1 examples]#
7.4 dashboard web登录查看
Dashboard web界面访问https://node_ip:32367

登录后dashboard界面,ceph集群状态,hosts、monitors、osds、rgw、pools、block等相关信息。

八.Prometheus监控
rook部署ceph集群默认没有安装prometheus监控服务,这里我们使用prometheus以容器化运行在kubernetes中,使用prometheus-operator部署方式。
prometheus监控系统包括组件:
Exporter:监控agent端,用于上报,ceph-mgr默认已提供内置监控指标
Prometheus:服务端用于存储监控数据、提供查询、告警等
Grafana:展示监控信息,通常从prometheus获取监控指标通过模板来展示图表信息
8.1 查看rook-ceph-mgr metrics监控指标
[root@node1 examples]# kubectl get svc -n rook-ceph | grep rook-ceph-mgr
rook-ceph-mgr ClusterIP 10.68.33.103 <none> 9283/TCP 24d
Ceph-mgr metrics监控指标访问
[root@node1 examples]# curl http://10.68.33.103:9283/metrics
# HELP ceph_health_status Cluster health status
# TYPE ceph_health_status untyped
ceph_health_status 0.0
# HELP ceph_mon_quorum_status Monitors in quorum
# TYPE ceph_mon_quorum_status gauge
ceph_mon_quorum_status{ceph_daemon="mon.b"} 1.0
ceph_mon_quorum_status{ceph_daemon="mon.c"} 1.0
ceph_mon_quorum_status{ceph_daemon="mon.d"} 1.0
# HELP ceph_fs_metadata FS Metadata
# TYPE ceph_fs_metadata untyped
ceph_fs_metadata{data_pools="5",fs_id="1",metadata_pool="4",name="myfs"} 1.0
# HELP ceph_mds_metadata MDS Metadata
# TYPE ceph_mds_metadata untyped
ceph_mds_metadata{ceph_daemon="mds.myfs-b",fs_id="1",hostname="10.255.82.25",public_addr="172.20.166.175:6801/2538469664",rank="0",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
ceph_mds_metadata{ceph_daemon="mds.myfs-a",fs_id="1",hostname="10.255.82.27",public_addr="172.20.135.49:6801/1468538095",rank="0",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
# HELP ceph_mon_metadata MON Metadata
# TYPE ceph_mon_metadata untyped
ceph_mon_metadata{ceph_daemon="mon.b",hostname="10.255.82.25",public_addr="10.68.225.251",rank="0",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
ceph_mon_metadata{ceph_daemon="mon.c",hostname="10.255.82.26",public_addr="10.68.91.46",rank="1",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
ceph_mon_metadata{ceph_daemon="mon.d",hostname="10.255.82.27",public_addr="10.68.243.187",rank="2",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
# HELP ceph_mgr_metadata MGR metadata
# TYPE ceph_mgr_metadata gauge
ceph_mgr_metadata{ceph_daemon="mgr.b",hostname="10.255.82.25",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
ceph_mgr_metadata{ceph_daemon="mgr.a",hostname="10.255.82.27",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
# HELP ceph_mgr_status MGR status (0=standby, 1=active)
# TYPE ceph_mgr_status gauge
ceph_mgr_status{ceph_daemon="mgr.b"} 0.0
ceph_mgr_status{ceph_daemon="mgr.a"} 1.0
# HELP ceph_mgr_module_status MGR module status (0=disabled, 1=enabled, 2=auto-enabled)
# TYPE ceph_mgr_module_status gauge
ceph_mgr_module_status{name="alerts"} 0.0
