《企业应用架构模式》笔记
领域逻辑
表模块和数据集一起工作->
先查询出一个记录集,再根据数据集生成一个(如合同)对象,然后调用合同对象的方法。
这看起来很想service查询出一个对象,但调用的是对象的方法,这看起来像是充血模型,如果getter和setter也算,那贫血模型才算,不然我们是调用service的方法。当然,service是把充血模型拆出来了。说到底这个时候查询的方法反而不像是在整个领域模型中了
那如果我们灵活些,把出了查询的mapper以外的部分当作,额,,是不是就是表模块这种组织形式了呢?
表模块是事务脚本和领域模型的一个中间地带。它围绕表而非直接围绕过程来组织领域逻辑,提供了更多的结构,而且更容易发现和移除冗余代码。
同领域模型相比,你无法应用许多在领域模型中可以使用的组织细粒度逻辑结构的技术,例如继承承、策略和其他面向对象的设计模式。
面向对象的好处是将程序结构化吗
表模块最大的优势在于与双层架构的已有代码的衔接。
双层架构、GUI程序通常设计成与sql返回的记录集工作,而表模块也再记录集之上工作。
加了记录集就成三层了。相当于重构了
许多平台都使用这种开发网格,尤其是微软的COM和.NET
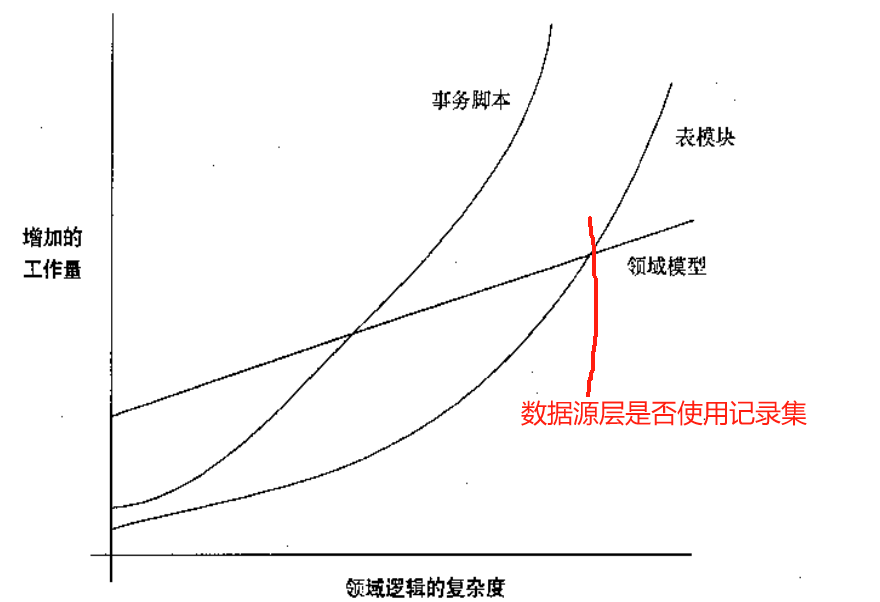
书中并没有讨论什么是领域逻辑的复杂度,,为什么银行业务甚至直接用存储过程就可以?那种是不复杂的业务逻辑吗?企业应用经常修改算是复杂的业务逻辑吗?一个事件牵扯一堆事件,且经常修改算是吗?
数据源层
数据源层的作用是与应用需要的基础设施的不同部分进行通信。
对web开发者而言,在数据层可以编写和数据库通信的相关代码已经是很常见的应用场景了。但这里应当注意到,数据源可以是任何数据来源,比如其他系统(如调用微服务接口)
关系数据库之所以取得成功,最重要的原因之一就是SQL的存在,它是数据库通信标准语言。
从3.1的第二段(解释为什么将sql放在单独的类中)来看,似乎当时后端程序猿和DBA并没有混为一谈,程序员不一定擅长sql,DBA则不接触代码(文中提到他们希望能得到访问数据库的sql,我猜测他们只是负责管理数据库、建立库表之类的?)
不管怎么说,对于现在的开发者而言,单独一层管理sql也是个方便的选择。
行数据入口
查询语句的每一行产生一个实例。用面向对象的方式看待数据
查询出的一行不一定是一个表的吧?也不一定是一个领域
表数据入口 返回记录集
对数据库中的每个表,仅仅需要一个对象来管理。
记录集是一种通用数据结构?
GUI工具通常使用记录集
表数据入口与记录集非常匹配,这使得它们成为使用表模块的当然选择。它也是一个组织存储过程的模式。
活动记录?
- 在一片博客中,称Active Record and Data Mapper 是ORM的两种流行的实现。
领域和数据库表一一对应?这几把讲的都是啥,下面的数据映射器?
