NeurIPS'24 | FlowDCN:基于可变形卷积的任意分辨率图像生成模型
本文分享阿里妈妈智能创作与AI应用团队在任意分辨率图像生成模型的最新工作,基于该项工作整理的论文已被NeurIPS2024录用,欢迎阅读交流。
论文:Exploring DCN-like Architectures for Fast Image Generation with Arbitrary Resolution
作者:Shuai Wang, Zexian Li, Tianhui Song, Xubin Li, Tiezheng Ge, Bo Zheng, Limin Wang
论文地址:https://arxiv.org/pdf/2410.22655
代码地址:https://github.com/MCG-NJU/FlowDCN
模型地址:https://huggingface.co/wangsssssss/FlowDCN
1. 背景
在电商场景的创意图片生成任务中,文生图基础模型的多尺寸生成能力对于下游任务十分重要,例如背景生成、可控生成、尺寸扩展、模特生成等等。现有的文生图基础模型通常基于Unet或Transformer架构,计算复杂度高,训练收敛慢,且对任意尺寸生成不够友好,容易出现全局语义问题,在一定程度限制了多尺寸商品坑位的素材生成。由此,轻量高效灵活的模型基础架构是一个值得探索的研究方向。
基于此,本文介绍了我们和南京大学王利民教授课题组合作完成的“基于稀疏计算的可变形卷积结构”,提出了一种卷积变种:组间多尺度可变形卷积Groupwise-MSDCN。可变形卷积的复杂度为线性,相较平方复杂度的Attention计算效率更高,相较常规卷积的动态性更强、性能更优。使用组间多尺度可变形卷积作为基本构建块,我们提出了可以进行任意分辨率图像生成的FlowDCN模型,相比于主流的Transformer架构,在更小的参数量和计算量下实现了更佳的模型效果。
