使用wav2vec 2.0进行音位分类任务的研究总结
使用wav2vec 2.0进行音位分类任务的研究总结
原文名称: Using wav2vec 2.0 for phonetic classification tasks: methodological aspects
研究背景
自监督学习在语音中的应用
- 自监督学习在自动语音识别任务中表现出色,例如说话人识别和验证。
- 变换器模型(如wav2vec 2.0)在处理几秒钟的语音序列时考虑上下文信息。
- 研究问题:从单个音素提取的向量表示是否比从较长序列中提取的向量表示在检测鼻音方面表现更好?
研究方法
序列长度对比
- 方法一:在音素持续时间内提取向量。
- 方法二:在音素两侧各增加一秒,然后恢复中央部分。
数据资源与实验设置
训练和测试资源
训练数据:
- 使用四个不同的语料库:NCCFr、ESTER、PTSVOX 和 BREF。
- 提取8个元音和6个鼻音及口音辅音,总计120,000个训练样本。
测试数据 :
- 测试数据包括声学和生理数据,通过Aeromask面罩同时收集。
- 六名男性法语母语者参与录音,记录了269个声音样本。

实验协议
方法论
wav2vec 2.0 模型
- 使用预训练的“wav2vec 2.0-FR-3K-large-LeBenchmark”模型。
- 输入为原始音频信号,通过卷积编码器处理,每25毫秒转换成一个向量序列。
- Transformer层捕捉整个序列的信息,包含24层,每层产生1,024维的潜在表示。
向量表示生成
- 方法一:直接从音素边界提取向量,使用最大池化策略。
- 方法二:添加前后各一秒的上下文信息,再从中提取中央部分的向量。
特征探测
- 使用逻辑回归模型判断音素是否有鼻音特征。
- 在训练和验证数据集上训练模型,然后应用于测试数据。
结果
鼻音检测性能
不同Transformer层的表现
- 长序列在几乎所有层中都包含鼻音信息,而短序列在CNN编码器和前几层中鼻音特征更明显。
- 第一层Transformer层在长序列中表现最佳,整体准确率为94.05%,短序列为81.04%。

音素分类准确性
- 某些音素如[˜O,E,m,n,d]分类准确率高,而其他音素如[o,a]分类困难。
- 鼻音元音中,[˜E]最难检测,[˜O]最容易检测。

分类器结果与生理数据比较
相关性分析
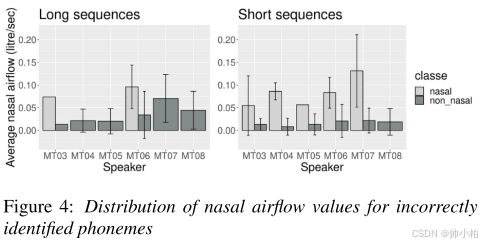
- 使用Pearson相关系数分析鼻音概率与鼻气流的关系。
- 归一化后的鼻气流与鼻音概率的相关性更强,且因音素和说话人不同而异。
- 对于某些说话人,鼻气流可以解释错误分类的原因。

总体而言,鼻音概率与按音素和说话人归一化的值最密切相关。这表明鼻腔气流是音素和说话人特有的。其次,说话人MT04的相关性最强,这一观察结果对两个模型都是常见的。然而,具有最低相关性的说话人根据音频片段长度和鼻腔气流测量而不同。
讨论与结论
序列长度对鼻音检测的影响
- 长序列在鼻音检测中表现优于短序列,整体准确率更高。
- 模型行为因音素和说话人而异,反映了发音器官位置的变化。
生理数据的验证
- 鼻气流与鼻音概率之间存在显著相关性,验证了模型的有效性。
- 长序列更好地捕捉了音素相关的鼻音特征和音素间的音系对比。
局限与未来研究
- 尽管鼻气流减少,某些鼻音仍可感知,需要进一步的感知研究来验证模型结果。
- 未来研究将关注更多情境下的鼻音检测,并探索感知层面的验证。