ceph_mgr_module_status{name="balancer"} 2.0
ceph_mgr_module_status{name="cephadm"} 0.0
ceph_mgr_module_status{name="crash"} 2.0
ceph_mgr_module_status{name="dashboard"} 1.0
ceph_mgr_module_status{name="devicehealth"} 2.0
ceph_mgr_module_status{name="diskprediction_local"} 0.0
ceph_mgr_module_status{name="influx"} 0.0
ceph_mgr_module_status{name="insights"} 0.0
ceph_mgr_module_status{name="iostat"} 1.0
ceph_mgr_module_status{name="k8sevents"} 0.0
ceph_mgr_module_status{name="localpool"} 0.0
ceph_mgr_module_status{name="mds_autoscaler"} 0.0
ceph_mgr_module_status{name="mirroring"} 0.0
ceph_mgr_module_status{name="nfs"} 1.0
ceph_mgr_module_status{name="orchestrator"} 2.0
ceph_mgr_module_status{name="osd_perf_query"} 0.0
ceph_mgr_module_status{name="osd_support"} 0.0
ceph_mgr_module_status{name="pg_autoscaler"} 2.0
ceph_mgr_module_status{name="progress"} 2.0
ceph_mgr_module_status{name="prometheus"} 1.0
ceph_mgr_module_status{name="rbd_support"} 2.0
ceph_mgr_module_status{name="restful"} 1.0
ceph_mgr_module_status{name="rook"} 0.0
ceph_mgr_module_status{name="selftest"} 0.0
ceph_mgr_module_status{name="snap_schedule"} 0.0
ceph_mgr_module_status{name="stats"} 0.0
ceph_mgr_module_status{name="status"} 2.0
ceph_mgr_module_status{name="telegraf"} 0.0
ceph_mgr_module_status{name="telemetry"} 2.0
ceph_mgr_module_status{name="test_orchestrator"} 0.0
ceph_mgr_module_status{name="volumes"} 2.0
ceph_mgr_module_status{name="zabbix"} 0.0
# HELP ceph_mgr_module_can_run MGR module runnable state i.e. can it run (0=no, 1=yes)
# TYPE ceph_mgr_module_can_run gauge
ceph_mgr_module_can_run{name="alerts"} 1.0
ceph_mgr_module_can_run{name="balancer"} 1.0
ceph_mgr_module_can_run{name="cephadm"} 1.0
ceph_mgr_module_can_run{name="crash"} 1.0
ceph_mgr_module_can_run{name="dashboard"} 1.0
ceph_mgr_module_can_run{name="devicehealth"} 1.0
ceph_mgr_module_can_run{name="diskprediction_local"} 1.0
ceph_mgr_module_can_run{name="influx"} 0.0
ceph_mgr_module_can_run{name="insights"} 1.0
ceph_mgr_module_can_run{name="iostat"} 1.0
ceph_mgr_module_can_run{name="k8sevents"} 1.0
ceph_mgr_module_can_run{name="localpool"} 1.0
ceph_mgr_module_can_run{name="mds_autoscaler"} 1.0
ceph_mgr_module_can_run{name="mirroring"} 1.0
ceph_mgr_module_can_run{name="nfs"} 1.0
ceph_mgr_module_can_run{name="orchestrator"} 1.0
ceph_mgr_module_can_run{name="osd_perf_query"} 1.0
ceph_mgr_module_can_run{name="osd_support"} 1.0
ceph_mgr_module_can_run{name="pg_autoscaler"} 1.0
ceph_mgr_module_can_run{name="progress"} 1.0
ceph_mgr_module_can_run{name="prometheus"} 1.0