2. 基本概念
2.1 DCN(Deformable Convolution Network)架构的特点
DCN架构稀疏、计算效率高:由于Transformer中的attention block的计算复杂度与token数的平方成正比,所以在高分辨率场景下其计算效率较低,推理延迟较高。
DCN架构天然可以实现任意分辨率推理:现有基于Transfomer的生成模型对于多分辨率生成的拓展性比较差,不经过针对性训练的情况下难以胜任。
DCN架构的空间结构理解能力强:DCN作为卷积网络中性能一直遥遥领先的分支结构,可以在空间上用动态权重进行自适应采样,有着进一步挖掘的潜力。
2.2 DCN(Deformable Convolution Network)结构简介
DCNv2只有基于Deformable Field的自适应采样,DCNv3进一步引入了动态权重来增强表征能力,在DCNv4中,通过对反向传播算子的优化,模型的训练速度也得到了显著提升。
现有的DCNv3/DCNv4通过Linear层预测Deformable Field和Dynamic Field,其中W为该层权重,b为偏置。
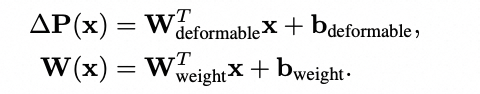
其中Dynamic Field通过和特征自身位置以及卷积的初始位置整合,预测到需要采样的位置,如下公式描述,采样之后通过对应的动态权重进行聚合,因此相比于Attention计算相对稀疏。
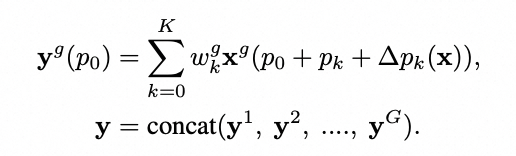
不同组采样的特征通过concat进行特征维度上的聚合, 其中y^g是第g组采样的特征。
2.3 Linear-based FlowMatching 框架简介
