android知识巩固(二.非线性数据结构)
非线性结构:是从逻辑结构上划分,其元素存在一对多或者多对多的相互关系
1.前言
在前一章中,我们了解了数据结构的基本思想,学习了部分基本的线性数据结构,了解了计算机是如何表示和存储数据的,良好的数据结构思想有助于我们写出性能优良的应用
2.目录

3.非线性数据结构
3.1.树
3.1.1.描述
树(Tree):有n个节点的有限集,n=0,则为空树
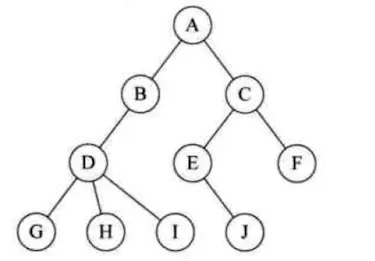
3.1.2.特性
- 有且仅有一个特定的根节点
- 其余节点可分为多个互不相交的有限集,每个子集合本身又是一棵树
3.1.3.概念
树的度:树的节点拥有的子树数

树的层次和深度:根为第一层,根的孩子为第二层,树中节点的最大层次称为树的深度

3.1.4.常用的树
3.1.4.1.二叉树
二叉树:是n个节点的有限集合,由一个根节点和两棵互不相交的,分别称为根节点的左子树和右子树的二叉树组成
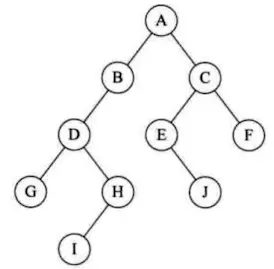
3.1.4.2.满二叉树
满二叉树:除最后一层无任何子节点外,每一层上的所有节点都有两个子节点的二叉树。高度为h,由2^h-1个节点构成的二叉树称为满二叉树。

3.1.4.3.完全二叉树
完全二叉树:由满二叉树而引出来的,若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的节点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的节点都连续集中在最左边,这就是完全二叉树。

3.1.4.4.哈弗曼树
哈弗曼树:带权路径最小的二叉树称作赫夫曼树( 节点的带权路径:从该节点到树根之间的路径长度与节点上权的乘积),主要解决的就是访问深度的问题,不合理的结构会导致非必须块多次访问的效率问题

微信终极压缩就使用到了赫夫曼编码(转化为更简单的二进制表示方法,压缩了数据,使传输更加高效)


3.1.4.4.二叉查找树
二叉查找树(BST,又二叉搜索树,二叉排序树)是一棵空树,或者是具有下列性质的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根节点的值
- 若它的右子树不空,则右子树上所有结点的值均大于它的根节点的值
- 它的左、右子树也分别为二叉排序树

3.1.4.5.平衡二叉树
平衡二叉树(ALV树):一种二叉排序树,其中每个节点的左子树和右子树的高度至多差一
- 解决问题:防止层次过深,出现访问效率问题,可通过左旋,右旋构建AVL树
- 平衡因子(Balance Factor):二叉树上节点的左子树深度减去右子树深度的值

3.1.4.6.红黑树
红黑树(Red Black Tree)是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,具有如下特性:
- 结点是红色或者黑色
- 根节点是黑色
- 每个叶子的节点都是黑色的空节点(NULL)
- 每个红色节点的两个子节点都是黑色的。
- 从任意节点到其每个叶子的所有路径都包含相同数目的黑色节点。
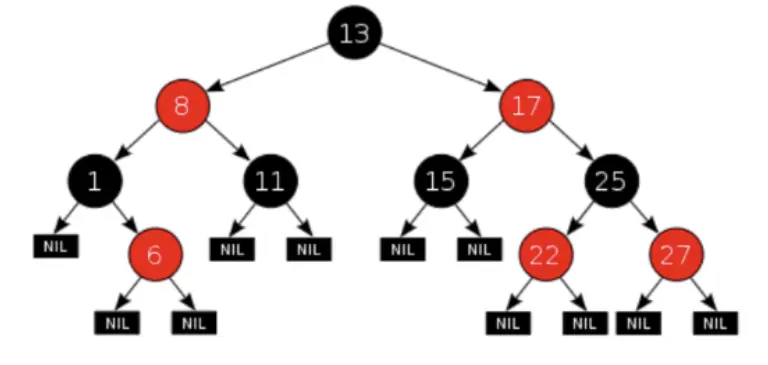
红黑树知识点:
- 对平衡树的改进,任意一个节点,他的左右子树的层次最多不超过一倍
- 红黑树是牺牲了严格的高度平衡的优越条件为代价,它只要求部分地达到平衡要求,降低了对旋转的要求,提高了性能,是一个折中的方案
- 相比于BST,因为红黑树可以能确保树的最长路径不大于两倍的最短路径的长度,所以可以看出它的查找效果是有最低保证的。在最坏的情况下也可以保证O(logN)的,这是要好于二叉查找树的。因为二叉查找树最坏情况可以让查找达到O(N)。
- 红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高,所以在插入和删除中所做的后期维护操作肯定会比红黑树要耗时多,但是他们的查找效率都是O(logN),所以红黑树应用还是高于AVL树的. 实际上插入 AVL 树和红黑树的速度取决于你所插入的数据.如果你的数据分布较好,则比较宜于采用 AVL树(例如随机产生系列数),但是如果你想处理比较杂乱的情况,则红黑树是比较快的
3.1.5.二叉树的遍历

