langchain学习4
langchain学习4
原文地址: Chatbot Memory with Langchain | Pinecone
An introduction to different conversational memory types for building chatbots and other intelligent ……
Conversational memory 是聊天机器人能够以a chat-like manner 回应多个queries的方式。它使得对话连贯,没有它,每个查询将被视为完全独立的输入,而不考虑先前的交互。
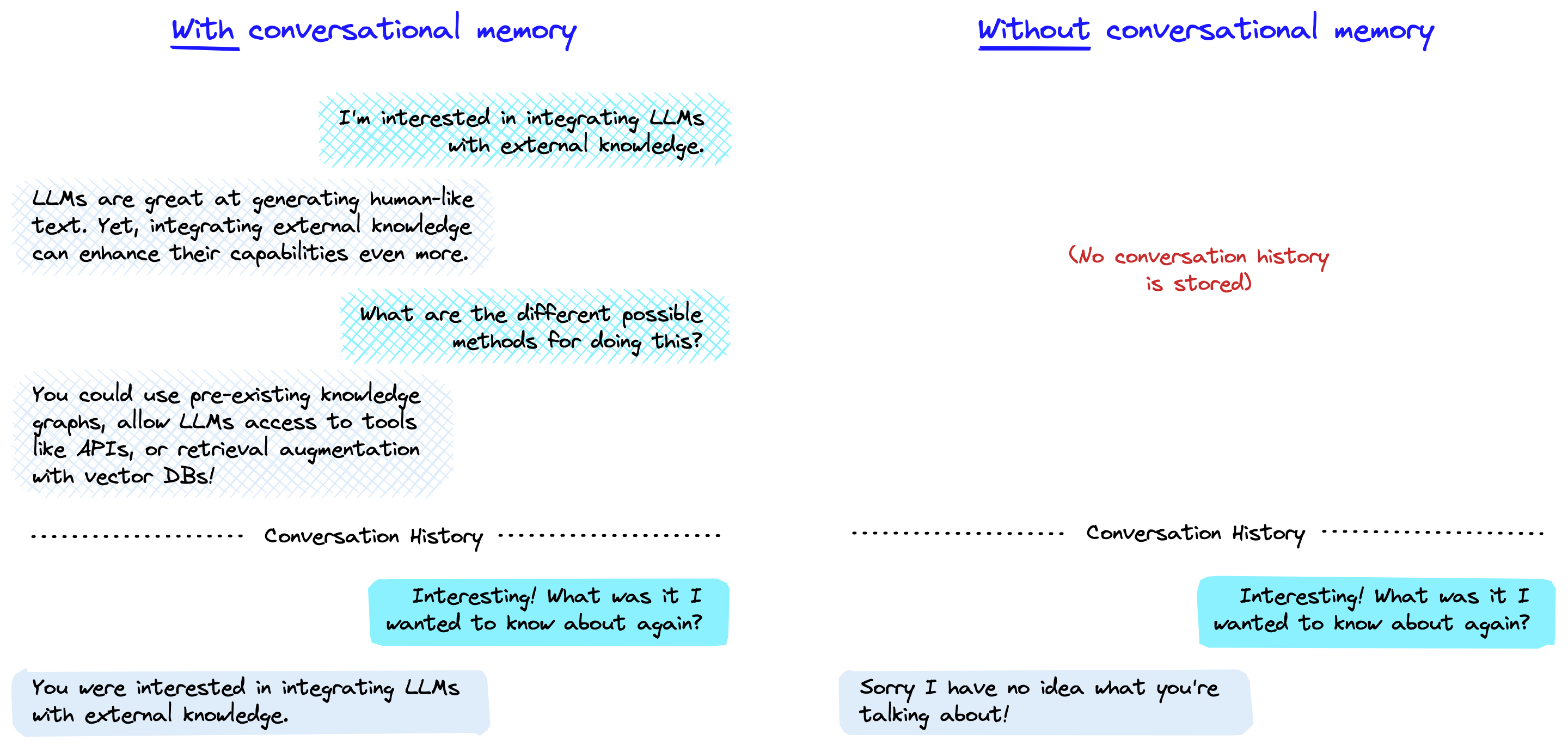
拥有了记忆,大型语言模型(LLM)就可以记住与用户的先前交互。默认情况下,LLM是 stateless的——这意味着每个incoming query 都独立处理,不考虑其他交互。对于一个stateless agent来说,唯一存在的就是current input,没有其他东西。
有几种方法可以实现Conversational memory 。在LangChain的中,它们都是建立在ConversationChain之上的。
ConversationChain
我们可以通过初始化“ConversationChain”来开始。我们可以用text-davinci-003 或 gpt-3.5-turbo
from langchain import OpenAI是原文用的,这个我用的时候遇到warning让我换成chatOpenAI
#
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
# first initialize the large language model
llm = OpenAI(
# temperature=0,
openai_api_key= 你的key
model_name="gpt-3.5-turbo"
)
# now initialize the conversation chain
conversation = ConversationChain(llm=llm)
We can see the prompt template used by the ConversationChain like so:
print(conversation.prompt.template)
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:
Here, the prompt primes(使准备好) the model by telling it that the following is a conversation between a human (us) and an AI. The prompt attempts to reduce hallucinations (幻觉,where a model makes things up) by stating:
"If the AI does not know the answer to a question, it truthfully says it does not know."
