高阶数据结构----布隆过滤器和位图
(一)位图
位图是用来存放某种状态的,因为一个bit上只能存0和1所以一般只有两种状态的情况下适合用位图,所以非常适合判断数据在或者不在,而且位图十分节省空间,很适合于海量数据,且容易存储,数据无重复的场景(因为位图是天然去重的)
那我们来看一下他是如何节省空间的

我们看这个例子,如果我们不使用位图,一共10个整型数据,需要消耗40个字节,但是如果使用位图,我们就只需要3个字节就可以判断这个数字是否存在
注:10亿字节1个g
(二)位图的实现及作用
public class bitmap {
public byte[] elem;
public int usedSize;
public bitmap() {
elem=new byte[1];
}
//初始化位图长度
public bitmap(int n) {
elem=new byte[(n/8)+1];
}
public void setElem(int val){
//找到插入第几个byte中 val/8
if (val<0)throw new IndexOutOfBoundsException();
int arrIndex=val/8;
//找到插入到byte的第几个bit中 val%8
int bitIndex=val%8;
elem[arrIndex] |= (1<<bitIndex); //这里用| 之前为1的就一直为1,当前我要插入的一定会修改为1
usedSize++; //这里其实不一定正确,因为如果本身就存在这个元素,那么我们不应该++
}
public boolean get(int val){
//找到插入第几个byte中 val/8
if (val<0)throw new IndexOutOfBoundsException();
int arrIndex=val/8;
//找到插入到byte的第几个bit中 val%8
int bitIndex=val%8;
if((elem[arrIndex] & 1<<bitIndex)!=0){ //这里是用& 把其余所有位都变成0,如果当前我要找的存在就不为0
return true;
}
return false;
}
public void delete(int val){
//找到删除第几个byte中 val/8
if (val<0)throw new IndexOutOfBoundsException();
int arrIndex=val/8;
//找到删除到byte的第几个bit中 val%8
int bitIndex=val%8;
elem[arrIndex] &=~(1<<bitIndex);
usedSize--;
}
}我们之后来看一下我们的set delete和get方法中的不同点
我们发现只有对bit位的处理是不同的,找位置的代码都是一样的,所以我们就来看对bit位的处理
首先是set方法,我们是用了 | 只要有1就为1 这样是为了确保在我们添加元素的时候不影响其他bit位上的元素,如果我们变成& 就会这样
 我们发现下标为5的元素被修改为0了,这显然是不对的,如果是异或那就更不对了
我们发现下标为5的元素被修改为0了,这显然是不对的,如果是异或那就更不对了

然后我们来看get 我们用了 & 只有都为1的时候才为1,其他都是0,也就是说我们想找这个元素,且他存在的时候才为1,其他都为0,如果使用 | 我们就无法判断了
最后一个我们看delete 我们先取反然后再& ,这样能够保证只有这一位是0,其他位全为1,如果其他位本身不存在那么1&0还是0,如果存在1&1为1还是存在,而我们要删除的位,无论如何都为0,这里可能要问,为什么不能使用异或,异或有一个情况会发生错误,如果我们删除的位置本身不存在为0,那么就会导致0^1为1,反倒存在了,所以不可以用^
我们可以使用我们的位图进行排序
public static void main(String[] args) {
int[] array = {1,3,2,13,10,3,14,18,3};
final bitmap bitSet = new bitmap(18);
for (int tmp:array
) {
bitSet.setElem(tmp);
}
for (int i = 0; i < bitSet.elem.length; i++) {
for (int j = 0; j < 8; j++) {
if((bitSet.elem[i] & (1 << j) ) != 0 ) {
System.out.println(i*8+j);
}
}
}
}其实位图我们Java也给我们实现过了

 但是他的底层是long类型的数组 而我们是byte类型的
但是他的底层是long类型的数组 而我们是byte类型的
那我们来总结一下位图的应用
1.快速查找某个数据(适合处理整数)是否在集合中
2.排序+去重
3.求两个集合的交集,并集
(三)布隆过滤器
我们上面说的位图,适合存储整数,如果是对象,那我们要存到那一个byte位?所以我们就出现了布隆过滤器
布隆过滤器是哈希和位图思想的结合
之前我们有一篇博客讲了布隆过滤器解决缓存穿透的问题 我们说布隆过滤器用于一些可以存在误判率的场景下,因为布隆过滤器是通过多个哈希函数多次将数据给存放到位图上
像这样