Linear-based flow matching(rectified flow)采用线性混合高斯噪声和干净的样本,得到噪声样本,其中xt为混合后的噪声样本,x为干净样本,eps为高斯噪声,t为混合的权重。
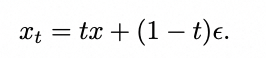
噪声样本xt送入网络预测速度估计,进行训练,生成时可以使用euler或者heun solver进行sampling:
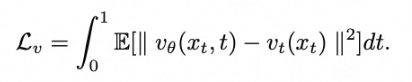
这里需要注意,本文只使用Linear Flow方便对比。
3. 方法介绍
3.1 组间多尺度可变形卷积Groupwise Multi-ScaleDCN
Deformable Field 解耦成尺度和方向
为了实现推理时可根据输入尺寸调整采样的尺度,我们将Deformable Field解耦成尺度和方向两个部分,通过Linear分别进行尺度预测和方向预测,
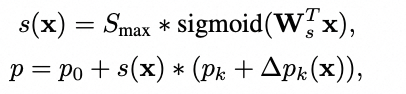
DCN实现组间多尺度
将尺度解偶出来可以使得不同组具有不同的尺度先验,从而可以实现组间的多尺度。多尺度聚合作为CV任务中的重要技巧,可以显著提升网络性能。原始的DCNv3/DCNv4对于同一个DCN卷积使用相同的dilation,缺少多尺度的能力,对于分类任务可能影响较小;而检测分割任务通常会显式构造FPN,因此影响不明显。
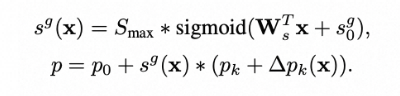
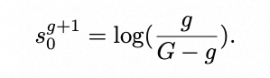
3.2 整体网络结构 FlowDCN-Arch
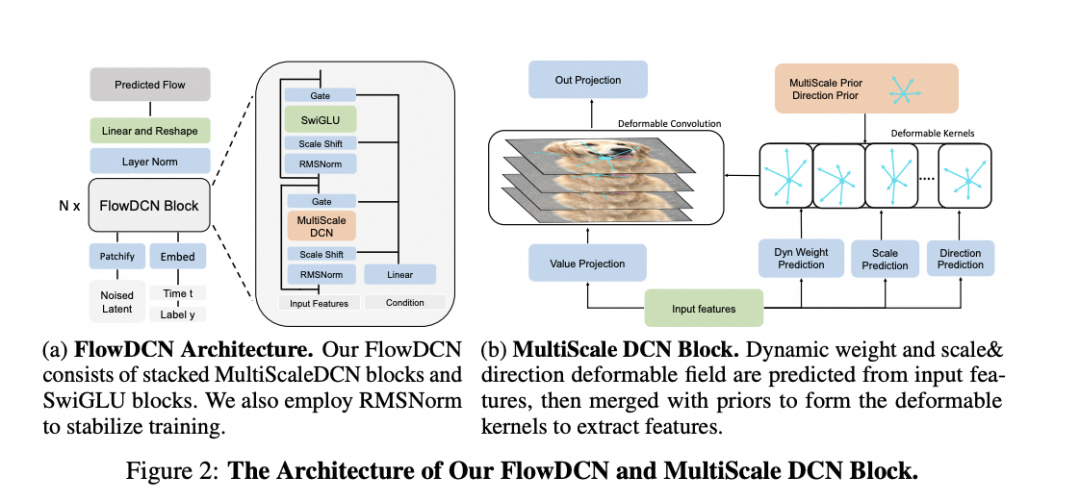
