工业大数据分析算法实战-day07
文章目录
- day07
- 概率图模型
- 朴素贝叶斯(Naive Bayes)
- 贝叶斯网络(Bayesian Network)
- 一般图模型
- 生成式和判别式模型
- 图模型结构与模型推理
- 集成学习
- Boosting算法
- Stacking算法
day07
今天是第七天,昨日主要针对是第三章节中的决策树算法、支持向量机、隐马尔可夫模型进行阐述,介绍了算法的优化点以及核心参数,今天阐述第9小节概率图模型与贝叶斯方法、第10小节集成学习
概率图模型
概率图模型简称图模型,是一种用图结构来描述多元随机变量之间条件独立关系的概率模型。概率图模型简单可以分为如下示例:

图模型分成两种:有向图 和 无向图。
-
有向图模型(Directed Graphical Models)
- 特点:关系有方向,比如“谁影响谁”或者“谁依赖谁”。
- 例子:你准备考试,学习好不好可以被下面的因素影响:
- 节点1:你的学习时间(直接影响)
- 节点2:你的睡眠质量(影响学习时间)
- 节点3:你的考试成绩(依赖学习时间)这些关系之间有方向,比如:“睡眠质量 → 学习时间 → 考试成绩”。
- 这种有方向的依赖关系,就属于有向图模型,像贝叶斯网络就是这样的模型。
- 进一步扩展:动态贝叶斯网络(DBN):这就像看电视连续剧,每一集都会影响下一集的情节。
- 隐马尔可夫模型(HMM):你每天心情的变化是“隐藏的”(别人看不到),但你每天的表现(比如脸色好不好)是可以观察到的。大家通过观察你的表现推测你的心情,这就是HMM的原理。
-
无向图模型(Undirected Graphical Models)
- 特点:关系没有方向,强调“谁和谁之间有关联”,但不会说谁影响谁。
- 例子:假设有个微信群里几个人聊天:
- 小明和小红聊得很多,小红和小李也聊得很频繁。这种“谁和谁关系好”就是一种无向的关系,因为大家只是互相联系,没有明确的影响方向。
- 这种关系用无向图表示,就属于马尔可夫网络。
- 吉布斯随机场:想象一张床上放着很多沙包,每个沙包的重量会影响周围沙包的平衡。这种影响关系就是一种无向关系。
- 条件随机场(CRF):比如看一段话,判断每个词的词性。每个词的判断依赖于它周围的词,但没有明确的方向性。
朴素贝叶斯(Naive Bayes)
- 基本概念: 朴素贝叶斯是一种简单的概率分类方法,它基于贝叶斯定理,假设特征之间是“独立”的。也就是说,在做出分类决策时,朴素贝叶斯认为每个特征对于分类的贡献是相互独立的,尽管现实中这些特征可能是有关系的。
- 通俗解释: 假设你要判断一封邮件是否是垃圾邮件(垃圾邮件或正常邮件是分类目标)。你可以根据邮件中的特征(如是否包含“优惠”、“免费”等关键词)来进行判断。朴素贝叶斯做出的假设是:每一个特征(比如是否含有“优惠”这个词)对是否是垃圾邮件的影响是独立的。虽然实际情况可能是这些词语是相互关联的,但朴素贝叶斯忽略了这些关联,直接将每个词的影响单独计算,再加起来得出结论。
- **现实例子:**每天根据天气、气温、湿度等因素判断是否带伞。朴素贝叶斯会假设天气、气温、湿度等因素之间的影响是独立的,即使在现实中这些因素可能有联系。
贝叶斯网络(Bayesian Network)