ceph_mgr_module_can_run{name="rbd_support"} 1.0
ceph_mgr_module_can_run{name="restful"} 1.0
ceph_mgr_module_can_run{name="rook"} 1.0
ceph_mgr_module_can_run{name="selftest"} 1.0
ceph_mgr_module_can_run{name="snap_schedule"} 1.0
ceph_mgr_module_can_run{name="stats"} 1.0
ceph_mgr_module_can_run{name="status"} 1.0
ceph_mgr_module_can_run{name="telegraf"} 1.0
ceph_mgr_module_can_run{name="telemetry"} 1.0
ceph_mgr_module_can_run{name="test_orchestrator"} 1.0
ceph_mgr_module_can_run{name="volumes"} 1.0
ceph_mgr_module_can_run{name="zabbix"} 1.0
# HELP ceph_osd_metadata OSD Metadata
# TYPE ceph_osd_metadata untyped
ceph_osd_metadata{back_iface="",ceph_daemon="osd.0",cluster_addr="172.20.166.156",device_class="hdd",front_iface="",hostname="10.255.82.25",objectstore="bluestore",public_addr="172.20.166.156",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
ceph_osd_metadata{back_iface="",ceph_daemon="osd.1",cluster_addr="172.20.104.37",device_class="hdd",front_iface="",hostname="10.255.82.26",objectstore="bluestore",public_addr="172.20.104.37",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
ceph_osd_metadata{back_iface="",ceph_daemon="osd.2",cluster_addr="172.20.135.32",device_class="hdd",front_iface="",hostname="10.255.82.27",objectstore="bluestore",public_addr="172.20.135.32",ceph_version="ceph version 17.2.3 (dff484dfc9e19a9819f375586300b3b79d80034d) quincy (stable)"} 1.0
# HELP ceph_disk_occupation Associate Ceph daemon with disk used
.....
.....
.....
[root@node1 examples]#
8.2部署prometheus-operator
[root@node1 examples]#
kubectl apply -f https://raw.githubusercontent.com/coreos/prometheus-operator/v0.40.0/bundle.yaml
Prometheus-operator部署后以容器方式运行
[root@node1 examples]# kubectl get pod | grep prometheus-operator
prometheus-operator-5944b5f9dd-5r789 1/1 Running 0 8d
[root@node1 examples]#
8.3 部署prometheus实例
[root@node1 monitoring]# pwd
/opt/rook/deploy/examples/monitoring
[root@node1 monitoring]#
[root@node1 monitoring]# kubectl apply -f prometheus.yaml -f prometheus-service.yaml -f service-monitor.yaml
prometheus默认提供了9090端口访问,这里更改nodeport类型方式访问
[root@node1 monitoring]# kubectl get svc -n rook-ceph | grep rook-prometheus
rook-prometheus NodePort 10.68.232.216 <none> 9090:30900/TCP 8d
[root@node1 monitoring]#
prometheus访问地址http://node_ip:30900

8.4部署grafana
grafana是一个数据展示的平台,数据展示主要依赖后端的数据源。这里使用prometheus作为数据源,grafana作为展示。grafana部署在kubernetes中,参考grafana on kubernetes官方yaml文件。地址如下,根据自己需求进行修改。
https://grafana.com/docs/grafana/latest/setup-grafana/installation/kubernetes/
Grafana.yaml部署资源文件
---apiVersion: v1kind: PersistentVolumeClaimmetadata:
