论文阅读笔记:MambaOut: Do We Really Need Mamba for Vision?
论文阅读笔记:MambaOut: Do We Really Need Mamba for Vision?
- 1 背景
- 2 创新点
- 3 方法
- 4 模块
- 4.1 Mamba适合什么任务
- 4.2 视觉识别任务是否有很长的序列
- 4.3 视觉任务是否需要因果token混合模式
- 4.4 关于Mamba对于视觉的必要性假设
- 5 效果
论文:https://arxiv.org/pdf/2405.07992
代码:https://github.com/yuweihao/MambaOut
1 背景
在现实中,基于SSM的视觉模型与最先进的卷积模型和基于注意力的模型相比,性能欠佳。这就产生了一个研究问题:在视觉中我们是否真的需要Mamba?
在本文中,作者研究了Mamba的性质,并从概念上总结了Mamba适合任务的两个关键特征:长序列和自回归,这是因为SSM固有的RNN机制。不幸的是,同时具备这两种特性的视觉任务不多。例如ImageNet上的图像分类不符合,而在COCO上的目标检测和实例分割以及ADE20K上的语义分割只符合长序列。另一方面,自回归特性要求每个token仅从之前和当前token中聚合信息,这一概念被称为token混合的因果模式。事实上,所有的视觉任务都属于理解域而非生成域,这意味着模型可以同时看到整幅图像。因此在视觉识别模型中对token混合施加额外的因果约束可能会导致性能下降。虽然该问题可以通过双向分支来缓解,但不可避免的是该问题在每个分支内持续存在。
基于以上的概念性讨论,作者提出如下两个假设:
-
假设1:SSM对于图像分类时没有必要的,因为这项任务既不符合长序列特征,也不符合自回归特征。
-
假设2:SSM对于目标检测、实例分割以及语义分割可能是有益的,因为他们遵循长序列特征,尽管他们不是自回归特征。
为了实验假设,作者通过堆叠门控CNN块开发了一系列名为MambaOut的模块。Gated CNN和Mamba block的关键区别在于SSM的存在,如图1(a)所示。实验结果表明,更简单的MambaOut模型在现实中的表现已经超过了Vision Mamba模型的表现,进而验证了假设1。同时,MambaOut在检测和分割任务中的表现不足与最先进的视觉Mamba模型相匹配。这强调了SSM在这些任务上的潜力,并有效的验证了假设2。

2 创新点
-
分析了SSM的类RNN机制,并从概念上总结出Mamba适用于具有长序列和自回归特性的任务。
-
考察了视觉任务的特征,并假设SSM在ImageNet上进行图像分类时不必要的,因为该任务不满足任何一个特征,但探索出SSM在检测和分割任务重的潜力仍然是具有价值的。
-
基于Gated CNN模块开发了一系列名为MambaOut的模型。
3 方法

与ResNet类似,MambaOut采用4阶段的分层架构。 D i D_i Di 表示第 i i i 阶段的通道尺寸。其中,Gated CNN块与Mamba块的区别在于Gated CNN块中没有SSM (状态空间模型)。
Gated CNN块的代码:

4 模块
4.1 Mamba适合什么任务
Mamba的token混合器是选择性SSM,它定义了四个与输入相关的参数
(
Δ
,
A
,
B
,
C
)
(\Delta,A,B,C)
(Δ,A,B,C),并将他们转换为
(
A
‾
,
B
‾
,
C
)
(\overline{A},\overline{B},C)
(A,B,C):

SSM的序列到序列的变换可以表示为:

其中,
t
t
t 表示时间步长,
x
t
x_t
xt 表示输入,
h
t
h_t
ht 表示隐藏状态,
y
t
y_t
yt 表示输出。方程2的循环性质将类RNN的SSM与因果注意力区分开。隐藏状态
h
h
h 可以看作是一个固定大小的存储器,存储了所有的历史信息,通过方程2,该记忆在保持大小不变的情况下更新,固有的大小意味着存储器与当前输入集成的计算复杂度保持恒定。相反,因果注意力存储了来自之前token的所有键值作为他的记忆,它通过在每个新输入中添加当前token的键值来扩展,这种存储器理论上是无损的,然而随着输入的token越来越多,内存大小也越来越大。图2进一步说明了类RNN模型和因果注意力在机制上的差异。