但是因为我们在多次插入后可能会出现这种场景

我们发现不同数据hash后可能会落到同一个格子,但是还好这个还有一位不同,更极端点的例子

一个数据多次hash,都落到了1位置上,这样就会判断它存在,但是它实际上是不存在的,此时就会出现误判
所以布隆过滤器对于结果来说,存在不一定存在,不存在一定不存在
布隆过滤器的优缺点:
优点:
1.增加和查询元素的时间复杂度为O(1)
2.布隆过滤器不存元素本身,所以适合要保密的场景
3.布隆过滤器由于使用了位图,很节省空间
4.数据量很大时,布隆过滤器可以表示全集(也就是能表示更多的元素)
5.适用相同hash函数的布隆过滤器可以进行交,并,差运算
缺点:
1.存在一定误判率
2.不能获取元素本身(hash不可逆)
3.一般不能删除元素(因为多个元素可能hash到一个位置上)
4.这样删除会存在计数回绕问题

总结下布隆过滤器:适合一些非整数的数据,通过hash+位图的思想,查找的时间复杂度和hash函数个数有关但都是常数,也不会太大,存储的不是信息本身只能判断数据是否存在,但是有误判率
(四)海量数据面试题
1.给定100亿个整数,设计找到值出现一次的整数
解法一:哈希切割
我们把这100亿个整数哈希到不同小文件中,这样相同的数字是会在一起的,然后遍历每个小文件,记录只出现一次的整数到另一个文件中,这样就能判断那个数字只出现一次

解法二:位图
我们把这100亿个整数放到两个位图中

我们适用二进制计数的方式,这样只出现一次的整数就是0 1,然后我们遍历整个位图就可以得到了。
当然也可以只用一个位图,那就是两个bit位存一个数据

这样我们需要/4和%4找位置了
2.给定两个文件分别有100亿个整数,但是我们只有1g内存,如何找到两个文件交集
解法一:哈希切割
我们依然将两个文件分别hash成多个小文件,这样相同的数据大概率在同一个文件中,然后我们求这两个文件的交集放到另一个文件中

解法二:位图
我们将第一个文件的数据放到位图中,然后遍历第二个文件,如果在位图中存在了,那么就是两个文件的交集
3.给两个文件,分别有100亿个query,我们只有1g内存,如何找两个文件交集?给出精确算法和近似算法
注意我们这题是query,那就说明不是整数,那就不适合用位图,但是我们可以适用布隆过滤器
解法一:哈希切割(精确算法)
我们依然将两个文件分别hash成多个小文件,这样相同的数据大概率在同一个文件中,然后我们求这两个文件的交集放到另一个文件中(跟上面一样)
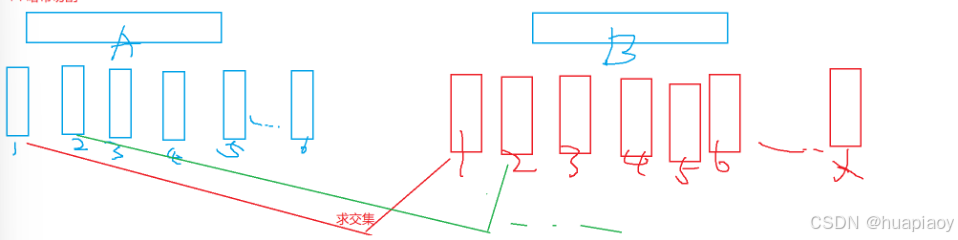
解法二:近似算法
把第一个文件的query映射到布隆过滤器中,然后读第二个文件,把每个query都放到布隆过滤器查找(有误判率)所以是近似算法
那我们来总结一下:哈希切割是比较通用的方法,通过hash函数把相同的数据都放到一个文件中,然后进行判断和处理
位图适合整型数据的处理,而布隆过滤器是适合允许有一定误报率的处理