name: grafana-pvcspec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi---apiVersion: apps/v1kind: Deploymentmetadata:
labels:
app: grafana
name: grafanaspec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
securityContext:
fsGroup: 472
supplementalGroups:
- 0
containers:
- name: grafana
image: grafana/grafana:9.1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: http-grafana
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /robots.txt
port: 3000
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 3000
timeoutSeconds: 1
resources:
requests:
cpu: 250m
memory: 750Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-pv
volumes:
- name: grafana-pv
persistentVolumeClaim:
claimName: grafana-pvc---apiVersion: v1kind: Servicemetadata:
name: grafanaspec:
ports:
- port: 3000
protocol: TCP
targetPort: http-grafana
selector:
app: grafana
sessionAffinity: None
type: LoadBalancer
# kubectl apply -f grafana.yaml
查看grafana运行状态,grafana对外访问使用nodeport形式。
[root@node1 rook]# kubectl get pod,svc | grep grafana
pod/grafana-b8b88d68-z8qpf 1/1 Running 2 (8d ago) 8d
service/grafana NodePort 10.68.99.199 <none> 3000:30780/TCP 8d
[root@node1 rook]#
grafana访问地址如下,默认用户名和密码均为admin。登录后需要修改密码。
http://node_ip:30780

8.5配置grafana监控ceph模板
通常下面模板已满足ceph集群监控信息
ceph-cluster模板ID:2842
ceph-osd 模板ID:5336
ceph-pool 模板ID:5342
导入模板ID步骤1

导入模板ID步骤2,输入ID载入即可

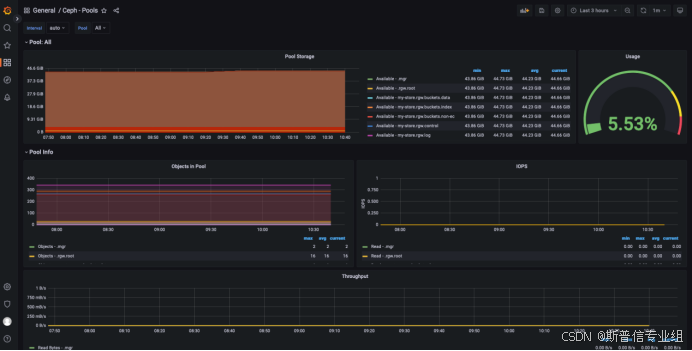
8.6 在grafana上查看ceph集群状态

九.常见故障排查
9.1 ceph集群出现警告mgr modules have recently crashed
解决方法:
# kubectl exec -it rook-ceph-tools-5d8c78cd5b-kr6m9 -n rook-ceph -- bash
bash-4.4$ ceph crash ls-new
ID ENTITY NEW
bash-4.4$ ceph crash archive 2022-09-30T07:59:23.681099Z_31814cfb-a08d-423e-b8dd-b5f0fd4fb097
bash-4.4$
bash-4.4$ ceph health
HEALTH_OK
bash-4.4$
9.2 ceph集群出现警告 mons are allowing insecure global_id reclaim
解决方法:
ceph config set mon auth_allow_insecure_global_id_reclaim false
9.3 rook部署ceph集群某个pod异常或者pending状态
解决问题思路:
1.查看pod log查看容器内部异常日志信息
2.通过describe查看pod事件异常信息
9.4 PVC处于pending状态
解决问题思路:
1.集群中确认是否有OSD
2.CSI配置程序pod未运行或者未响应配置存储的请求
9.5 rook-ceph osd down格式化硬盘重新挂载
// 重新格式化硬盘准备
# yum -y install gdisk
# kubectl -n rook-ceph scale deployment rook-ceph-operator --replicas=0
deployment.apps/rook-ceph-operator scaled
// 查询osd的状态,找到要移除的osd id
# ceph osd status
// ID为2的osd标识为out,此时会进⾏元数据的同步
# ceph osd out osd.2
# ceph osd purge 2 --yes-i-really-mean-it
// 删除ID为2的OSD
# ceph auth del osd.2
entity osd.2 does not exist
// 删除相关osd节点的deployment
# kubectl delete deploy -n rook-ceph rook-ceph-osd-2
deployment.apps "rook-ceph-osd-2" deleted
// 删除硬盘分区信息
# sgdisk --zap-all /dev/sdb
Creating new GPT entries.
GPT data structures destroyed! You may now partition the disk using fdisk or
other utilities.