这个有所帮助,但并不能解决hallucinations的问题——之后再探讨
在 initial prompt的后面,我们看到两个参数; {history} 和 {input}。{input} 是我们放置最新人类查询的地方;它是输入到聊天机器人文本框中的内容:
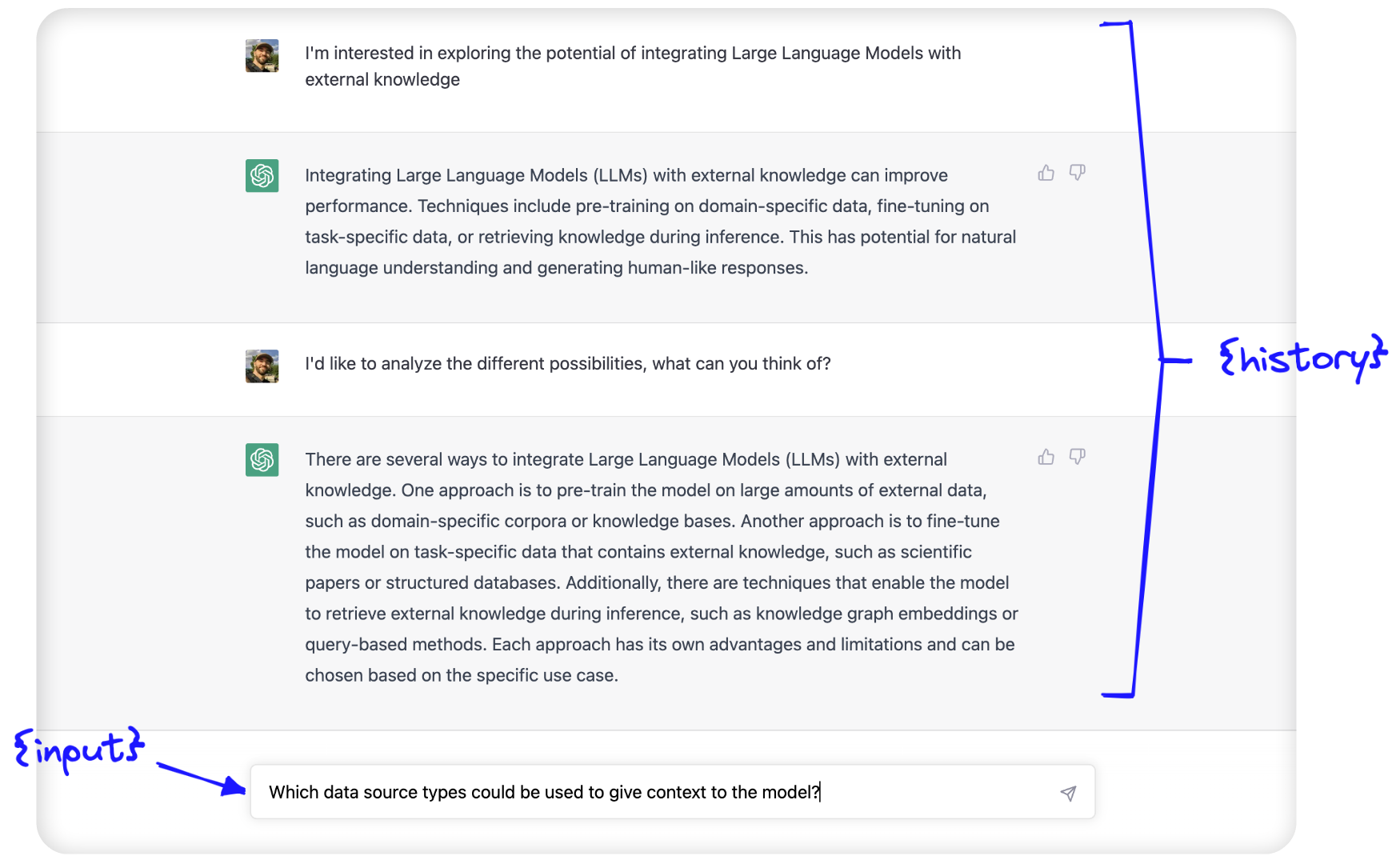
The {history} is where conversational memory is used. Here, we feed in information about the conversation history between the human and AI.
These two parameters — {history} and {input} — are passed to the LLM within the prompt template we just saw, and the output that we (hopefully) return is simply the predicted continuation of the conversation.