从另一个角度来考虑活动记录,就是从行数据入口开始,然后把领域逻辑加入到类中,特别是在从多个事务脚本中发现了重复代码的时候。
数据映射器
一种更好的办法是把领域模型和数据库完金独立,可以让间接层完成领域对象和数据库表之间的映射。这个数据映射器(见图3-4)处理数据库和领域模型之间所有的存取操作,并且允许双方都能独立变化。这是数据库映射架构中最复杂的架构,但它的好处是把两个层完全独立了。
遇事不决加一层是吧.还最复杂的架构,您前面那也配叫数据库映射架构?好吧好吧,就当他们是吧
独立变化?哦哦哦我明白了,内存改完不同步数据库,直到调用方法?看来前面的并没有getter setter这种情况了,前面的都是做某种操作的时候直接update之类来代替getter/setter?
简单的逻辑用活动记录也行,复杂的用数据映射器.其实就是加了一层
即使用数据映射器作为首选持久化机制,还是可以使用数据入口来封装被视为外部接口的表或者服务。
说到最后主要还是领域模型难以持久化。看起来领域和实体实际上不是什么很匹配的概念。可能本来就是一个强调解耦,一个强调关系吧
作者推崇面向对象数据库。然后是数据映射器。我不太理解都买的商业OR工具有什么
还有一种面向对象数据库风格的逻辑层,如JDO
行为问题
工作单元:又加了一层控制何时加载对象
领域模型关联对象:延迟加载避免一次加载一批
3.3 读取数据
查找器方法
设计经验:
读取冗余行也可以,一次读很多行效率大于读很少的几行
join一次读取多个表可能比多次读取表更快?当然MF也说了一次查询最多三到四次join
读到这一段,下面说 设计一个入口获得相联结的表数据,或者通过一个数据映射器用一次调用加载多个领域对象。,可能数据映射器,,额,,还有上面的工作单元中间层,,是指,内存中对象保存的数据类似于缓存层?直接操作对象来改变其对应的数据库数据?这样一来,set方法可能其实就类似update,但是直接set到数据库里;工作单元相当于缓存策略里面的有中间manager管理的;
毕竟这个时候MF提出的领域模型的概念似乎还没有和javabean融合,没有getter一说。
3.4 结构映射模式
对象-关系映射的结构映射模式
表数据入口通常不需要;
行数据入口和活动记录可能会需要一些模式;
数据映射器需要全部模式。
对象和表处理“连接”关系的方法是相反的
这是范畴论的连接吗
一对多关系为例,对象可以保存多个其他对象的引用列表,数据库则是由多的一方保存1的一方的主键。
新出现的名词:外键映射,标识映射,依赖映射。
可能是指关系型数据库吧。因为下面又提到了多对多关系用的关联表映射。
还是没搞懂标识域是什么?一个成员变量,保存外键,而不是用引用?
继承
单表继承
具体表继承
类表继承
单表继承:一个层次中的所有类建立一个表。
说的这么玄乎,结果就是一个大表把所有父类和子类的属性都放上啊。“层次”指的是从父类和它的子类啊,咱对层次的理解是不是有些偏颇?
类表继承是类和表之间最简单的关系,但是它需要多个连接(join)操作来载人一个对象,这样通常损失了性能。
具体表继承避免了连接操作,允许从一个表中取得一个对象,但是改变起来比较困难。对超类的任何改变都不得不改变所有的表(还有映射代码)。改变层次结构自身会带来更大的改变。缺乏超类表也能使主键管理十分可怕,引用完整性也有问题,尽管它能减少超类表中的锁争夺。
而在某些数据库中,单表继承最大的弊端是浪费了空间,因为每一行都必须为每种可能的子类保留一些列,这就导致很多空列。然而,许多数据库都能很好地压缩浪费的表空间。单表继承的另一个问题在于它的大小将成为访问的瓶颈。它最大的好处是把所有的内容都放到一起,这样修改起来很容易并目避免了连接操作。
我们可以混合操作,比如一些字段放在大表里,一些作为附加字段。但这样设计十分复杂。
我们的实践中还有一种方法是放数据库的一列json中
映射到数据库
数据库方案是什么?是指“是否已经建立好了表”吗?
也许应该关注下ORM思想的诞生,这一层次
这本书还有个缺点,参考书目在电子版全都没有显示出来,,
web表现层
输入控制器:MVC中的控制器
看来model下面还有数据源层
两种模式:
- 页面控制器,为每个页面准备一个控制器
- 为每一种动作准备一个控制器
分布策略
本地的过程调用非常快
本地接口细粒度,方便拓展(有些像贫血模型)
远程接口粗粒度,一次做很多事情,减少调用次数
分布模型:CORBA
因此MF认为不要分布使用对象,而是用集群系统,在一个cpu部署所有对象并在其他节点部署他们