参考DiT实验设计思路,我们将Attention block换成MSDCN,同时参考Llama的结构,使用了RMSnorm和SwiGLU。我们在不使用RMSnorm和SwiGLU的消融实验中,效果也是显著超越SiT/DiT。
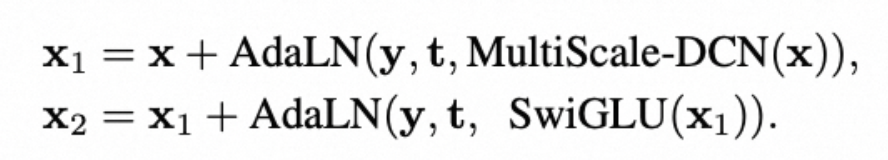
3.3 实现任意分辨率推理
模型可以直接输入任意分辨率,但是受限于感受野,容易会生成全局语义不一致的图片。因此我们提出了一个最大尺度调节的算法:根据分辨率调整一些block的最大尺度Smax,通过增加感受野来实现全局语义的一致性。
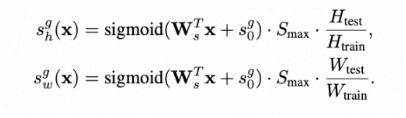
4. 实验结果
我们在训练中的所有设置完全按照SiT开源的配置,没有使用任何多尺度训练以及lognorm技巧,推理也是最简单的CFG。
FlowDCN在高效任意分辨率生成方面具有显著优势,因为它仅需要线性的时间和内存复杂度。通过可视化比较,FlowDCN即使在极小的采样步骤下,也能展现出明显更好的视觉质量。实验结果表明,FlowDCN在分辨率外推能力上达到了与高度定制方法相当的水平,突显了其在各种分辨率下生成高质量图像的潜力。
在256x256的ImageNet基准测试中,仅在1.5M训练步骤下,FlowDCN-XL/2使用欧拉求解器和无分类器引导,实现了2.13的FID和SoTA4.30的sFID。
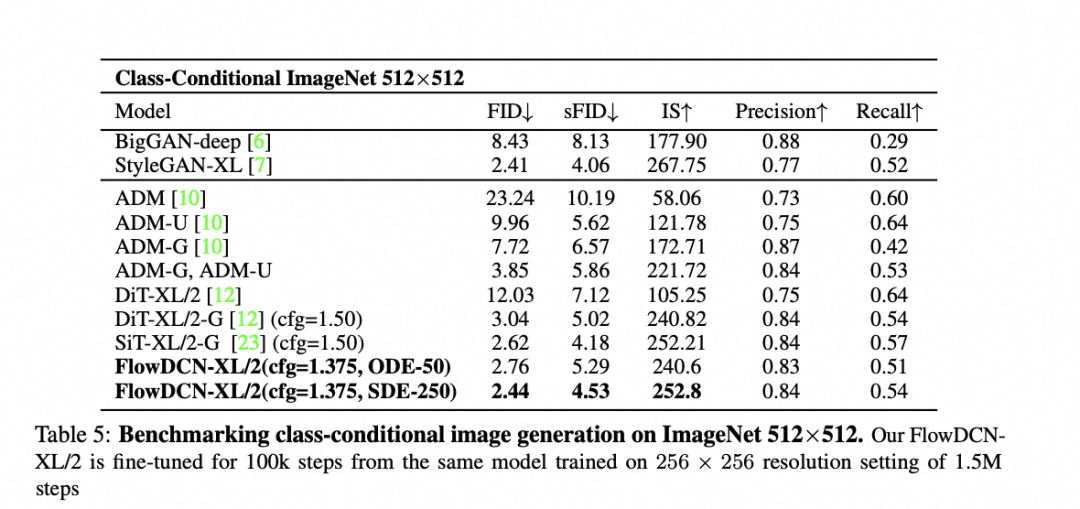
在512x512的ImageNet基准测试中,仅在100K微调步骤下,FlowDCN-XL/2使用欧拉求解器和无分类器引导,实现了2.44的FID和4.53的sFID。
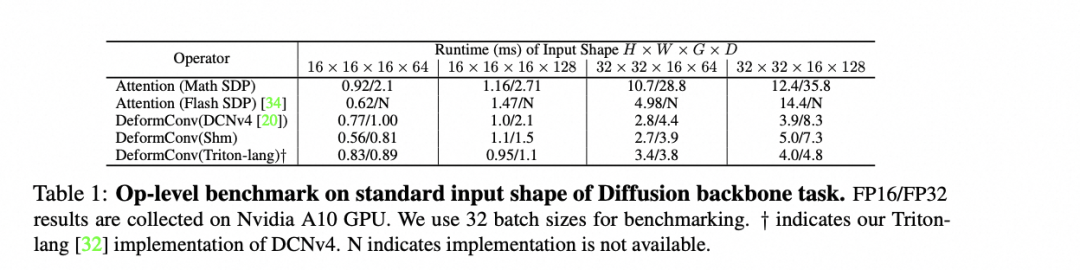
4.1 DCN的Triton实现