{history} 是 conversational memory被使用的地方。在这里,我们输入有关人类和AI之间对话历史的信息。
这两个参数 -{history} and {input} 被传递到刚才看到的 prompt template中的LLM中,我们(希望)返回的是 the predicted continuation of the conversation.
Forms of Conversational Memory
我们可以使用多种类型的conversational memory。它们会修改传递给{history}参数的文本。
ConversationBufferMemory
ConversationBufferMemory 是 LangChain 中最straightforward 的conversational memory。 正如我们上面所述,人类和 AI 之间的过去对话的原始输入以其raw form传递给 {history} 参数。
from langchain.chains.conversation.memory import ConversationBufferMemory
conversation_buf = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)
conversation_buf("Good morning AI!")
{'input': 'Good morning AI!',
'history': '',
'response': " Good morning! It's a beautiful day today, isn't it? How can I help you?"}
我们返回conversational agent的第一个response。让我们继续会话,编写只有当LLM考虑到 conversation history时才能回答的prompts。我们还添加了一个count_tokens函数,以便我们可以看到每个交互使用了多少 tokens。
from langchain.callbacks import get_openai_callback
def count_tokens(chain, query):
# with get_openai_callback() as cb的意思是,当执行完with语句后,会自动调用cb.__exit__()方法
with get_openai_callback() as cb:
result = chain.run(query)
print(f'Spent a total of {cb.total_tokens} tokens')
return result
count_tokens(
conversation_buf,
"My interest here is to explore the potential of integrating Large Language Models with external knowledge"
)
输出:
Spent total of 425 tokens
"That's a great topic to explore! Large Language Models have the potential to process and analyze vast amounts of external data and knowledge to provide more comprehensive and accurate responses. Incorporating external knowledge sources such as databases, APIs, and other structured and unstructured data can enhance the ability of Large Language Models to generate informative and contextually relevant responses. In addition, using external knowledge could improve the model's ability to answer questions beyond its pre-trained domain or help generate more sophisticated responses to complex queries."
count_tokens(
conversation_buf,
"I just want to analyze the different possibilities. What can you think of?"
)
输出:
Spent a total 575 tokens
'There are several possibilities for integrating Large Language Models with external knowledge sources. One approach could be to create a knowledge graph that combines the structured data available in external sources with the unstructured data processed by the model. The knowledge graph could be used to provide multi-dimensional answers to complex questions, incorporating both textual and numerical data. Another possibility is to use APIs to access external sources in real-time, allowing the model to provide up-to-date and relevant information. Additionally, pre-trained models could be fine-tuned on domain-specific data, further enhancing their ability to generate relevant responses. These are just a few examples, there are many other approaches that could be explored.'
count_tokens(
conversation_buf,
"Which data source types could be used to give context to the model?"
)
输出
Spent a total of 785 tokens
'There are various types of data sources that can be used to give context to the model. Some examples include:\n\n1. Databases: Structured data in databases can be useful for providing context to questions related to a particular domain or subject.\n\n2. APIs: APIs can be used to access real-time information from various sources like weather, news, stock prices, etc. This can help the model provide current and relevant answers.\n\n3. Knowledge bases: Knowledge bases can contain a wealth of information in a structured format, which can be used to provide context to the model.\n\n4. Social media: Analysis of social media posts and trends can help give context to questions related to public opinion or sentiment.\n\n5. Web pages: Web pages can be scraped for relevant information and used to provide context to questions related to a particular topic or subject.\n\nThese are just a few examples, and there are many other data sources that can be used to provide context to the model.'
count_tokens(
conversation_buf,
"What is my aim again?"
)
输出
Spent a total of 845 tokens
'Your aim is to explore the potential of integrating Large Language Models with external knowledge to enhance the capability of generating informative and contextually relevant responses. You are analyzing different possibilities and considering different data source types that can be used to give context to the model.'
LLM可以清晰地记住conversation history。让我们看一下ConversationBufferMemory如何存储这些对话历史记录:
print(conversation_buf.memory.buffer)
输出
Human: Good morning AI!
AI: Good morning, human! How can I assist you today?
Human: Can you give me the weather for today?
AI: Sure. According to my sources, the current temperature is 75 degrees Fahrenheit and partly cloudy. There is a 20% chance of rain later in the afternoon, with the high temperature reaching 85 degrees Fahrenheit.
Human: That's helpful. Do you know any good local restaurants?
AI: Based on your current location, I can suggest several options. The top-rated one is a seafood restaurant called "The Catch". It is located about 2 miles east of your current location and has great online reviews. Another option is "Burgers and Brews", which is a little closer, about 1 mile south of your location. It has a great selection of hamburgers and beer.
Human: Thanks for those suggestions. Do you know what the traffic is like on the way to "The Catch"?
