pytorch卷积的入门操作
左侧图像模拟一个图像数据,当我们用右侧的卷积核对其进行卷积操作时,设置stride = 1或不设置默认为1,每次对应的格子相乘完之后,卷积核向右移动一格,再次对应相乘得到结果,如下过程简单演示。
卷积核就像一个小窗口,在图像上滑动,每次观察 3x3 大小的区域。
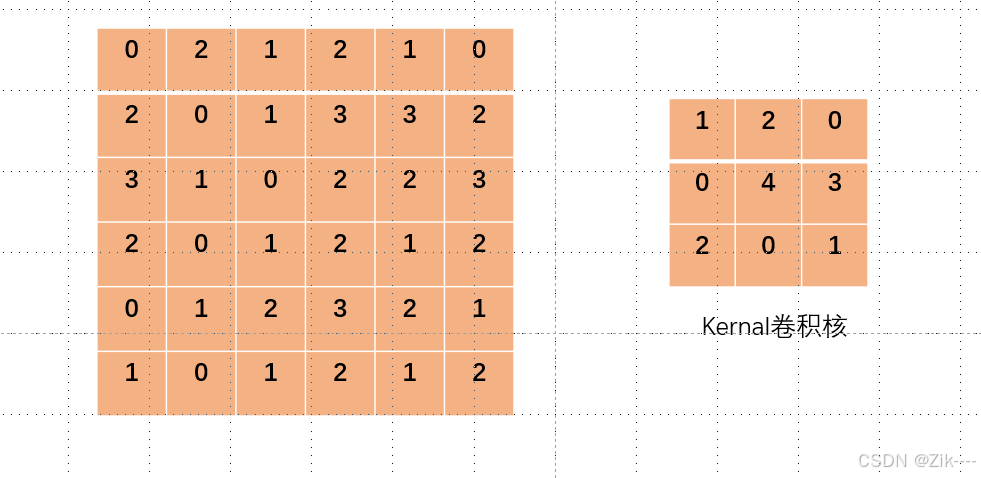
为了方便对比演示,将卷积核更改了一下颜色。
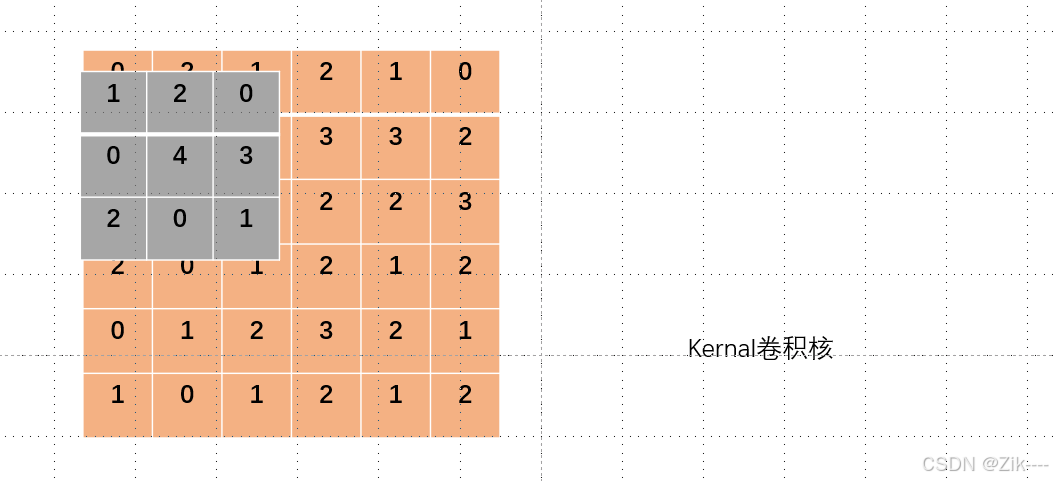
如下图,卷积核从左上角开始进行第一次卷积操作。
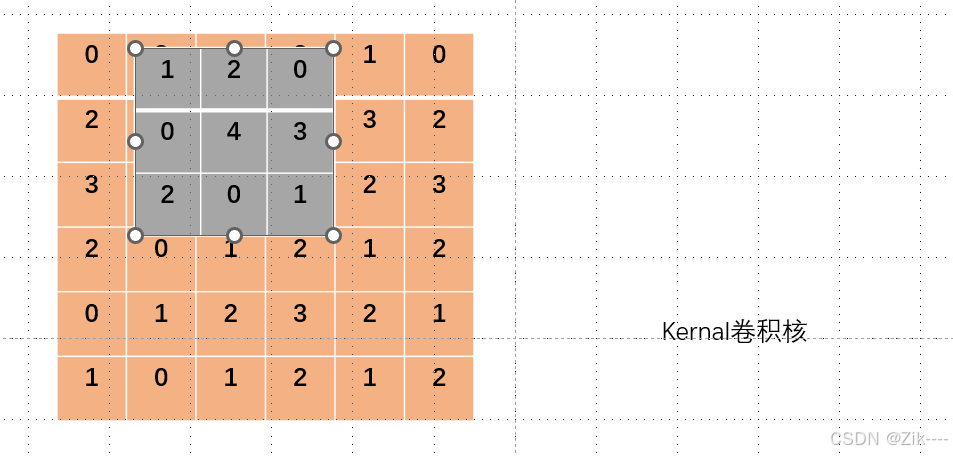
卷积核向右移动一个像素,进行第二次卷积操作。
当卷积核在图像上滑动到右边(或其他边界位置)没有数据时,如下图,通常有以下几种处理方式:
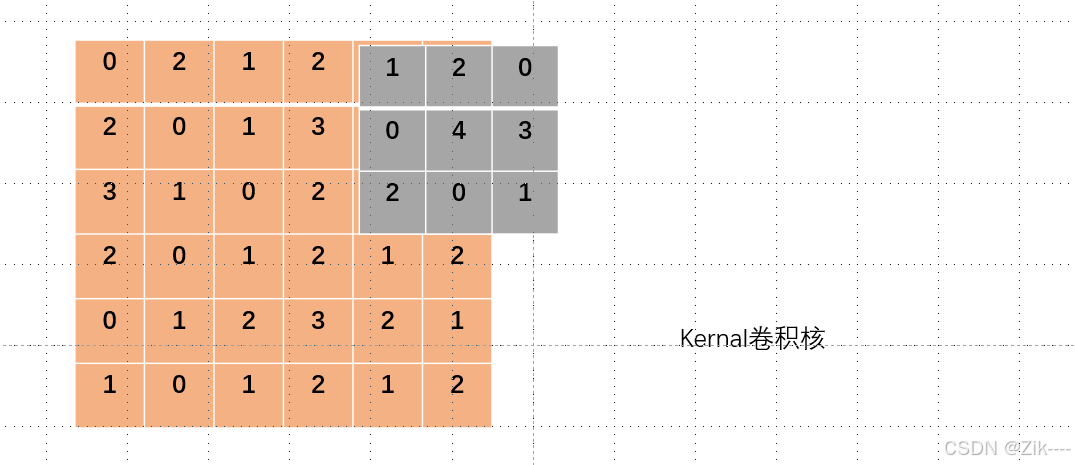
1. 零填充(Zero - Padding)
在原始图像的边界周围填充一定数量的 0。这样,当卷积核滑动到边界时,卷积核覆盖的区域仍然有数据(虽然是填充的 0)。在 PyTorch 中使用 nn.Conv2d 时,padding 参数可以设置填充的大小,如 padding = 1 就表示在图像四周各填充 1 行 / 列,如下图。
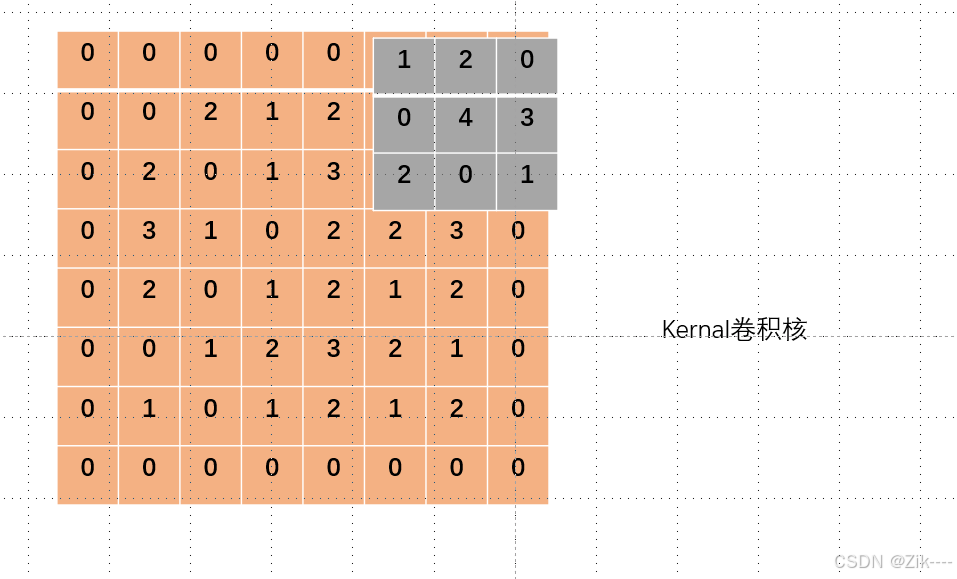
2. 复制填充(Replication Padding)
不是填充 0,而是复制边界上的像素值来填充。例如,如果图像最右边的像素值是 5,那么在右边填充时,填充的像素值都为 5。这种方式可以在一定程度上保留边界的特征信息,避免因填充 0 而可能引入的噪声或特征突变。在一些深度学习框架中,有专门的函数或参数设置来实现复制填充。
3. 不填充(No Padding)
当卷积核滑动到边界没有数据时,就停止滑动。这种情况下,输出特征图的尺寸会比输入图像小。计算公式为如下,其中 Win 和 Hin 是输入图像的宽和高, K是卷积核的大小,S 是步长。这种方式会丢失边界部分的信息,可能对一些需要完整边界信息的任务产生影响。
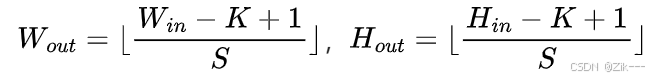
下面,模拟一下这个过程。
代码演示:
import torch