- 基本概念: 贝叶斯网络是一种图形化的模型,它通过有向图来表示变量之间的条件依赖关系。每个节点代表一个随机变量,边表示变量之间的依赖关系。它利用贝叶斯定理进行推理,计算某些变量的条件概率。
- 通俗解释: 贝叶斯网络可以看作是对复杂系统中变量之间关系的“图示化”。假设你有一张图,节点表示不同的因素,比如天气、交通状况、出行计划等。箭头指示了这些因素之间的因果关系。通过贝叶斯网络,你可以根据已知的某些信息(比如今天下雨了)来推断其他未知的信息(比如是否会堵车)。
- **现实例子:**在计划外出时,天气(下雨或不下雨)会影响你是否需要带伞,而交通状况可能又会受到天气的影响。贝叶斯网络通过图形化的方式帮助你推理,给出最合理的决策。
一般图模型
一般图模型是概率图模型的一个更为广泛的概念,它包括不同类型的图结构和推理方法,主要包括以下几种:
-
PGM 是一种用图结构表示随机变量和它们之间条件依赖关系的模型,贝叶斯网络和马尔可夫网络(MRF)都是PGM的特殊形式。PGM 用图来表达复杂系统的依赖关系,利用概率进行推理。
- 通俗解释: 想象一个大企业的管理结构图,每个员工代表一个随机变量,边表示员工之间的依赖关系(例如,经理与下属的关系)。通过PGM,你可以通过已知的某些信息(比如某个经理的决策)推断其他未知的信息(如员工的表现)。
-
马尔可夫随机场是一种无向图模型,主要用于描述变量之间的相互依赖关系。在MRF中,图中的节点代表随机变量,而边表示这些变量之间的直接依赖关系。-
- 通俗解释: MRF 通常用于处理“局部依赖”的情况,即每个变量的状态只依赖于它相邻的变量。例如,在图像处理任务中,每个像素的颜色可能与其相邻像素的颜色相关,MRF可以用来建模这种局部依赖关系。
- **现实例子:**在图像分割任务中,MRF 可以用来建模像素的标签(比如前景或背景)的依赖关系,假设相邻像素的标签更可能相同。
-
条件随机场是MRF的一种变体,主要用于有标签的序列数据的标注问题(如文本标注、语音识别等)。CRF通过条件概率模型来建模变量之间的依赖关系,特别强调在给定输入数据条件下输出的依赖性。
- 通俗解释: CRF主要用来处理序列问题,像是在做自然语言处理时,识别一个句子中的每个词的词性标签(名词、动词等)。在CRF模型中,给定了输入句子的上下文信息,每个词的标签依赖于它周围词的标签。
- **现实例子:**在命名实体识别(NER)任务中,CRF用于从句子中识别出人物、地点等实体。假设“李华”是一个人名,CRF会通过上下文推断出“李华”可能是人名,而不是其他实体。
生成式和判别式模型
假设你有一组图片,目标是将图片分类为“猫”或“狗”。
-
生成模型(如朴素贝叶斯)会试图描述**“猫”和“狗”**是如何生成这些图片的特征的(例如,猫的耳朵和狗的尾巴的特征),它建模的是图像的联合分布 P(猫,图像)P(猫, 图像)P(猫,图像) 和 P(狗,图像)P(狗, 图像)P(狗,图像),并且可以通过贝叶斯公式推断每张图片属于“猫”还是“狗”。
-
判别模型(如逻辑回归)会直接关注给定一张图片,如何预测它是猫还是狗。它只关心 P(猫∣图像)P(猫 | 图像)P(猫∣图像) 和 P(狗∣图像)P(狗 | 图像)P(狗∣图像),即在已知图像特征的条件下,如何区分标签。
-
生成模型关注 联合分布 P(A,B)P(A, B)P(A,B),试图模拟数据和标签的共同生成过程。
-
