模型并行分布式训练 Megatron (3) ---模型并行实现
原文链接
0x00 摘要
NVIDIA Megatron 是一个基于 PyTorch 的分布式训练框架,用来训练超大Transformer语言模型,其通过综合应用了数据并行,Tensor并行和Pipeline并行来复现 GPT3,值得我们深入分析其背后机理。
本系列大概有6~7篇文章,通过论文和源码和大家一起学习研究。本文将看看 Megatron 如何处理模型并行。
本系列其他文章为:
[源码解析] 模型并行分布式训练Megatron (1) — 论文 & 基础
[源码解析] 模型并行分布式训练Megatron (2) — 整体架构
0x01 并行Transformer层
在论文篇之中,我们了解到,因为模型越来越大,其尺寸远远超过了处理器的内存限制,因此产生了诸如激活检查点(activation checkpointing)这样的内存管理技术。而模型并行则通过对模型进行各种分片来克服单个处理器内存限制,这样模型权重和其关联的优化器状态就可以分散到多个设备之上。
ParallelTransformerLayer 就是对 Transformer 层的并行实现,所以我们接着分析。
1.1 初始化
ParallelTransformerLayer 初始化方法之中,建立了如下:
生成一个LayerNorm处理输入数据。
生成并行Attention。
生成处理attention输出的LayerNorm。
如果是decoder,则生成一个ParallelAttention。
生成一个并行MLP。
class ParallelTransformerLayer(MegatronModule):
"""A single transformer layer.
Transformer layer takes input with size [b, s, h] and returns an
output of the same size.
"""
def __init__(self, init_method, output_layer_init_method,
layer_number, layer_type=LayerType.encoder,
self_attn_mask_type=AttnMaskType.padding):
args = get_args()
super(ParallelTransformerLayer, self).__init__()
self.layer_number = layer_number
self.layer_type = layer_type
self.apply_residual_connection_post_layernorm \
= args.apply_residual_connection_post_layernorm
self.bf16 = args.bf16
self.fp32_residual_connection = args.fp32_residual_connection
# Layernorm on the input data.
self.input_layernorm = LayerNorm( # 生成一个LayerNorm处理输入数据
args.hidden_size,
eps=args.layernorm_epsilon,
no_persist_layer_norm=args.no_persist_layer_norm)
# Self attention.
self.self_attention = ParallelAttention( # 生成并行Attention
init_method,
output_layer_init_method,
layer_number,
attention_type=AttnType.self_attn,
attn_mask_type=self_attn_mask_type)
self.hidden_dropout = args.hidden_dropout
self.bias_dropout_fusion = args.bias_dropout_fusion
# Layernorm on the attention output
self.post_attention_layernorm = LayerNorm( # 生成处理attention输出的LayerNorm
args.hidden_size,
eps=args.layernorm_epsilon,
no_persist_layer_norm=args.no_persist_layer_norm)
if self.layer_type == LayerType.decoder: # 如果本层是decoder
self.inter_attention = ParallelAttention( # 则生成一个ParallelAttention
init_method,
output_layer_init_method,
layer_number,
attention_type=AttnType.cross_attn)
# Layernorm on the attention output.
self.post_inter_attention_layernorm = LayerNorm(
args.hidden_size,
eps=args.layernorm_epsilon,
no_persist_layer_norm=args.no_persist_layer_norm)
# MLP
self.mlp = ParallelMLP(init_method, # 生成一个并行MLP
output_layer_init_method)

1.2 前向传播
其前向传播方法如下,就是调用各种成员函数进行前向操作。
def forward(self, hidden_states, attention_mask,
encoder_output=None, enc_dec_attn_mask=None,
inference_params=None):
# hidden_states: [b, s, h]
# Layer norm at the beginning of the transformer layer.
layernorm_output = self.input_layernorm(hidden_states) # 对输入进行处理
# Self attention.
attention_output, attention_bias = \ # attention操作
self.self_attention(
layernorm_output,
attention_mask,
inference_params=inference_params)
# Residual connection. 残差连接
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output #norm之后结果作为X
else:
residual = hidden_states # 原始输入X
# jit scripting for a nn.module (with dropout) is not
# trigerring the fusion kernel. For now, we use two
# different nn.functional routines to account for varying
# dropout semantics during training and inference phases.
if self.bias_dropout_fusion: # dropout操作
if self.training:
bias_dropout_add_func = bias_dropout_add_fused_train
else:
bias_dropout_add_func = bias_dropout_add_fused_inference
else:
bias_dropout_add_func = get_bias_dropout_add(self.training)
# re-enable torch grad to enable fused optimization.
with torch.enable_grad():
layernorm_input = bias_dropout_add_func( # dropout操作
attention_output,
attention_bias.expand_as(residual),
residual,
self.hidden_dropout)
# Layer norm post the self attention.
layernorm_output = self.post_attention_layernorm(layernorm_input) # 处理attention输出
if self.layer_type == LayerType.decoder:
attention_output, attention_bias = \
self.inter_attention(layernorm_output,
enc_dec_attn_mask,
encoder_output=encoder_output)
# residual connection
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = layernorm_input
# re-enable torch grad to enable fused optimization.
with torch.enable_grad():
layernorm_input = bias_dropout_add_func(
attention_output,
attention_bias.expand_as(residual),
residual,
self.hidden_dropout)
# Layer norm post the decoder attention
layernorm_output = self.post_inter_attention_layernorm(layernorm_input)
# MLP.
mlp_output, mlp_bias = self.mlp(layernorm_output) # MLP操作
# Second residual connection.
if self.apply_residual_connection_post_layernorm: # 残差操作
residual = layernorm_output
else:
residual = layernorm_input
# re-enable torch grad to enable fused optimization.
with torch.enable_grad():
output = bias_dropout_add_func( # dropout操作
mlp_output,
mlp_bias.expand_as(residual),
residual,
self.hidden_dropout)
return output
0x02 并行MLP
ParallelTransformerLayer 里面包含了 Attention 和 MLP,因为篇幅所限,我们这里主要对MLP进行分析。对于 Attention 则简单研究一下其行切分机制,毕竟我们想了解的是如何进行模型并行,而非深入理解Transformer。