- 前序遍历:根→左→右(5→2→1→3→4→7→6)
- 中序遍历:左→根→右(1→2→3→4→5→6→7)
- 后序遍历:左→右→根(1→4→3→2→6→7→5)
3.1.6.二叉树的查找
- 深度优先搜索:从根节点出发,沿着左子树方向进行纵向遍历,直到找到叶子节点为止.然后回溯到前一个子节点,进行右子树节点的遍历,直到遍历完所有的节点为止(5→2→1→3→4→7→6)
- 广度优先搜索:从根节点出发,在横向遍历的二叉树层段节点的基础上纵向遍历二叉树的层次(5→2→7→1→3→6→4)
3.2.图
3.2.1.描述
图(Graph):由顶点的有穷非空集合和顶点之间边的集合组成
3.2.2.特性
- 线性表中的数据叫元素,树中的元素叫节点,图中的元素称之为顶点
- 线性表中没有元素,称之为空表,树中没有节点称之为空树,图中必须有元素
- 主要应用于建模,算法较复杂
3.2.3.概念
- 根据相连两顶点的边是否头方向分为有向图和无向图
- 图的权:图的边或弧上的相关数值
- 图的度:无向图顶点的边数叫度,有向图顶点的边数叫出度和入度
- 图的邻接矩阵存储方式是用两个数组来表示图.一个一维数组存储图中的顶点信息(顶点不分主次和大小),一个二维数组(称为邻接矩阵)存储图中的边或弧的信息.

- 在邻接表中,图的每一个顶点都是一个链表的头节点,其后连接着该顶点能够直接达到的相邻顶点。(优点:占用空间小)
- 顺序查找使用邻接表,像这种逆向查找的麻烦,该如何解决呢?我们可以是用逆邻接表来解决。
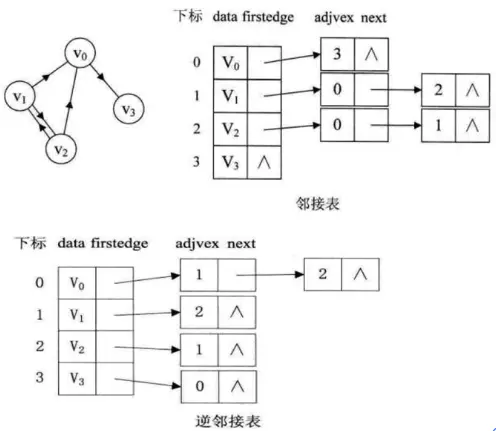
3.3.堆
3.3.1.描述
堆(Heap):是一种特殊的树形数据结构,一般讨论的堆都是二叉堆,是一棵完全二叉树
3.3.2.特性
- 根节点的值是所有节点中最小的或者最大的,分为最大堆和最小堆
- 根节点的两个子树也是一个堆结构
- 堆就是用数组实现的二叉树,所以它没有使用父指针或者子指针,其通过索引及相关函数表示各节点位置
- 插入快,删除快,对大数据项操作效率高
3.3.3.概念
- 对属性:在最大堆中,父节点的值比每一个子节点的值都要大。在最小堆中,父节点的值比每一个子节点的值都要小

3.4.散列表
3.4.1.描述
散列表:也叫哈希表,是根据关键码值(key value)映射到表中的一个位置来访问,以加快查找速度,也叫做散列函数
3.4.2.特性
- 优点:寻址容易 插入删除也容易
- 缺点:由于是基于数组存储数据,扩容需要大量的空间和性能,哈希表被填满时,性能下降严重
3.4.3.概念
- 散列方法:关键码值转化为数组下标
1.余数法
2.折叠法
3.基数转换法
hashMap中的hash方法,将高位和低位混合起来(扰动算法),降低冲突概率
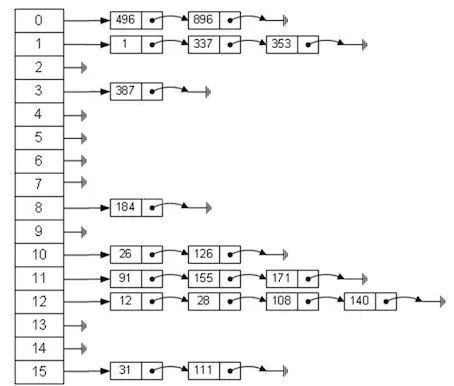
- 散列冲突处理(转化时数组下标冲突)
1.开放定址法(线性探测法,冲突了取下一个值)
2.链地址法
4.总结
这两章我们学习了一些基本的数据结构的相关概念和基本的使用,在心中有了个大概的轮廓.当然,目前讲解的比较简单,并没有通过代码实现相关的数据结构,有些数据结构也没有讲解到,后面我们会针对在开发过程中遇到的问题,进行详细的讲解.下一章我们将学习的是常用的算法知识

喜欢的朋友记得点赞、收藏、关注哦!!!