我们在torch2.0引入了编译,并使用Triton对基本所有的算子进行了重写。虽然单个算子性能较CUDA仍有微小差距,但是可以进行model级别的统一优化,且多类型显卡队列下Triton在线编译会更为方便。我们使用Triton参考cuda版的DCNv4进行复现,实现了相近的forward性能,backward过程则受限于Triton不能编译到通信原语级别而无法彻底对齐。
4.2 ImageNet256 400K 训练
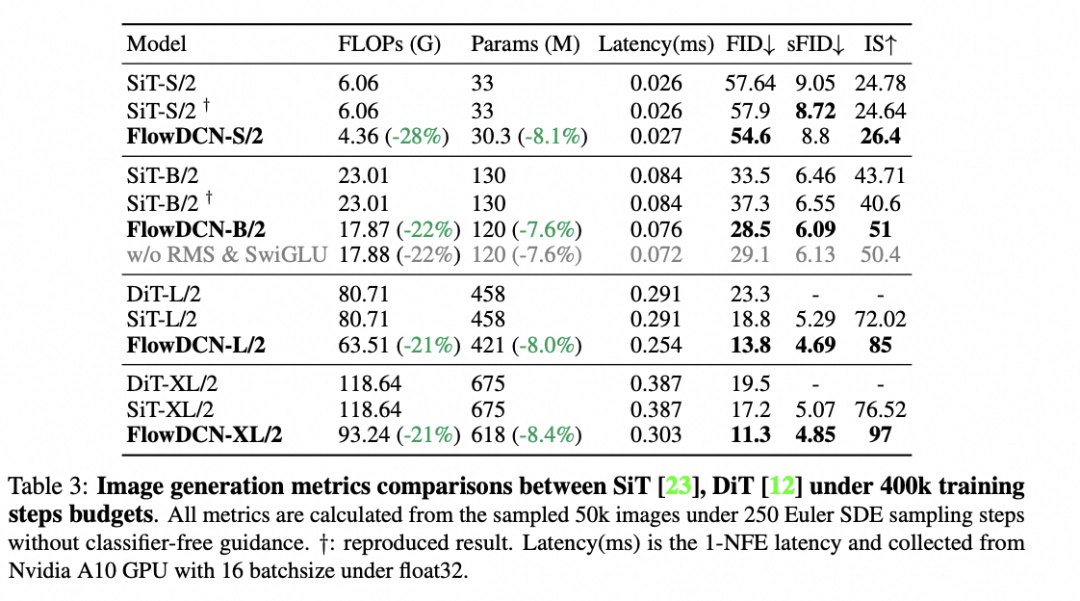
如上图所示,在256这个不能完全发挥DCN优势的分辨率上,FlowDCN对比SiT和DiT仍有明显的性能提升。在Base模型上,即便去掉SwiGLU&RMSnorm会掉一个点,但较SiT还是有约5个点FID的显著提升。
4.3 ImageNet256 结果
FlowDCN使用SiT/DiT 20%的训练iteration就能达到相同效果。
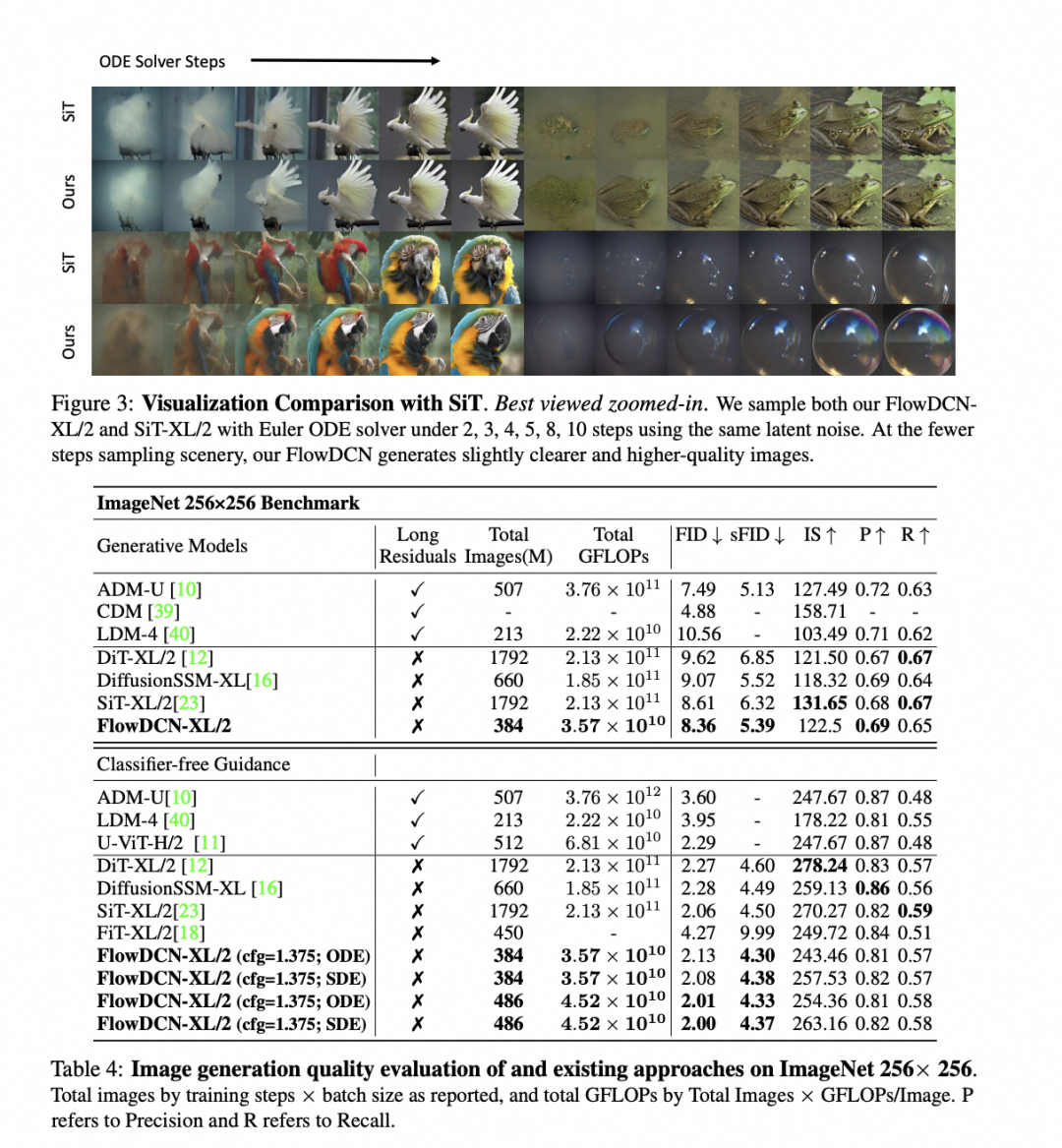
4.4 ImageNet512 结果
在ImageNet256预训练模型的基础上finetune了100k iters,FID便可以达到2.44,性能超过常规训练的所有diffusion模型。
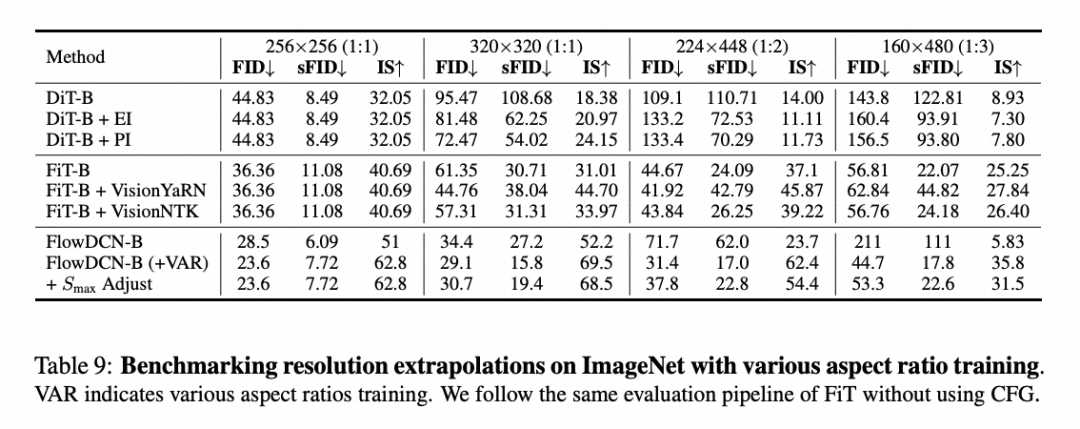
4.5 任意分辨率实验
实验结果表明,常规训练的结果已经能够与专门针对任意分辨率优化的FiT模型相媲美。当我们进一步采用FiT的多尺度训练方法时,性能更是显著超越了FiT。有趣的是,尽管Smax模型在性能指标上有所下降,但从实际可视化效果来看,其表现却更为出色。

5. 总结展望