Megatron的并行MLP包含了两个线性层,第一个线性层实现了 hidden size 到 4 x hidden size 的转换,第二个线性层实现了 4 x hidden size 回到 hidden size。具体 MLP 的逻辑如下:

图:具有模型并行性的 MLP。f和g表示和通信切块相关的操作,其是共轭的。f 的前向传播是一个identity运算符,而后向传播是一个all-reduce,g 的前向传播是 all-reduce,后向传播是一个identity运算符。这里的 f 来自 ColumnParallelLinear,g 来自 RowParallelLinear。即,MLP 就是把 ColumnParallelLinear 和 RowParallelLinear 结合起来。
另一个选项是沿列拆分A,得到 A=[A1,A2]A=[A1,A2]
这个方法更好,因为它删除了同步点,直接把两个 GeLU 的输出拼接在一起就行。因此,我们以这种列并行方式划分第一个GEMM,并沿其行分割第二个GEMM,以便它直接获取GeLU层的输出,而不需要任何其他通信(比如 all-reduce 就不需要了),如图所示。
我们再深入分析一下为何选择这个方案。
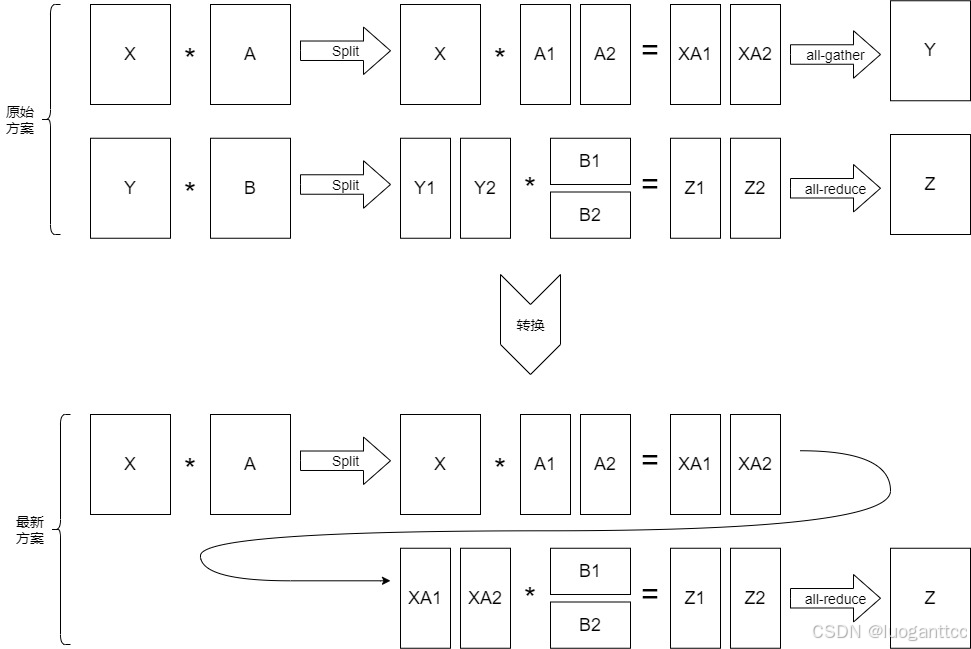
按照常规逻辑,MLP 的前向传播应该分为两个阶段,分别对应了下面图之中的两行,
- 第一行是把参数 A 按照列切分,然后把结果按照列拼接起来,得到的结果就是与不使用并行策略完全等价的结果。
- 第二行是把激活 Y 按照列切分,参数B按照行切分做并行,最后把输出做加法,得到 Z。
但是每个split会导致两次额外的通信(前向传播和后向传播各一次,下面只给出了前向传播)。因为对于第二行来说,其输入Y其实本质是 XA1,XA2并行的,所以为了降低通信量,我们可以把数据通信延后或者干脆取消通信,就是把第一行最后的 all_gather 和第二行最初的 split 省略掉,这其实就是数学上的传递性和结合律(局部和之和为全局和)。于是我们就得到了论文之中的第二种方案。