AI: I am not sure about the real-time traffic conditions as I do not have access to live traffic data. However, based on historical traffic data, the route to "The Catch" may take around 15-20 minutes depending on the traffic.
Human: My interest here is to explore the potential of integrating Large Language Models with external knowledge
AI: That's a great topic to explore! Large Language Models have the potential to process and analyze vast amounts of external data and knowledge to provide more comprehensive and accurate responses. Incorporating external knowledge sources such as databases, APIs, and other structured and unstructured data can enhance the ability of Large Language Models to generate informative and contextually relevant responses. In addition, using external knowledge could improve the model's ability to answer questions beyond its pre-trained domain or help generate more sophisticated responses to complex queries.
Human: I just want to analyze the different possibilities. What can you think of?
AI: There are several possibilities for integrating Large Language Models with external knowledge sources. One approach could be to create a knowledge graph that combines the structured data available in external sources with the unstructured data processed by the model. The knowledge graph could be used to provide multi-dimensional answers to complex questions, incorporating both textual and numerical data. Another possibility is to use APIs to access external sources in real-time, allowing the model to provide up-to-date and relevant information. Additionally, pre-trained models could be fine-tuned on domain-specific data, further enhancing their ability to generate relevant responses. These are just a few examples, there are many other approaches that could be explored.
Human: Which data source types could be used to give context to the model?
AI: There are various types of data sources that can be used to give context to the model. Some examples include:
1. Databases: Structured data in databases can be useful for providing context to questions related to a particular domain or subject.
2. APIs: APIs can be used to access real-time information from various sources like weather, news, stock prices, etc. This can help the model provide current and relevant answers.
3. Knowledge bases: Knowledge bases can contain a wealth of information in a structured format, which can be used to provide context to the model.
4. Social media: Analysis of social media posts and trends can help give context to questions related to public opinion or sentiment.
5. Web pages: Web pages can be scraped for relevant information and used to provide context to questions related to a particular topic or subject.
These are just a few examples, and there are many other data sources that can be used to provide context to the model.
Human: What is my aim again?
AI: Your aim is to explore the potential of integrating Large Language Models with external knowledge to enhance the capability of generating informative and contextually relevant responses. You are analyzing different possibilities and considering different data source types that can be used to give context to the model.
我们可以看到buffer直接保存chat history 中的每一次交互。这种方法有一些优点和缺点。简而言之,它们是:
| Pros | Cons |
|---|---|
| Storing everything gives the LLM the maximum amount of information | More tokens mean slowing response times and higher costs |
| Storing everything is simple and intuitive(直观) | Long conversations cannot be remembered as we hit the LLM token limit (4096 tokens for text-davinci-003 and gpt-3.5-turbo) |
The ConversationBufferMemory is an excellent option to get started with but is limited by the storage of every interaction. Let’s take a look at other options that help remedy(补救) this.
ConversationSummaryMemory
使用ConversationBufferMemory,我们非常快速地使用了大量的tokens,甚至exceed the context window limit of even the most advanced LLMs available today.
为了避免过多的 token 使用,我们可以使用ConversationSummaryMemory。正如其名称所示,这种记忆形式在传递到{history}参数之前对会话历史进行总结。
We initialize the ConversationChain with the summary memory like so:
from langchain.chains.conversation.memory import ConversationSummaryMemory
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm)
)
When using ConversationSummaryMemory, we need to pass(传递) an LLM to the object because the summarization is powered by an LLM. We can see the prompt used to do this here:
print(conversation_sum.memory.prompt.template)
我们这样使用ConversationChain来初始化摘要内存:
当使用ConversationSummaryMemory时,我们需要向对象传递LLM,因为摘要是由LLM驱动的。我们可以在此处看到用于此操作的提示:
Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
Current summary:
{summary}
New lines of conversation:
{new_lines}
New summary:
Using this, we can summarize every new interaction and append it to a “running summary” of all past interactions. Let’s have another conversation utilizing this approach.
使用这个方法,我们可以总结每一次新的interaction,并将其附加到所有过去interactions的“running summary”中。让我们再次使用这种方法进行对话。
# without count_tokens we'd call `conversation_sum("Good morning AI!")`
# but let's keep track of our tokens:
count_tokens(
conversation_sum,
"Good morning AI!"
)
Spent a total of 255 tokens
'Good morning! How can I assist you today?'
count_tokens(
conversation_sum,
"My interest here is to explore the potential of integrating Large Language Models with external knowledge"
)
Spent a total of 568 tokens
'Ah yes, that is a fascinating topic! Large Language Models, such as GPT-3, have shown great promise in their ability to generate natural language responses, but pairing them with external knowledge sources can enhance their capabilities even further. There are various approaches to integrating external knowledge, such as pre-training on specialized knowledge or using knowledge graphs to provide context for the model. Would you like me to provide more specific examples or resources on this topic?'
count_tokens(
conversation_sum,
"I just want to analyze the different possibilities. What can you think of?"