判别模型关注 条件分布 P(A∣B)P(A | B)P(A∣B),直接根据输入预测输出标签。
图模型结构与模型推理
图模型结构指的是概率图模型中变量如何通过边连接起来,表示它们之间的依赖关系。不同的图结构(如有向图、无向图)适合不同类型的任务。
模型推理是通过已知的信息来推断未知的信息。在概率图模型中,推理通常是通过计算条件概率分布来实现的。具体的推理方法可以包括:
- 边际推理:计算某些变量的边际概率(即忽略其他变量)。
- 条件推理:计算某些变量在给定其他变量条件下的概率。
- 最大后验推理(MAP推理):给定某些观测值,推断最有可能的隐变量值。
通俗解释: 图模型结构就像是你在生活中做决策时,如何把不同的因素和它们之间的依赖关系通过图表表示出来。模型推理则是利用这些图表计算出你需要的信息,比如你知道一些条件下其他变量的可能性,或者你想通过已知条件推测其他未知的信息。
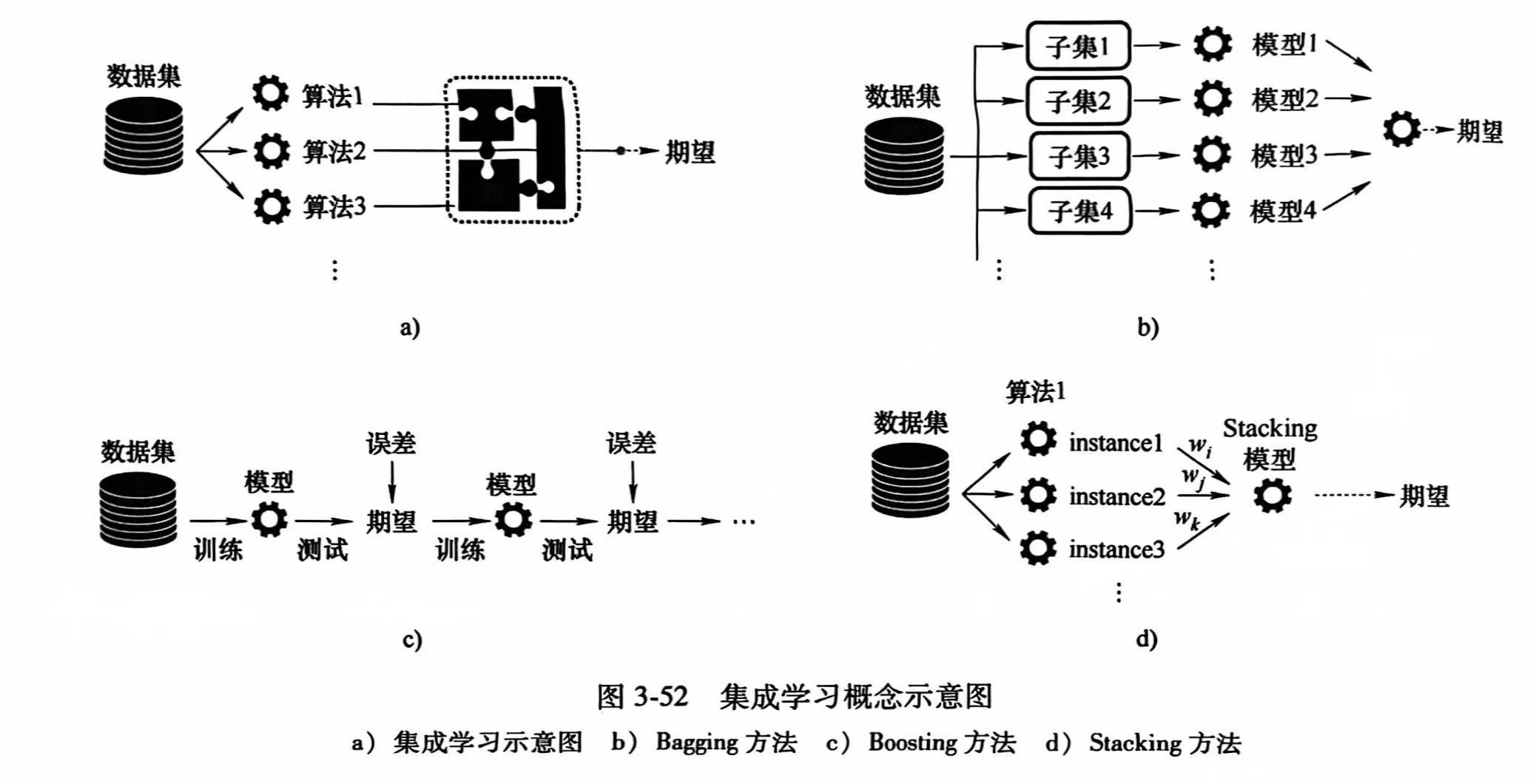
集成学习
构建多个学习器来完成任务,主要有以下三类:Bagging、Boosting、Stacking
| 方法 | 思想 | 具体步骤 | 代表算法 | 优点 | 缺点 |
|---|---|---|---|---|---|
| Bagging | 通过将多个模型训练在不同的随机子集上,降低方差,减少过拟合。 | 从训练数据中有放回地抽取多个子集,使用不同子集训练多个相同的模型,对模型预测结果进行平均(回归)或投票(分类)。 | 随机森林(Random Forest) | 减少模型方差,降低过拟合风险,对噪声有鲁棒性。 | 训练时间较长,消耗计算资源,需要多个独立的模型进行训练。 |
| Boosting | 逐步训练模型,每次着重关注前一个模型的错误,减少偏差。 | 训练初始弱模型,增加前一模型错误样本的权重,训练下一个模型,迭代训练,最终加权所有模型的预测。 | AdaBoost, Gradient Boosting, XGBoost | 显著提高准确性,特别适合弱模型,可以减少偏差,提高整体性能。 | 对噪声和异常值敏感,训练时间长,计算复杂。 |
| Stacking | 将不同类型的模型组合,通过一个元模型进一步学习如何合并预测结果。 | 训练多个不同类型的基础模型,将基础模型的预测结果作为新特征输入元模型,使用元模型做最终预测。 | 常见组合:逻辑回归+决策树+神经网络等 | 灵活结合不同类型的模型,提升性能,能够发挥不同模型的优势,提升准确性。 | 需要大量计算资源,训练时间长,需要调优和选择合适的模型组合。 |
Boosting算法
可分为AdaBoost和Gradient Boosting两类:
| 算法 | 关键特点 | 优点 | 缺点 | 提升与优化 |
|---|---|---|---|---|
| AdaBoost | 使用弱学习器(如决策树桩),每个模型集中改进前一个模型的错误。 | 简单易理解,效果直观;能提高弱模型的性能。 | 对噪声和异常值敏感;训练速度慢,可能容易过拟合。 | 主要是通过加权错分类样本来提高性能,但不适应复杂数据和高维数据。 |
| GBM | 基于梯度提升的思想,逐步优化每一棵树来减少模型的误差。 | 适合各种回归和分类任务;对于复杂数据能较好地捕捉非线性关系。 | 训练时间长,计算开销大;对参数选择敏感。 | 引入梯度下降优化和树的增量学习,但计算效率较低,处理大规模数据时可能不够快。 |
