PostgreSQL之Checkpoint检查点进程
在文章PostgreSQL之整体架构中我们学习了PG数据库中有好几个background后台进程,其中一个后台进程是checkpointer检查点进程。这里我们学习一下什么是checkpointer检查点进程以及它的用处。
checkpointer后台进程主要工作就是做checkpoint的,它在以下几种情况下会执行checkpoint工作:
- 上一次checkpoint到现在达到checkpoint_timeout超时时间,默认为5分钟(300秒)。
- 在PG 9.4或更早版本,自上一次checkpoint以来,用完checkpoint_segments指定的WAL段文件个数(默认为3个)。
- 在PG9.5或之后版本,pg_xlog(在PG 10版本及以后称为pg_wal)中的WAL段文件总大小超过max_wal_size值(默认为1GB,64个文件)。
当然,由超级用户手工触发CHECKPOINT命令也可以调度checkpoint工作。
下面再了解一下checkpoint过程都包含哪些内容。
注:在PG 9.1或早期版本中,由后台写进程(background writer process)同时完成checkpoint工作和刷脏页的工作。
了解checkpoint过程
checkpoint进程主要有两方面的用途:
- 为数据库恢复做准备
- 将共享内存中的脏页刷到磁盘
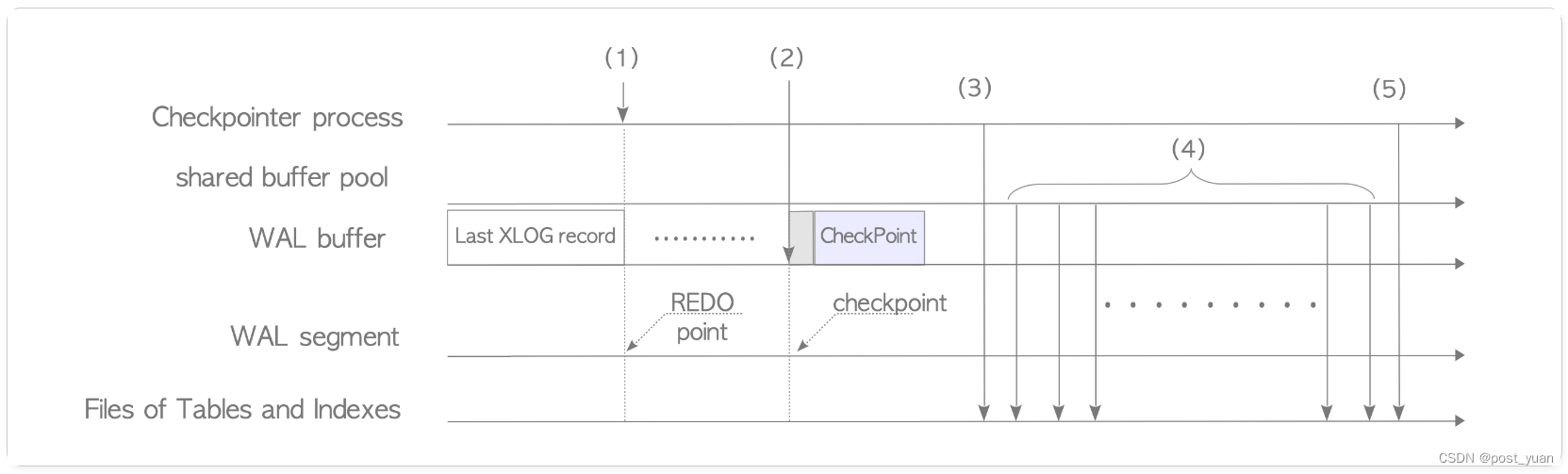
上图是关于PG中checkpoint的内部流程,可以总结如下:
- 在checkpoint进程开始后,会在内存中保存一个重做点(REDO point)。重做点是一个位置,记录最近一次checkpoint启动时写入XLOG记录的地址,这个地址也是数据库恢复的起始地址。
- 写入一条checkpoint对应的XLOG记录到WAL buffer中。记录的数据内容可参考CheckPoint数据结构,其中包含几个变量,比如上一步中的重做点。
- 共享内存中所有的数据被刷写到磁盘上(比如clog等)。
- 共享缓冲池中所有的脏页逐渐被刷写到磁盘上。
- 更新pg_control文件。pg_control文件包含一个基础信息,如checkpoint记录的地址。
总结来说,从数据库恢复的角度看,checkpoint过程创建一个包含重做点的checkpoint记录,以及把checkpoint地址和其他一些信息保存到pg_control文件。
因此,PG启动后可以根据pg_control控制文件中记录的重做点并从对应的位置回放WAL中的数据,从而完成数据库的恢复过程。
关于pg_control文件
由于pg_control文件中保存了checkpoint的基本信息,因此这个文件对数据库恢复非常重要,如果这个文件被损坏,数据库就不能进行正常的恢复。
pg_control文件中保存超过40个选项,其中有几个是主要的:
- State - 保存最近一次checkpoint开始时的数据库状态。总共有7个状态,'start up’表示数据库处于启动状态;'shut down’表示数据库正在下线;'in production’表示数据库正在运行;等等。
- Latest checkpoint location - 最近一次checkpoint记录的LSN位置
- Prior checkpoint location - 前一次checkpoint记录的LSN位置,在PG 11版本开始已经被废弃。
以下是一个pg_control内容输出示例:
postgres> pg_controldata /usr/local/pgsql/data
pg_control version number: 937
Catalog version number: 201405111
Database system identifier: 6035535450242021944
Database cluster state: in production
pg_control last modified: Thu Mar 30 15:16:38 2023
Latest checkpoint location: 0/C000F48
Prior checkpoint location: 0/C000E70
... snip ...