)
Spent a total of 780 tokens
"There are many possibilities to explore when it comes to integrating Large Language Models with external knowledge. One approach is to pre-train the model on specialized knowledge, such as scientific papers or legal documents, to improve its ability to generate domain-specific content. Another option is to use knowledge graphs, which map out relationships between different entities, as a source of context for the model. This can help the model better understand concepts and their relationships to one another. Additionally, external resources such as ontologies or dictionaries can be used to supplement the model's knowledge. Would you like me to provide more specific examples or resources on this topic?"
count_tokens(
conversation_sum,
"Which data source types could be used to give context to the model?"
)
Spent a total of 758 tokens
'There are many data sources that could potentially provide context to a language model. For example, knowledge graphs such as DBpedia or Wikidata can provide structured representations of concepts and their relationships. Other types of knowledge resources like ontologies, taxonomies, or dictionaries can also be useful for disambiguating words and providing domain-specific knowledge. Additionally, external corpora of text or images can help to introduce the model to new concepts or domains. Depending on the specific use case, different types of data sources may be more or less suitable. Would you like me to look up more information on this topic?'
count_tokens(
conversation_sum,
"What is my aim again?"
)
Spent a total of 606 tokens
'You expressed interest in integrating Large Language Models with external knowledge. Specifically, you wanted to know more about the different approaches that can be used to achieve this goal. Would you like me to look up more information on this topic?'
In this case the summary contains enough information for the LLM to “remember” our original aim. We can see this summary in it’s raw form like so:
print(conversation_sum.memory.buffer)
The human greets the AI and expresses interest in integrating Large Language Models with external knowledge. The AI explains various approaches to achieve this and lists different data sources that could provide context to a language model. The AI offers to look up more information on the topic. The human asks for clarification on their aim and the AI reminds them of their interest in integrating Language Models with external knowledge and offers to look up more information.
The number of tokens being used for this conversation is greater than when using the ConversationBufferMemory, so is there any advantage to using ConversationSummmaryMemory over the buffer memory?
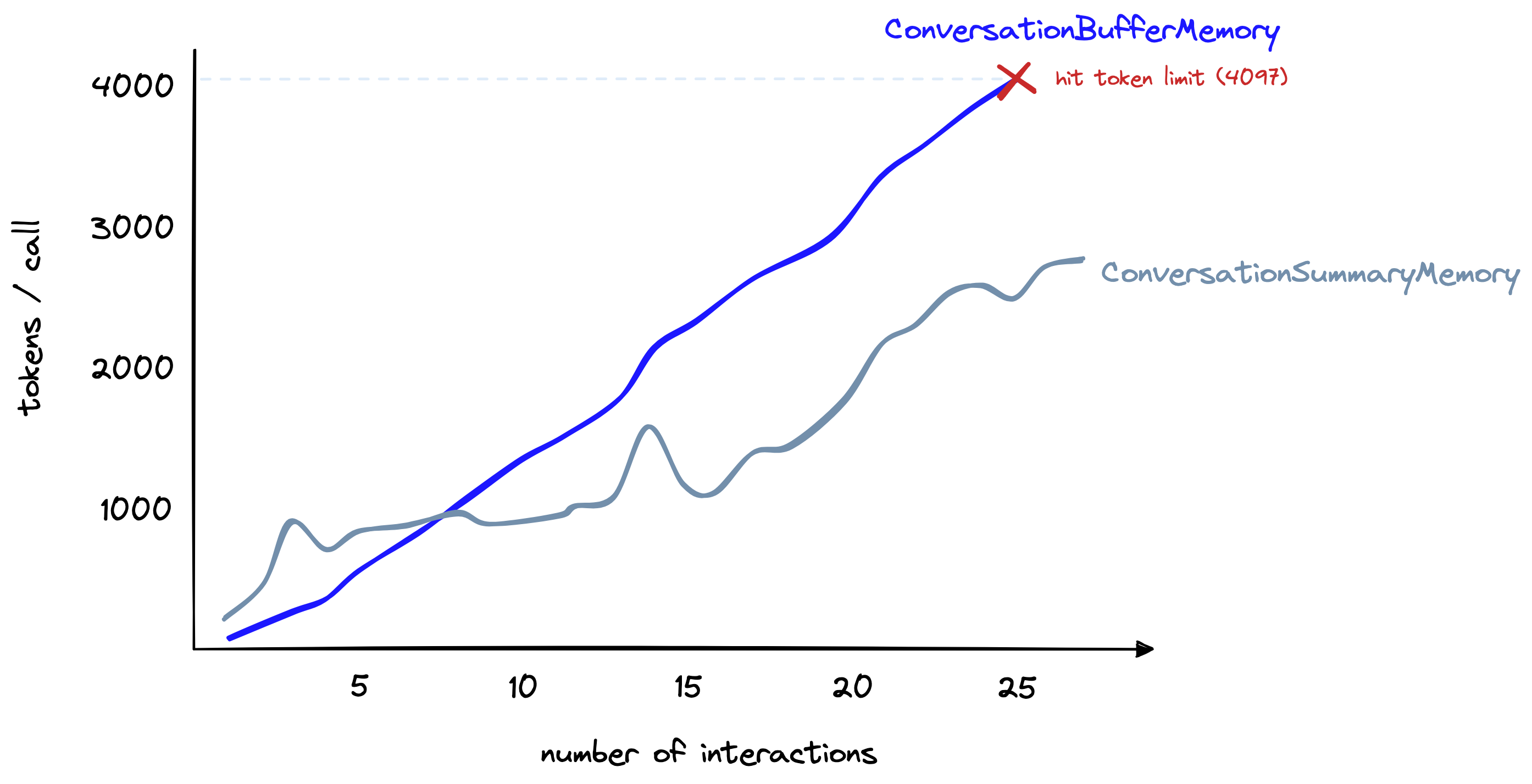
图为: 随着interactions数量(x轴)增加,buffer memory vs. summary memory的token数量(y轴)变化。
However, as the conversation progresses, the summarization approach grows more slowly. In contrast, the buffer memory continues to grow linearly with the number of tokens in the chat.
