Bert+CRF的NER实战
CRF(条件随机场-Conditional Random Field)
原始本文:我在北京吃炸酱面
标注示例:
- 我O
- 在O
- 北B-PLA
- 京I-PLA
- 吃O
- 炸B-FOOD
- 酱I-FOOD
- 面I-FOOD
CRF:
目的:提出一些不可能出现的预测组合(例如I-PLA不能出现在B-PLA前面)
核心:11*11的概率转移矩阵。其中11是预测的标签的个数(也包含CLS和SEP标签)
原理

- x是我们的输出文本,也叫观测序列。
- y是输出标签,也称状态序列
- 特点1:y与每个x都相关,但是一般我们取前后十个x
- 特征2:y与相邻的两个y相关。
公式

- 公式说的是已知观察序列x,求任意状态序y的发生概率。
 :是转移特征函数,它主要衡量相邻状态变量之间的影响,转移特征函数带了x参数,表明它是可以与观测x进行关联的;(基于上一个y和当前x如何得到当前y)
:是转移特征函数,它主要衡量相邻状态变量之间的影响,转移特征函数带了x参数,表明它是可以与观测x进行关联的;(基于上一个y和当前x如何得到当前y) :是状态特征函数,它主要衡量观测序列对状态变量的影响,(x对y的影响);
:是状态特征函数,它主要衡量观测序列对状态变量的影响,(x对y的影响);- λ和μ是对两个函数进行加权求和。
- exp 是指数势函数,主要用于定义图模型中的概率分布函数;
- Z是规范化因子,确保式子是一个概率。
维特比解码
根据特征函数及其权重,使用维特比算法(一种寻找最优路径的动态规划算法),找到一条概率最高的标签路径。
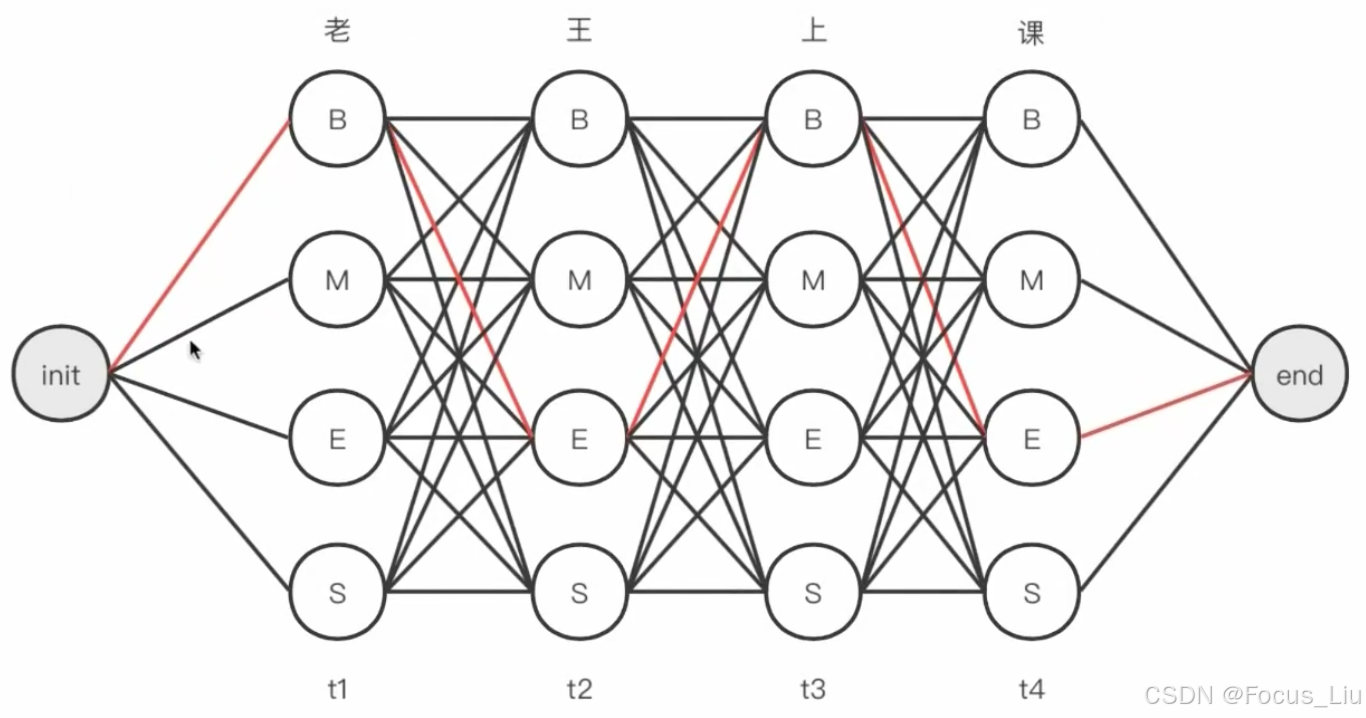
- 计算所需数据:①bert的输出(每个位置属于n个类别的概率)②CRF转移矩阵(标签之间的转移得分),不会出现转换的pair值为为负无穷。
- 计算示例:例如“我爱中国”在计算第三个位置预测为“中”的score:3_地点_score=3_预测为地点的logit+max(上一次)
- 个人总结:其实是算所有可能出现的logit的最大可能。
记录
- 输入数据是要经过PAD到最大长度的,所以标签也有单独有一个PAD类别。
- 转移矩阵:可以理解为一个标签后面连接另一个标签的概率。
- 纯Bert+Softmax也可以做NER,用NER替换softmax效果更好(CRF是全局无向转移概率图,能有效考虑词前后的关系)。
- BERT+CRF 与 Bert+Bi-LSTM+CRF:加Bi-LSTM没有提升,性能反而下降。
- 训练BERT+CRF时,CRF所需要的的学习率要比BERT大约100倍,这样能带来更好的效果。
- 之前公司-NER:双向LSTM+CRF
- 现在公司-NER:Bert+CRF -> 蒸馏 ->小Bert+CRF
- NER架构演变:HMM->CRF->BiLSTM+CRF->Bert+CRF
- 特征函数:分成转移特征函数和状态特征函数,特征函数的本质是多个and的返回值为0或1的函数。
参考资料:
- 玩转NLP67:CRF模型_哔哩哔哩_bilibili