// 清理硬盘数据(hdd硬盘使用dd,ssd硬盘使用blkdiscard,二选一)
# dd if=/dev/zero of="/dev/sdb" bs=1M count=500000 oflag=direct,dsync
500000+0 records in
500000+0 records out
524288000000 bytes (524 GB) copied, 258.146 s, 2.0 GB/s
// ssd硬盘选择此命令
# blkdiscard /dev/sdb
// 删除原osd的lvm信息(如果单个节点有多个osd,那么就不能用*拼配模糊删除,而根据lsblk -f查询出明确的lv映射信息再具体删除)
ls /dev/mapper/ceph-* | xargs -I% -- dmsetup remove %
rm -rf /dev/ceph-*
lsblk -f
// 恢复rook的operator,使检测到格式化后的osd硬盘,osd启动后ceph集群会自动平衡数据
kubectl -n rook-ceph scale deployment rook-ceph-operator --replicas=1
deployment.aps/rook-ceph-operator scaled
十.ceph集群常用命令
10.1查看集群状态命令
ceph -v //查看ceph的版本
ceph -s //查看集群的状态
ceph -w //监控集群的实时更改|查看正在操作的动作
ceph osd tree #查看osd目录树
ceph osd df //详细列出集群每块磁盘的使用情况|查看osd的使用信息
ceph osd stat #查看osd状态
ceph mon stat //查看mon状态
ceph mds stat # 检查 MDS 状态
ceph osd find osd.o//查看osd.0节点ip和主机名
ceph auth get client.admin # 查看ceph授权信息
10.2 Ceph mds命令
ceph mds
ceph mds stat #查看msd状态
ceph mds dump #msd的映射信息
ceph mds rm 0 mds.node1#删除一个mds节点
10.3 ceph osd命令
ceph osd stat #查看osd状态
ceph osd dump #osd的映射信息
ceph osd tree#查看osd目录树
ceph osd down 0 #down掉osd.0节点
ceph osd rm 0#集群删除一个osd硬盘
ceph osd crush remove osd.4#删除标记
ceph osd getmaxosd#查看最大osd个数
ceph osd setmaxosd 10#设置osd的个数
ceph osd out osd.3#把一个osd节点逐出集群
ceph osd in osd.3#把逐出的osd加入集群
ceph osd pause#暂停osd (暂停后整个集群不再接收数据)
ceph osd unpause#再次开启osd (开启后再次接收数据)
ceph osd df //查看osd的使用信息
要定位对象,只需要对象名和存储池名字即可,例如:
ceph osd map {poolname} {object-name}
10.4 ceph pg命令
ceph pg stat#查看pg状态
ceph pg dump#查看pg组的映射信息
ceph pg map 0.3f#查看一个pg的map //查看单个pg和osd的映射信息
ceph pg 0.26 query#查看pg详细信息
ceph pg dump --format plain#显示一个集群中的所有的pg统计
ceph pg {pg-id} query //获取pg的详细信息
10.5 ceph osd pool命令
ceph osd lspools #查看ceph集群中的pool数量
创建和删除存储池
ceph osd pool create myPoolName 100#创建一个pool 这里的100指的是PG组
ceph osd pool delete myPoolName myPoolName --yes-i-really-really-mean-it #删除,集群名字需要重复两次
rados df#显示集群中pool的详细信息
ceph osd pool get data pg_num #查看data池的pg数量
ceph osd pool set data target_max_bytes 100000000000000#设置data池的最大存储空间为100T(默认是1T)
ceph osd pool set data size 3 #设置data池的副本数是3
ceph osd pool set data min_size 2 #设置data池能接受写操作的最小副本为2
ceph osd pool set data pg_num 100#设置一个pool的pg数量
ceph osd pool set data pgp_num 100#设置一个pool的pgp数量
ceph osd pool ls //查看集群中的存储池名称
ceph osd pool ls detail //查看池的的详细信息
ceph osd pool stats //查看池的IO情况
10.6 rados命令
rados lspools#查看ceph集群中有多少个pool (只是查看pool)
rados df #查看存储池使用情况:多少个pool,每个pool容量及利用情况
rados mkpool test#创建一个pool,名字:test
rados create testobject -p testpool#testpool中创建一个对象testobject
rados rm test-object-1 -p test#删除(test存储池的)一个对象object
rados -p test ls #查看存储池test的对象