import torch.nn.functional as F
# 定义输入张量 input,它是一个 4x4 的二维矩阵
# 这个矩阵模拟了待卷积处理的图像数据
input = torch.tensor([
[0, 1, 2, 3],
[2, 1, 3, 2],
[0, 1, 3, 0],
[0, 4, 1, 2],
])
# 定义卷积核张量 kernel,它是一个 3x3 的二维矩阵
# 卷积核用于在输入数据上进行卷积操作,提取特征
kernel = torch.tensor([
[2, 1, 0],
[2, 1, 0],
[1, 0, 2],
])
# 此时的input和kernalshape不符合要求
print(input.shape)
# 为了能将输入数据用于 PyTorch 的二维卷积函数 F.conv2d,需要调整其形状
# F.conv2d 函数要求输入数据的形状为 (batch_size, in_channels, height, width)
# 这里将 input 调整为形状为 (1, 1, 4, 4) 的四维张量,其中 batch_size=1 表示一批只有一个样本,in_channels=1 表示输入通道数为 1
input = torch.reshape(input, (1, 1, 4, 4))
# 同样,卷积核也需要调整形状以符合 F.conv2d 函数的要求
# 要求卷积核的形状为 (out_channels, in_channels, kernel_height, kernel_width)
# 这里将 kernel 调整为形状为 (1, 1, 3, 3) 的四维张量,out_channels=1 表示输出通道数为 1
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# 使用 F.conv2d 函数进行二维卷积操作,stride=1 表示卷积核每次移动的步长为 1 个像素
# 卷积操作会在输入数据上滑动卷积核,计算对应位置的乘积和,得到卷积结果
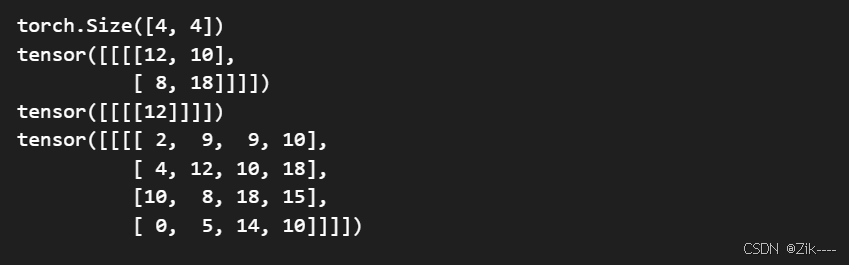
output1 = F.conv2d(input, kernel, stride=1)
# 再次进行二维卷积操作,不过这次步长设置为 2,即卷积核每次移动 2 个像素
# 步长的改变会影响卷积结果的大小
output2 = F.conv2d(input, kernel, stride=2)
