机器学习导论笔记
引言
概念
人工智能(AL)
机器学习(ML)
人工智能包括了感知、决策和行动三个方面的能力。
机器学习可以分为监督学习、无监督学习、(半监督学习、)强化学习。
监督学习分为分类问题、回归问题、排序问题三大类。
无监督:在数据中发现规律。例:聚类、密度估计、降维。
强化学习
机器学习的4个基本元素
1.特定样本集、2.目标函数、3.模型、4.优化过程、优化算法。

机器学习模型的性能评估
均方误差、平均绝对误差或最大误差(评估有监督学习的回归)
错误率、准确率(评估有监督学习的分类)
精度(又叫查准率)、召回率(又叫查全率)(评估有监督的二分类)P15

F1=2*Pr*Re/(Pr+Re) //F1值综合考虑了精度和召回率,值越大,模型越准确。
精度和召回率是相矛盾的指标。下图是P-R曲线。

ROC曲线:横轴为假阳率,纵轴为真阳率。
混淆矩阵(评估有监督的多分类):主对角线的元素之和为正确分类的样本数,其他元素之和为错误分类的样本数。对角线的值越大,分类器准确率越高。
一些概念
泛化:一个模型对于在训练过程中未曾见过的数据的表现能力。也就是说,一个具有良好泛化能力的模型在训练集之外的数据上也能表现出色。
过拟合:过拟合是指为了得到一致假设而使假设变得过度严格;在训练误差达到很理想的结果,但在测试集误差很大。训练集获得的过程难免引入噪声,而训练过程模型过度拟合了噪声的趋势。解决方法增加数据集、降低模型复杂度、正则化。
欠拟合:欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。/模型过于简单,无法表达数据中较复杂的变换规律,训练误差无法下降到较小的程度。
正则化:保持训练集规模条件下的降低过拟合方法。
笔记





概率基础
贝叶斯概率基础:描述两个相关的随机事件或随机变量的概率关系。
概念
1.先验概率
2.条件概率
3.后验概率
4.全概率
5.贝叶斯
贝叶斯分类器
用贝叶斯公式解决分类问题,预测出样本属于每个类的概率。
三种贝叶斯分类器
1.最小错误概率贝叶斯分类器
使错误率最小,后验概率最大的类作为分类输出,前提条件使假设所有错误的代价是平等的。
2.最小风险贝叶斯分类器
还考虑了采取的分类策略后的后果。


步骤

典型题目:流感传播如何对待疑似病例(考虑对社会资源损失的影响)。
3.朴素贝叶斯分类器(假设特征向量的各个分量相互独立)
若为离散,分类器的预测函数为:
若为连续,分类器的预测函数为:

典型题目:西瓜分类。
笔记




回归分析
一般情况下,用于预测。研究因变量(目标变量)与自变量(预测变量/特征)之间的关系。
通过学习得到模型

确定模型参数的过程称为学习过程或训练过程,带入新输入计算回归输出称为预测或推断。
回归的目的
建立一个回归函数/方程来预测目标值,回归求解就是求回归方程的回归系数。
评估因变量和自变量是否显著相关,评估多个自变量对因变量的影响强度。
最大似然
许多机器学习模型属于参数化模型,模型的表达式受一组参数控制,即。对这类参数模型确定目标函数后,通过在训练集上做优化求出参数向量
,最大似然方法是通过概率方法确定目标函数,通过优化求得模型参数的常用技术。若通过概率方法表达这类模型时,得到的概率表达式中包含了待求的参数,则其概率表达式可表示成
的形式,首先通过这种概率形式给出似然函数的一个定义。
似然函数。若将表达样本数据的随机向量的概率密度函数中的x固定(即x取样本值),将
作为自变量,考虑
变化对
的影响,这时将
称为似然函数,可用
=
表示似然函数。
最大似然估计。对于一个样本向量x,令时使似然函数
达到最大,则
为参数
的最大似然估计(MLE)。
,其中
表示
的取值空间。
可设=
表示似然函数,也可直接用
作为似然函数。实际上更方便的是取似然函数的对数
,称其为对数似然函数。由于对数函数是0到正无穷区间的严格增函数,所以
和
的最大值点一致。
求最大值点,对或
求导,最后求得参数
。
最小二乘法

最小二乘法首先需要计算的逆矩阵。
最小二乘法只适用于线性模型。
参考文章:机器学习十大经典算法之最小二乘法 - 知乎
梯度下降
不能用最小二乘法的可以用梯度下降。
每个方向的偏导函数,就是梯度。
梯度下降法:从初始点开始,不断调整步伐和方向,找出最优解。
必须将所有资料点通通进行运算产生梯度。
随机梯度下降算法(SGD)
随机抽取足够多的资料点。
正则化
给线性回归的目标函数加上正则化项,可以提高泛化能力,结果过拟合。

