P3打卡-pytorch实现天气识别
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
1.检查GPU
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

2.查看数据
data_dir="data/weather_photos"
data_dir=pathlib.Path(data_dir)
data_paths=list(data_dir.glob('*'))
classNames=[str(path).split('\\')[2] for path in data_paths]
classNames
3.数据可视化
import matplotlib.pyplot as plt
from PIL import Image
image_floder='data/weather_photos/cloudy'
image_files=[f for f in os. listdir(image_floder) if f.endswith(('.jpg','.png','.jpeg'))]
fig,axes=plt.subplots(3,8,figsize=(16,6))
for ax,img_file in zip(axes.flat,image_files):
img_path=os.path.join(image_floder,img_file)
img=Image.open(img_path)
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()
4.划分数据集
total_datadir='./data/weather_photos'
train_transforms=transforms.Compose(
[
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
]
)
total_data=datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
train_size=int(0.8*len(total_data))
test_size=len(total_data)-train_size
train_dataset,test_dataset=torch.utils.data.random_split(total_data,[train_size,test_size])
train_dataset,test_dataset
import torch.utils
import torch.utils.data
batch_size=32
train_dl=torch.utils.data.DataLoader(train_dataset,batch_size,shuffle=True,num_workers=1)
test_dl=torch.utils.data.DataLoader(test_dataset,batch_size,shuffle=True,num_workers=1)
for X,y in test_dl:
print("shape of X:[N,C,H,W]:",X.shape)
print("shape of y:",y.shape,y.dtype)
break

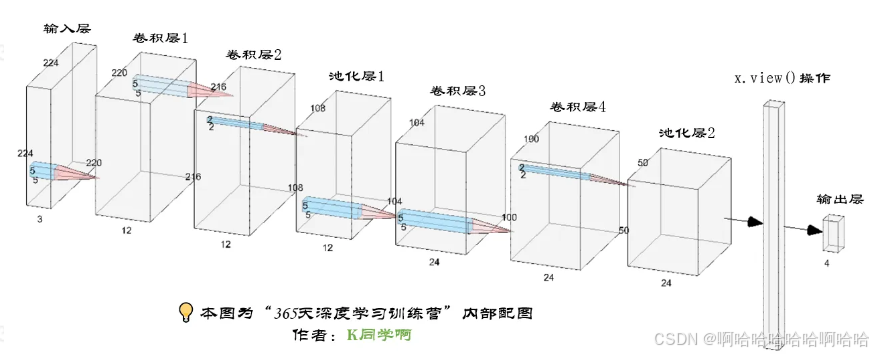
5.构建模型
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool1 = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.pool2 = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(24*50*50, len(classNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool1(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool2(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model
6.编译及训练模型
loss_fn=nn.CrossEntropyLoss()
learn_rate=1e-3
opt=torch.optim.SGD(model.parameters(),lr=learn_rate)
def train(dataloader,model,loss_fn,optimizer):
size=len(dataloader.dataset)
num_batches=len(dataloader)
train_loss,train_acc=0,0
for X,y in dataloader:
X,y=X.to(device),y.to(device)
pred=model(X)
loss=loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc+=(pred.argmax(1)==y).type(torch.float).sum().item()
train_loss+=loss.item()
train_loss/=num_batches
train_acc/=size
return train_acc,train_loss
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset)
num_batches=len(dataloader)
test_loss,test_acc=0,0
with torch.no_grad():
for imgs,target in dataloader:
imgs,target=imgs.to(device),target.to(device)
target_pred=model(imgs)
loss=loss_fn(target_pred,target)
test_loss+=loss.item()
test_acc+=(target_pred.argmax(1)==target).type(torch.float).sum().item()
test_loss/=num_batches
test_acc/=size
return test_acc,test_loss
epochs=20
train_loss=[]
train_acc=[]
test_loss=[]
test_acc=[]
for epoch in range(epochs):
model.train()
epoch_train_acc,epoch_train_loss=train(train_dl,model,loss_fn,opt)
model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,model,loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Finished Training')
7.结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
总结:
1.导入数据
- 第一步:使用
pathlib.Path()函数将字符串类型的文件夹路径转换为pathlib.Path对象。 - 第二步:使用
glob()方法获取data_dir路径下的所有文件路径,并以列表形式存储在data_paths中。 - 第三步:通过
split()函数对data_paths中的每个文件路径执行分割操作,获得各个文件所属的类别名称,并存储在classeNames中 - 第四步:打印
classeNames列表,显示每个文件所属的类别名称。
2.神经网络数据shape变化过程