output3 = F.conv2d(input,kernel,stride=1,padding=1)
# 打印步长为 1 时的卷积结果
print(output1)
# 打印步长为 2 时的卷积结果
print(output2)
# 设置padding = 1,对原图形二维矩阵上下左右各填充数字一列,一行数字
print(output3)
输出结果:
可自己算一算,看看结果是否一致。
下面进行实际的创建自己的神经网络,并对图像数据进行卷积操作。
代码演示:
import torch
import torchvision
# 从 torchvision 的转换模块中导入 ToTensor 类,用于将图像数据转换为张量
from torchvision.transforms import ToTensor
# 从 torch 的神经网络模块中导入必要的类
from torch.nn import Module, Conv2d
# 从 torch 的数据加载器模块中导入 DataLoader 类,用于批量加载数据
from torch.utils.data import DataLoader
# 从 torch 的可视化工具模块中导入 SummaryWriter 类,用于将训练过程中的数据写入 TensorBoard
from torch.utils.tensorboard import SummaryWriter
# 卷积操作
# 加载 CIFAR-10 数据集
# root 参数指定数据集的存储路径,这里设置为 './dataset',表示在当前目录下的 dataset 文件夹中存储数据集
# train=False 表示加载测试集,CIFAR-10 数据集分为训练集和测试集,这里选择测试集
# transform=ToTensor() 表示将图像数据转换为张量,方便后续的神经网络处理
# download=False 表示如果数据集不存在则不进行下载,需要确保数据集已经存在于指定路径
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=ToTensor(), download=False)