| GBDT | 基于GBM,使用决策树作为基础模型,通过梯度提升减少误差。 | 精度高,广泛应用于各类任务;能处理复杂的非线性关系。 | 训练速度慢,计算开销大;容易发生过拟合,调参难度大。 | 引入了更加精细的优化策略,如剪枝和更好的树结构,但计算效率相对较低。 |
| XGBoost | 基于GBDT的优化版本,采用正则化、剪枝、并行计算等技术提升效率。 | 计算速度快,支持并行计算;更强的正则化能力,避免过拟合;对稀疏数据支持较好。 | 参数较多,需要精细调优;对异常值比较敏感。 | 在GBDT基础上加入了正则化、剪枝、并行计算等,提升了训练速度和模型的泛化能力。 |
| LightGBM | 采用基于直方图的决策树算法,支持类别特征,速度快,能处理大规模数据。 | 训练速度极快,适用于大规模数据;内存使用少,支持类别特征处理。 | 调参复杂,可能容易过拟合;对小数据集效果不一定好。 | 使用直方图算法减少了训练时间,支持类别特征,提高了大规模数据集的处理能力,优化了内存使用。 |
Stacking算法
1、训练阶段的数据划分方法:在 Stacking 的训练阶段,我们首先需要训练多个基础模型,然后用这些模型的预测结果来训练一个元模型。为了避免训练过程中的数据泄露,通常会采取以下两种数据划分方式,把数据分成多个小部分,让每个基础模型在不同的子集上训练,确保它们的预测没有泄露训练数据。
- K折交叉验证(K-Fold Cross Validation):
- 我们把所有的训练数据分成 K 份(通常是 5 或 10)。例如,如果 K=5,我们会把数据分成 5 份,每一份轮流作为验证集,其余 4 份作为训练集。
- 在训练每个基础模型时,我们用 K-1 份数据训练它,用剩下的 1 份数据来评估它的表现。这样每一份数据都能作为验证集,确保基础模型的预测是公平的。
- 每个基础模型训练好后,它会在验证集上做预测,这些预测结果会作为新的特征,传递给 元模型(第二层模型)进行训练。
- Out-of-Bag 数据(OOB 数据): 这种方法通常是在 Bagging(例如随机森林)中使用。在训练过程中,每次训练时模型只使用部分数据,剩余的没有被选中的数据叫 OOB 数据,这些数据可以用来评估模型的效果。在 Stacking 中,OOB 数据可以用于生成每个基础模型的预测结果,避免过度拟合。类似于“每次都留下一些数据不参与训练,用这些数据来帮助模型改进”。
2、评分阶段的模型行为:在 评分阶段,我们用训练好的模型来对新的数据进行预测。这个过程的步骤如下,就像是我们把每个模型的预测结果拿出来,交给另一个“总的模型”去做最终的决策,来得到最终的预测结果:
- 基础模型预测:我们先用训练好的 基础模型(第一层模型)来对新的数据进行预测。每个基础模型会给出它自己的预测结果。比如,一个模型预测的是一个数值(回归问题),另一个模型预测的是一个类别标签(分类问题)。
- 元模型预测:然后,我们将这些基础模型的预测结果作为新的输入数据(新特征),传递给 元模型(第二层模型)。元模型会学习如何从这些基础模型的预测结果中选出最合适的预测,最终给出最终结果。
- 如果是回归问题,元模型给出一个数值预测。
- 如果是分类问题,元模型给出一个类别标签或者类别的概率。