python --机器学习(KNN相关)
概念:
- 监督学习(Supervised Learning):利用大量的标注数据来训练模型,模型最终学习到输入和输出标签之间的相关性;
- 半监督学习(Semi-supervised Learning):利用少量有标签的数据和大量无标签的数据来训练网络;
- 无监督学习(Unsupervised Learning):不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类;
- 自监督学习(Self-supervised Learning):利用辅助任务(pretask)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征;
主要分为: 分类问题(是和否) 和 回归问题(具体的数值)
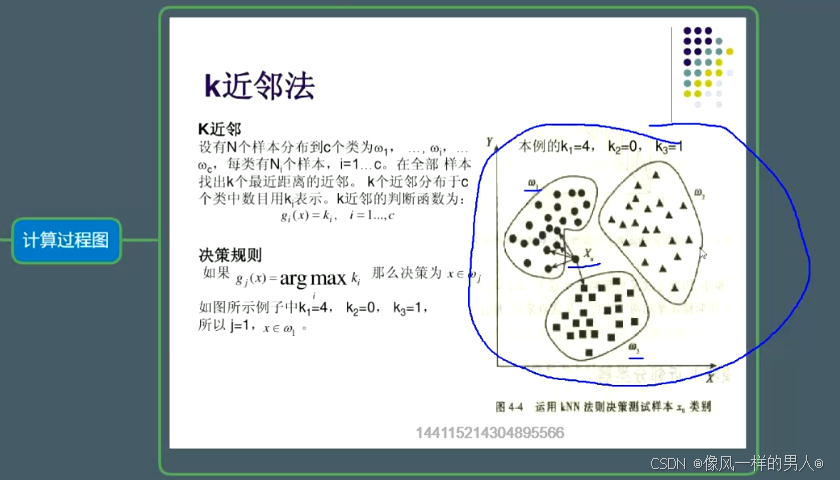
K相邻相关
大白话: 预测数据离训练数据最近的一个,则归类为距离最短的类别;
**](https://i-blog.csdnimg.cn/direct/4d0281c815aa47a4bb52abd0af9ad04f.png)
距离计算: 常见的距离计算(欧式距离, 曼哈顿距离)
优缺点

scikit-learn ==1.6.0
根据电影的武打镜头和接吻镜头预测电影是武打片或爱情片
数据如下:

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier # 分类问题
from sklearn.neighbors import KNeighborsRegressor # 回归问题
movie = pd.read_excel('./1.xlsx', sheet_name=0) # 读表的二维数据
# print(movie)
x_train = movie[['武打镜头', '接吻镜头']] # 获取训练数据 必须为2维的数值
y_train = movie['分类情况'].values # 分类问题一般时一维数据
# print(x_train)
# print(y_train)
# 创建Knn分类器的实例对象,
knn = KNeighborsClassifier() # n_neighbors一般小于20 p:2 欧式距离 1曼哈顿距离
# 训练
knn.fit(x_train, y_train)
# 预测(数据结构必须和训练数据一致) ['武打镜头', '接吻镜头']
x_test = np.array([[50, 3], [60, 2], [4, 20], [35, 2], [40, 0], [45, 2]]) # 预测数
a = knn.predict(x_test) # 预测
print(a) # 预测结果
# 计算得分(分类问题 准确率)
y_test = ['动作片', '动作片', '爱情片', '动作片', '动作片', '动作片'] # 预测的结果
score = knn.score(x_test, y_test)
print(score)
# 画散点图
plt.scatter(movie['武打镜头'], movie['接吻镜头'], c=[0, 0, 1, 0, 1, 1])
plt.scatter(x_test[:, 0], x_test[:, 1])
plt.show()

能明显看出预测的数据和样本数据之间的距离