# 使用 DataLoader 批量加载数据集
# batch_size=64 表示每个批次包含 64 个样本,就像我们把一叠书(数据集)分成一捆一捆的,每捆有 64 本
dataloader = DataLoader(dataset, batch_size=64)
# 定义一个自定义的神经网络模块 zzy,继承自 nn.Module
# nn.Module 是 PyTorch 中所有神经网络模块的基类,就像一个大的工具箱,我们要在这个工具箱的基础上创建自己的小工具
class zzy(Module):
def __init__(self):
# 调用父类的构造函数进行初始化,就像我们在制作小工具之前,先把大工具箱里的基本功能准备好
super(zzy, self).__init__()
# 定义一个二维卷积层
# in_channels=3 表示输入图像的通道数为 3(RGB 图像),可以想象成一幅彩色画有红、绿、蓝三个颜色通道
# out_channels=6 表示输出特征图的通道数为 6,这意味着我们会用 6 个不同的“放大镜”(卷积核)去观察这幅彩色画,得到 6 种不同的观察结果
# kernel_size=3 表示卷积核的大小为 3x3,卷积核就像一个小窗口,在图像上滑动,每次观察 3x3 大小的区域
# stride=1 表示卷积核的步长为 1,即每次滑动一个像素,就像我们拿着小窗口一格一格地移动
# padding=0 表示不进行填充,填充就像是给图像周围加一圈边框,这里不加边框
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
# 前向传播过程,将输入 x 通过卷积层 conv1 进行处理
# 就像我们把彩色画放进小工具里,经过“放大镜”的观察,得到新的图像特征
x = self.conv1(x)
return x
# 创建 zzy 类的一个实例
# 这就像我们根据设计好的小工具图纸,制作出了一个实际可用的小工具
zzy1 = zzy()
# 打印小工具的结构,让我们看看它长什么样
print(zzy1)
# 创建一个 SummaryWriter 对象,指定日志存储路径为 '/logs'
# SummaryWriter 就像一个记录员,会把我们训练过程中的数据记录下来,方便我们后续查看
writer = SummaryWriter('/logs')
# 初始化一个计数器,用于记录当前处理的批次数量
step = 0