L1正则化项:绝对值
L2正则化项:平方
线性回归和逻辑回归
线性回归主要是预测。
逻辑回归将线性回归的值域映射到[0,1]区间内,大于临界一类,小于临界值分到另一类,从而实现二分类。
笔记

分类算法
决策边界:特征空间中类别之间的界限。可以帮助我们直观地理解模型的分类效果,特别是在低维特征空间中。
线性判别函数模型——Fisher(线性分类器)
LDA思想:投影后类内方差最小,类间方差最大。
决策树
分层的决策结构,用于分类和回归,是非参数学习方法,归纳推理类算法。树形结构。
ID3(按信息增益)
C4.5(按信息增益率)
CART
只要剪枝后错误没增加,就可以剪枝。
笔记

聚类和主成分分析
聚类算法
用于无监督分析。
K均值聚类(K-means)
为了分类。
具体步骤
K表示初始中心点个数(计划聚类数),Means求中心点到其他数据点距离的平均值。
1.随机设置K个特征空间内的点,作为初始的聚类中心;
2.对于每个点计算到K个中心的距离;
3.重新计算出每个聚类的新中心点(平均值);
4.如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步。
当迭代结果不变,停下。
主成分分析PCA:高维数据由几个隐向量组成
为了降维,投影,最后方便分类。
人工神经网络
要求:给函数(如sigmoid、tanh)会计算输出。
激活函数
激活函数是为了引入非线性因素。
早期激活函数:
1.符号激活函数
2.门限激活函数
饱和激活函数:sigmoid、tanh
1.sigmoid函数,近似门控函数,取值范围[0,1]
2.tanh双曲正切函数,近似符号函数,取值范围(-1,1)
非饱和激活函数:ReLU、Leaky ReLU
1.ReLU
2.Leaky ReLU(渗漏ReLU)


感知机
感知机是输入特征向量,输出分类,以阶梯函数激活的人工神经元,典型的线性分类器,可做二分类决策。
感知机算法设定准则函数的依据是最终分类器要能正确分类所有的样本。
感知机算法的准则函数等于所有错分样本函数值之和乘-1。(存在错分,其值大于0),都分类正确才能取到极小值。
修改权向量/权向量递推:
神经网络的目标函数J(w): 求系数

批量梯度法
随机梯度法
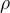 学习速率(调整步长)
学习速率(调整步长)
实质是梯度下降法中,每一步向当前负梯度方向调整的大小因子,也就是分类器学习到最优权向量的速度。
梯度下降法训练分类器,精度和速度间存在矛盾。
多层感知机(MLP)
至少包含一个隐藏层。
单层只有输入层和输出层,只能学习线性函数。
多层至少包含一个隐藏层,可以学习非线性函数。
神经网络目标函数和优化
梯度算法
梯度随机
小批量随机梯度
链式法则导出反向传播算法(BP)
强化学习
基本概念:
智能体
环境
笔记

强化学习里智能体和环境的交互通过马尔科夫决策过程(MDP)进行建模。
五元组(S状态集合,A,P,r,y)
A(S)状态下可能的动作集合。
表示状态s下,采取行动
时跳转到
的转移概率。
奖励函数r:
折扣因子y属于[0,1]之间。
强化学习要学习策略从状态到行为的映射函数。
强化学习的决策机制
估值函数衡量某状态最终能够获得多少累计奖励。
Q函数衡量某个状态下采取某个行为后,最终能获得多少累计奖励。
马尔可夫性质:某时刻的状态 只取决于上一时刻的状态
,被称为具有马尔可夫性质。
贝尔曼方程是强化学习中的一个重要数学工具,它描述了在不同状态和行动下,如何计算和优化状态值或动作值。这个方程通过递归来定义最优解,通常以动态规划的形式出现,帮助确定在给定的策略下,从当前状态到未来状态可能的最大或最小累积回报。
强化学习要获得长期的累计收益最大化,所以不能局限于当前即时奖励,还要考虑到未来可能的奖励。
典型算法
Q-learning:不断更新Q值函数。
-Greedy贪婪算法:以
概率随机选择行为,1-
概率选择目前带来最大收益的行为,更新收益函数(Q)。
强化学习分类
按环境是否划分:免模型学习、有模型学习
按学习方式划分:在线策略(必须是本人边玩边学习)、离线策略(还可以选择从别人的经验学习)
按学习目标划分:基于策略(输出概率,根据概率选动作)、基于价值(输出动作价值,根据动作价值选)