由于SSM的记忆本质上是有损的,因此在逻辑上不及注意力的无损记忆。因此Mamba无法展示其在处理短序列方面的优势。然而在涉及长序列时,注意力会由于其二次复杂度而变得不稳定。这种情况下,Mamba可以明显的突出他的效率,因此Mamba特别适合处理长序列。

虽然SSM的循环性质(方程2)使得Mamba可以搞笑的处理长序列,但它引入了一个显著的限制:
h
t
h_t
ht 只能访问上一时间步和当前时间步的信息。如图3所示,这种类型的token混合被称为因果模式,可以表述为:

其中, x t x_t xt 和 y t y_t yt 分别表示第 t t t 个token的输入和输出。由于其因果性质,这种模式非常适合自回归生成任务。
另一种模式称为完全可见模式,其中每个token可以聚合所有前序和后序令牌的信息。这意味着每个输出token取决于所有输入token:

其中, T T T 表示token总数。完全可见模式适用于理解任务,其中所有输入都可以被模型一次性访问。
注意力默认处于完全可见模式,但通过在注意力图中应用因果掩码,注意力很容易转变为因果模式。类RNN模型由于其循环特性,本质上是因果模式。由于这种固有特性,类RNN模型无法转化为完全课件模式。虽然使用双向分支可以近似一个完全可见的模式,但每个分支仍然单独地保持因果关系。因此Mamba由于其循环属性的固有限制,非常适合于需要因果token混合的任务。
综上所述,Mamba非常适合表现出以下特征的任务:
-
特征1:任务涉及处理长序列
-
特征2:任务需要因果token混合模式
4.2 视觉识别任务是否有很长的序列
考虑一个Transformer模块,其公共MLP比例为4;假设其输入
X
∈
R
L
×
D
X∈R^{L×D}
X∈RL×D 的令牌长度为
L
L
L ,通道维数为
D
D
D ,则该块的FLOPs可计算为:

由此,推导出了
L
L
L 的二次项与线性项的比值:

当 L > 6 D L > 6D L>6D 时, L L L 中二次项的计算量超过线性项的计算量。这为判断任务是否涉及长序列提供了一个简单的衡量标准。例如,在ViT - S的384个通道中,阈值 τ s m a l l = 6 × 384 = 2304 \tau_{small} = 6 × 384 = 2304 τsmall=6×384=2304;在ViT - B的768个通道中,阈值 τ b a s e = 6 × 768 = 4608 \tau_{base} = 6 × 768 = 4608 τbase=6×768=4608。
对于ImageNet上的图像分类,典型的输入图像大小为 22 4 2 224^2 2242,产生 1 4 2 = 196 14^2=196 142=196 个 token,块大小为 1 6 2 16^2 162。显然 196远小于 τ s m a l l \tau_{small} τsmall 和 τ b a s e \tau_{base} τbase,这表明ImageNet上的图像分类不适合作为长序列任务。
对于COCO上的目标检测和实例分割,其推理长度为 800 × 1280,对于ADE20K上的语义分割,其推理图像大小为512 × 2048,token数量约为4K,给定块大小为 1 6 2 16^2 162。由于 4 K > τ s m a l l 4K > τ_{small} 4K>τsmall 和 4 K ≈ τ b a s e 4K≈τ_{base} 4K≈τbase,COCO上的检测和ADE20K上的分割都可以被认为是长序列任务。
4.3 视觉任务是否需要因果token混合模式
如图3所示,完全可见的token混合模式允许不受限制的混合范围,而因果模式则限制当前token只能从前一个token中获取信息。视觉识别被归类为理解任务,其中模型可以一次性看到整个图像,从而消除了对标记混合的限制。对token混合施加额外的约束可能会降低模型性能。如图3 ( b )所示,当对ViT施加因果限制时,观察到性能显著下降。 一般而言,完全可见模式适合于理解任务,而因果模式更适合于自回归任务。这一说法也可以通过观察得到证实,BERT和ViT( BEiT 和MAE )比GPT-1/2和图像GPT更多地用于理解任务。因此,视觉识别任务不需要因果标记混合模式。
4.4 关于Mamba对于视觉的必要性假设
基于前面的讨论,作者总结了关于在视觉识别任务中引入Mamba的必要性的假设如下:
-
假设1:不需要在ImageNet上引入SSM进行图像分类,因为该任务不满足特征1或特征2。
-
假设2:尽管这些任务不满足特征2,但仍然值得进一步探索SSM在视觉检测和分割中的潜力,因为这些任务符合特征1。
5 效果
在图像分类上的效果。