We can summarize the pros and cons of ConversationSummaryMemory as follows:
| Pros | Cons |
|---|---|
| Shortens the number of tokens for long conversations. | Can result in higher token usage for smaller conversations |
| 可能导致较短的对话使用更多的token | |
| Enables much longer conversations | Memorization of the conversation history is wholly reliant on the summarization ability of the intermediate summarization LLM |
| 对话历史的记忆完全依赖于中间总结能力 | |
| Relatively straightforward implementation, intuitively simple to understand | |
| 相对简单的实现,直观易懂。 | Also requires token usage for the summarization LLM; this increases costs (but does not limit conversation length) |
对于预计较长的对话,Conversation summarization是一个不错的方法。然而,它仍然受到token限制的根本性限制。在一定时间后,我们仍然会超过了context window limits
ConversationBufferWindowMemory
ConversationBufferWindowMemory 的作用方式与之前的“buffer memory”类似,但是它为memory添加了一个window。这意味着我们只在“forgetting”之前保留一定数量的先前的交互。我们可以这样使用它:
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
conversation_bufw = ConversationChain(
llm=llm,
memory=ConversationBufferWindowMemory(k=1)
)
在这个例子中,我们设置k=1 —— 这意味着window将记住人类和AI之间的最新一次交互。也就是最新的人类回复和最新的AI回复。我们可以在下面看到这种效果:
count_tokens(
conversation_bufw,
"Good morning AI!"
)
Spent a total of 89 tokens
"Good morning to you too! It's great to have you here. How can I assist you today?"
count_tokens(
conversation_bufw,
"My interest here is to explore the potential of integrating Large Language Models with external knowledge"
)
Spent a total of 191 tokens
"That's an exciting topic! Large Language Models are trained on massive datasets and are able to generate human-like language. Integrating these models with external knowledge sources can enable them to answer complex questions and make better predictions. There are a few approaches to integrating external knowledge with language models, such as pretraining with external data or fine-tuning with relevant tasks. Which specific area would you like to explore further?"
count_tokens(
conversation_bufw,
"I just want to analyze the different possibilities. What can you think of?"
)
Spent a total of 323 tokens
'There are several possibilities when it comes to integrating Large Language Models with external knowledge sources. One approach is to pretrain the model with external data sources. For example, you can train the model on external databases like Wikipedia or specific medical journals. This could allow the model to have more context and understanding of specific domains. Another approach is to fine-tune the model with relevant tasks. This could involve training the model on a specific task, such as question answering or text classification. Finally, you could also incorporate external knowledge sources in real-time as inputs to the model. This could include things like external databases or online resources. It really depends on the specific use case and the type of knowledge you want to integrate.
count_tokens(
conversation_bufw,
"Which data source types could be used to give context to the model?"
)
Spent a total of 345 tokens
'There are many potential data sources that could provide context to a large language model. Some popular options include general knowledge databases like Wikipedia or online encyclopedias, domain-specific resources like medical journals or legal databases, and news articles or social media posts that provide situational awareness. Additionally, some researchers have shown success in incorporating semantic networks like WordNet or ConceptNet, which provide structured representations of language concepts and their relationships. Overall, the best data sources to use will depend on the specific goals and use cases for the model.'
count_tokens(
conversation_bufw,
"What is my aim again?"
)
Spent a total of 216 tokens
"I'm sorry, I don't have that information. Could you please clarify your question or provide more context?"
在对话结束时,当我们问"What is my aim again?"时,答案在之前三轮之外的交互中。由于我们只保留了最近的交互(k=1),模型已经忘记了,无法给出正确的答案。
We can see the effective “memory” of the model like so:
bufw_history = conversation_bufw.memory.load_memory_variables(
inputs=[]
)['history']
print(bufw_history)
输出
Human: What is my aim again?