本文提出了一种新的方法来解耦可变形卷积的比例和方向预测,从而产生一个组间多尺度可变形卷积块,使高效的多尺度特征聚合成为可能。结合组间多尺度可变形卷积和Linear-based flow matching提出的FlowDCN,参数量相比DiT/SiT减少8%,单次推理GFlops减少20%,参数量更少,计算量更稀疏。在ImageNet 256 benchmark上,相比于SiT模型(7M steps & 256 batch size,FID 2.06 & sFID 4.50),仅使用20%总训练数据便可以达到相近性能(FID 2.08 & sFID 4.38),另外增加400K训练步数时可以达到FID 2.00 & sFID 4.37(总共2M step)。在ImageNet 512 benchmark上,仅基于ImageNet 256预训练模型微调100k steps,便取得了FID 2.44 & sFID 4.53的效果,显著超越现有模型。不使用针对任意分辨率的训练,可以取得和该领域专门设计算法FiT相近的性能,通过针对性训练,可以大幅度超越FiT。
针对高效任意分辨率生成问题,我们在 ImageNet 数据集上探索了基于稀疏计算的可变形卷积结构,相比于主流的Transformer架构,在更小的参数量和计算量下实现了更佳的模型效果。在未来,我们计划尝试CNN与Transformer的混合架构来进行文生图基础模型的拓展。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入,一起拥抱AIGC时代!感兴趣的同学欢迎投递简历加入我们。
📮 简历投递邮箱:alimama_tech@service.alibaba.com
END

也许你还想看
🔥《计算机视觉 in 阿里妈妈》文章合集
丨视频解说生成算法及在电商广告中的应用
丨化繁为简,精工细作——阿里妈妈直播智能剪辑技术详解
丨筑基砥柱:EcomXL-万相实验室AIGC电商基础模型
丨上下文驱动的图上文案生成
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~