# 遍历数据加载器中的每个批次的数据
# 就像我们一捆一捆地处理书,每次处理一捆
for data in dataloader:
# 从批次数据中解包出图像数据和对应的标签
# 可以想象成我们从一捆书中挑出了书(图像)和书的编号(标签)
imgs, targets = data
# 将图像数据输入到我们创建的神经网络模块中进行处理,得到输出
# 就像把书放进小工具里进行加工,得到新的结果
output = zzy1(imgs)
# 打印输入图像的形状,让我们了解输入数据的格式
print(imgs.shape)
# 打印输出特征图的形状,让我们了解经过卷积处理后的数据格式
print(output.shape)
# 使用 SummaryWriter 将输入图像写入 TensorBoard,方便我们可视化输入数据
# 就像记录员把原始的书拍了张照片,存起来供我们查看
writer.add_images('input', imgs, step)
# 尝试将输出特征图的形状调整为 (-1, 3, 30, 30),但这里有个问题,torch.reshape 不会改变原张量,需要赋值给原变量
# 这里的调整是为了让输出特征图能够以图像的形式可视化,就像我们把加工后的结果重新整理成可以展示的样子
output = torch.reshape(output, (-1, 3, 30, 30))
# 使用 SummaryWriter 将调整形状后的输出特征图写入 TensorBoard,方便我们可视化处理后的结果
# 就像记录员把加工后的书也拍了张照片,存起来供我们查看
writer.add_images('output', output, step)
# 批次计数器加 1,表示处理完了一个批次
step += 1
# 关闭 SummaryWriter,就像记录员完成了工作,把本子合上
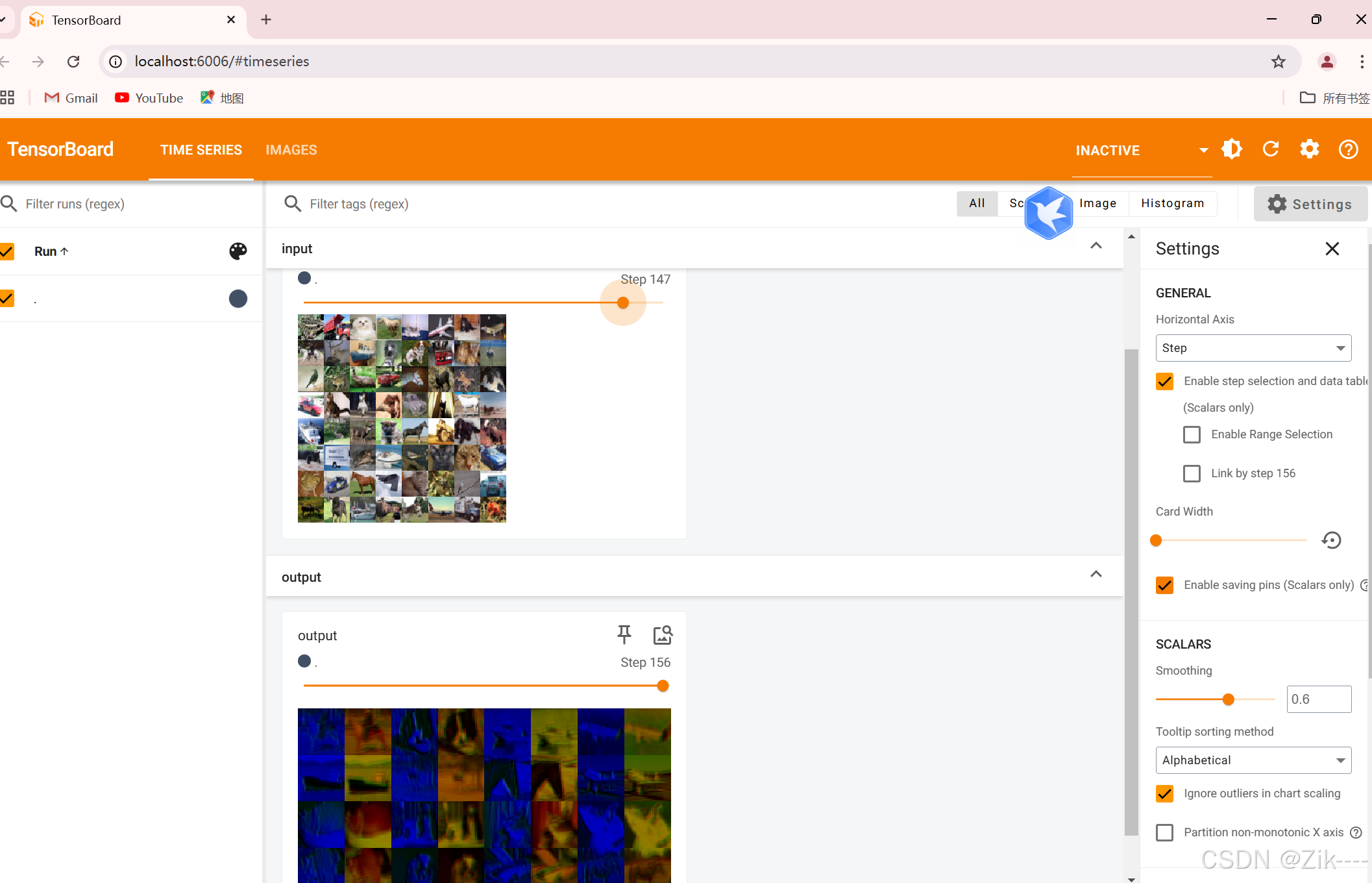
writer.close()此时在终端输入指令 tensorboard --logdir=/logs,启动 TensorBoard 服务后,会在终端输出一个 URL,通常是 http://localhost:6006 。打开你的浏览器,访问该 URL,即可看到 TensorBoard 的界面,如下。
上方是原图像,下方是经过卷积操作后的图像。