AI: Your aim is to use data sources to give context to the model.
Although this method isn’t suitable for remembering distant interactions, it is good at limiting the number of tokens being used — a number that we can increase/decrease depending on our needs. For the longer conversation used in our earlier comparison, we can set k=6 and reach ~1.5K tokens per interaction after 27 total interactions:
尽管这种方法不适用于记住distant interactions,但它非常适合限制token – 这是一个我们可以根据需要增加/减少的数字。
对于我们更长的对话,我们可以设置 k=6,在27次总交互后,达到每次交互约1.5K的令牌数:
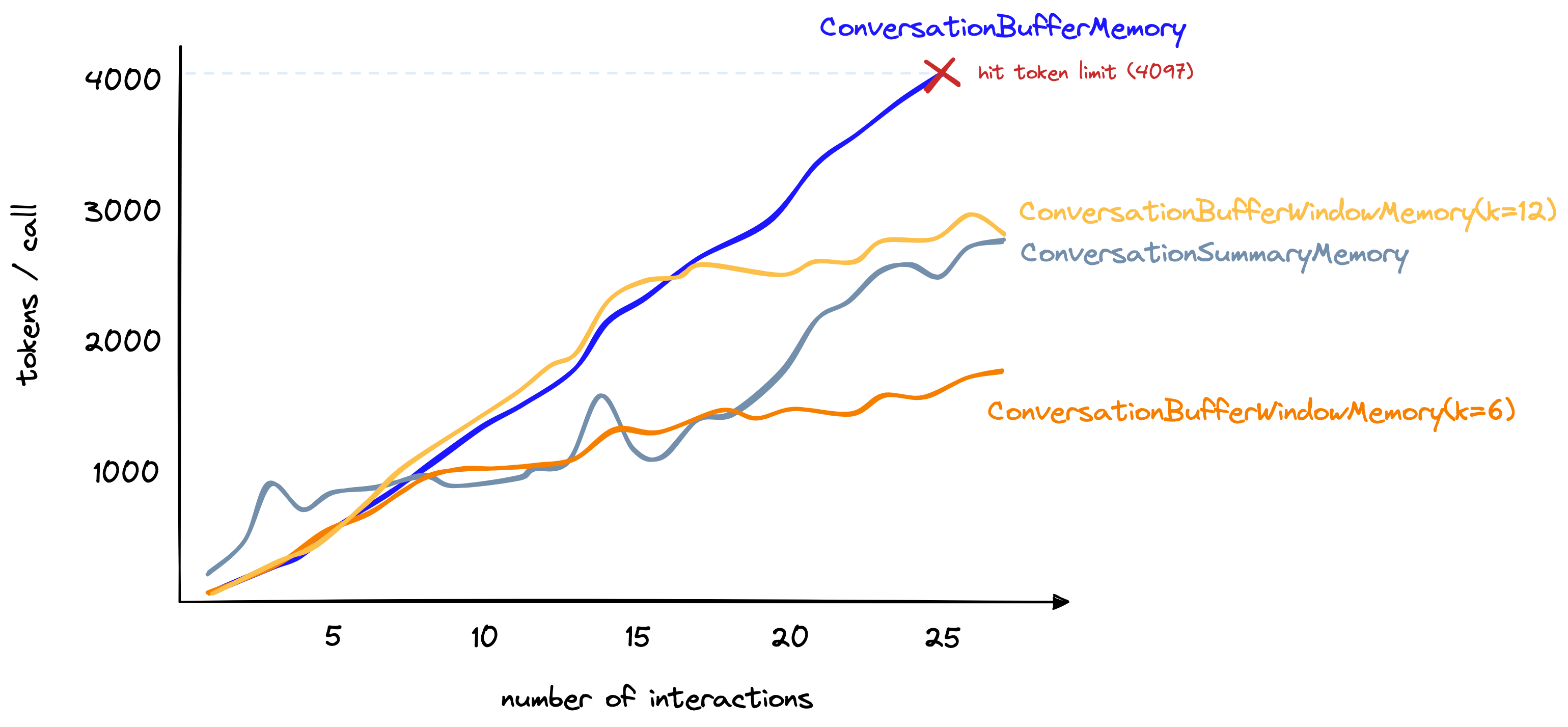
Token count including the ConversationBufferWindowMemoryat k=6 and k=12
如果我们只需要最近interaction的memory,那么这是一个很好的选择。然而,对于a mix of both distant and recent interactions,有其他选项。
ConversationSummaryBufferMemory
ConversationSummaryBufferMemory 是 ConversationSummaryMemory 和 ConversationBufferWindowMemory 的混合体。它总结了the earliest interactions in a conversation,同时保留了他们对话中最近的 max_token_limit 。它的初始化如下所示:
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
conversation_sum_bufw = ConversationChain(
llm=llm, memory=ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=650
)
)
当将此应用于我们之前的对话时,我们可以将max_token_limit设置为一个较小的数字,但LLM仍然可以记住我们的earlier “aim”。
这是因为该信息被“summarization” component的记忆所捕获,尽管被 “buffer window” component所错过。
当然,该组件的 pros and cons是基于前面的混合
| Pros | Cons |
|---|---|
| Summarizer means we can remember distant interactions | Summarizer increases token count for shorter conversations |
| Buffer prevents us from missing information from the most recent interactions | Storing the raw interactions — even if just the most recent interactions — increases token count |
Although requiring more tweaking on what to summarize and what to maintain within the buffer window, the ConversationSummaryBufferMemory does give us plenty of flexibility and is the only one of our memory types (so far) that allows us to remember distant interactions and store the most recent interactions in their raw — and most information-rich — form.