在目标检测和实例分割上的效果。

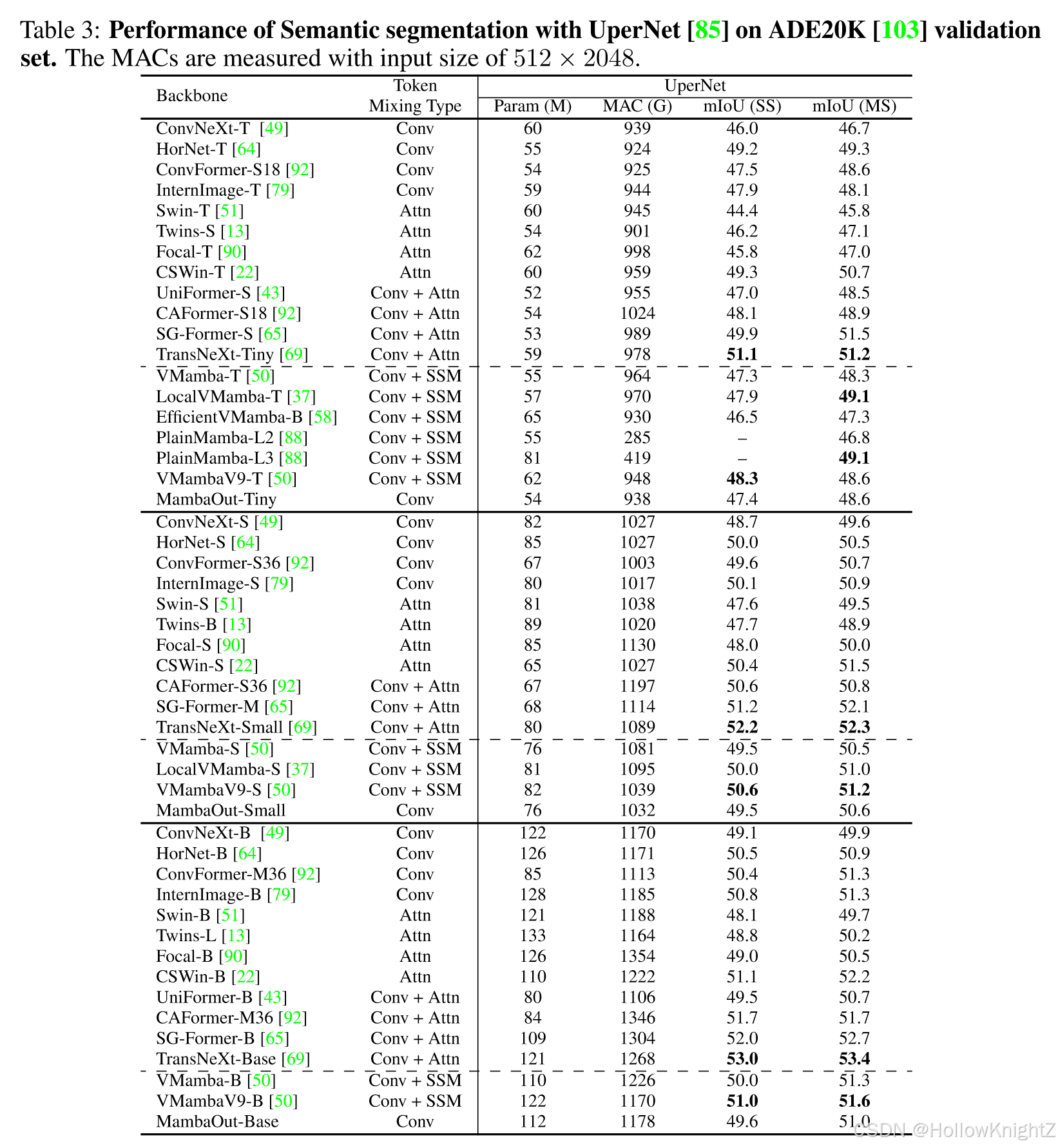
在语义分割上的效果。