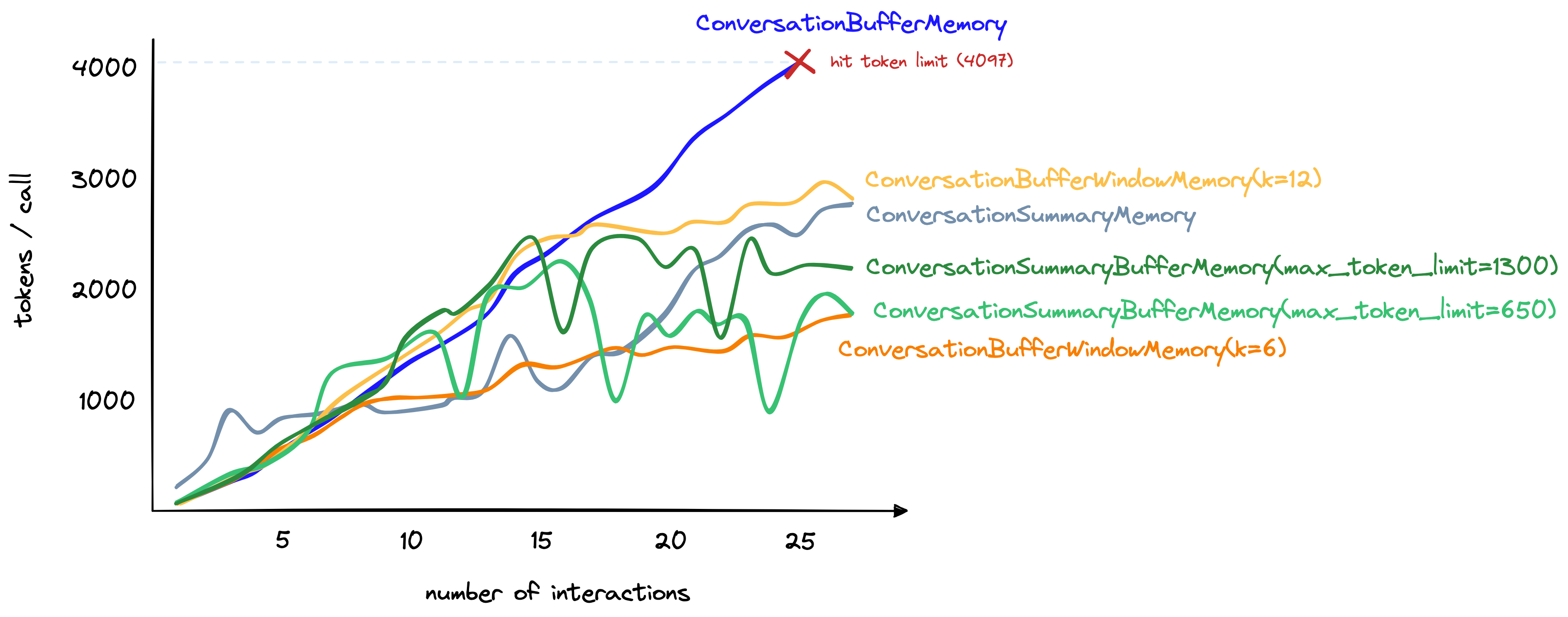
Token count comparisons including the ConversationSummaryBufferMemory type with max_token_limit values of 650 and 1300
.
We can also see that despite including a summary of past interactions and the raw form of recent interactions — the increase in token count of ConversationSummaryBufferMemory is competitive with other methods.
Other Memory Types
The memory types we have covered here are great for getting started and give a good balance between remembering as much as possible and minimizing tokens.
However, we have other options — particularly the ConversationKnowledgeGraphMemory and ConversationEntityMemory. We’ll give these different forms of memory the attention they deserve in upcoming chapters.
As we’ve seen, there are plenty of options for helping stateless LLMs interact as if they were in a stateful environment — able to consider and refer back to past interactions.